

AI for Healthcare: Pt 2, Medical LLMs & AI Research
AI for Healthcare: Pt 2, Medical LLMs & AI Research
AI for healthcare research roundup: Medical LLMs, grounding medical LLMs with RAG and rule alignment, medical datasets, evaluations of LLMs in clinical settings, and ML models for diagnostics.


Introduction
As part of our series on AI for Healthcare, we focus here on AI research in medical applications and healthcare. This follows up on our previous article “AI for Healthcare: Pt 1, The Rise of AI.” This article will serve also as our AI Research Roundup for this week.
We will cover these topics:
A survey on transformers and LLMs in healthcare
General LLMs and medical LLMs for medical tasks
Med PaLM 2, BioMistral, MedPrompt, o1 in medicine
Improving medical grounding with context, RAG, and rule alignment
OpenMedPrompt, i-MedRAG, RuleAlign
Medical Datasets for AI
MedTrinity-25M, Kvasir-VQA
Evaluating LLMs in Clinical Applications
MEDIC, MedExpQA
AI Models for Clinical Decisions and Diagnosis
RECOMED and ABiMed, clinical decision support system for medications
ML-based System for Detecting Acute Myeloid Leukemia
Multimodal ML model for Early Detection of Alzheimer's Disease
A survey on transformers and LLMs in healthcare
The Journal “Artificial Intelligence in Medicine” is dedicated to studies in AI for healthcare. They published a recent survey, titled Transformers and large language models in healthcare: A review that reviewed almost 300 papers on the topic, highlighting the broad applications of transformers and LLMs in healthcare.
The survey outlined uses of transformer-based LLMs and models across several data types and many medical tasks:
LLMs, used for text-based tasks such as Clinical QA, summarization, procedure coding, and diagnostics.
Vision transformers (ViTs), used in medical imaging tasks, such as medical image segmentation, synthesis, and diagnostics, as well as visual QA.
Biomarker and signal-based analytics, such as from ECG (electrocardiogram), in which a transformer model interprets the time-series ECG signal.
Transformers that encode protein or gene sequences can model drug or protein interactions, predict gene sequence alignment, and can be solve various drug or protein design problems.
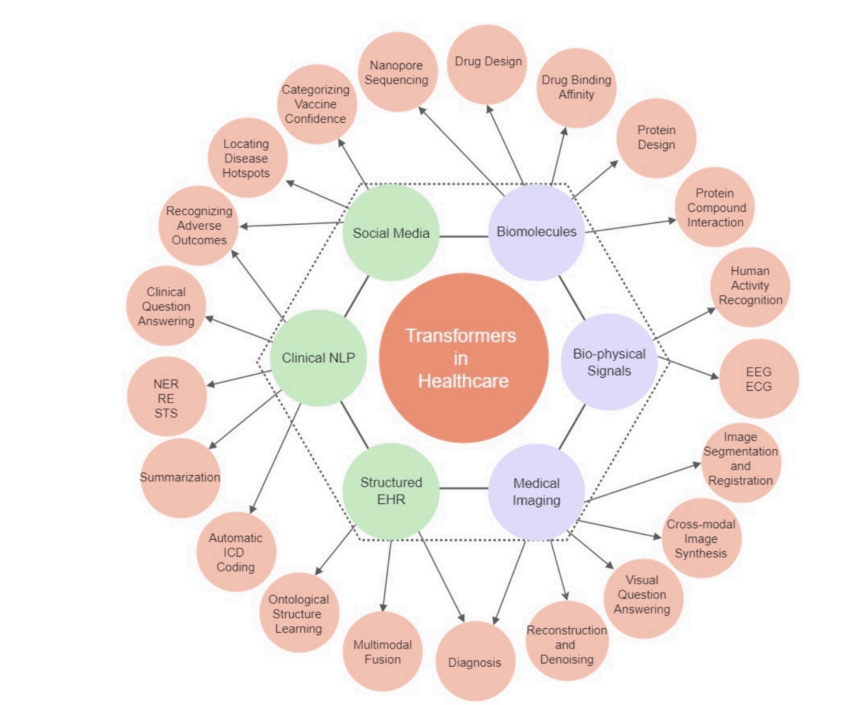
The survey shows hundreds of varied transformer-based AI models used in specific medical and healthcare applications. While transformers encompass more than LLMs, for example tailored AI models for ECG reading or protein design, LLMs constitute the most significant type of AI model for medical uses, covering a broad and growing range of applications as LLMs improve.
How well can an LLM perform on medical tasks?
This question motivated Google in developing and releasing their Med-PaLM and Med-PaLM 2 LLMs, trained dedicated to medical domain. Med-PaLM was the first LLM to achieve a passing grade on the Medical Licensing Examination (USMLE), with a passing grade of 67%, while Med-PaLM 2 achieved 85%, which remains near state-of-the-art.
The paper BioMistral: A Collection of Open-Source Pretrained Large Language Models for Medical Domains introduced BioMistral 7B, an open-source LLM based on Mistral 7B and further pre-trained on PubMed Central data for biomedical uses. BioMistral did improve on Mistral 7B, with a version that got 51% on MedQA, an improvement but far from SOTA.
The paper Assessing the Potential of Mid-Sized Language Models for Clinical QA further examined fine-tuning open LLMs for medical understanding. They fine-tuned Mistral 7B with MedMCQA data and achieved 63% on MedQA. The author note that these results could be improved upon:
There are multiple avenues to improving sub10B parameter model performance on MedQA, including continued pretraining of the model on biomedical text, increasing model size, utilizing retrieval augmented generation, utilizing chain of thought, and distillation of frontier models.
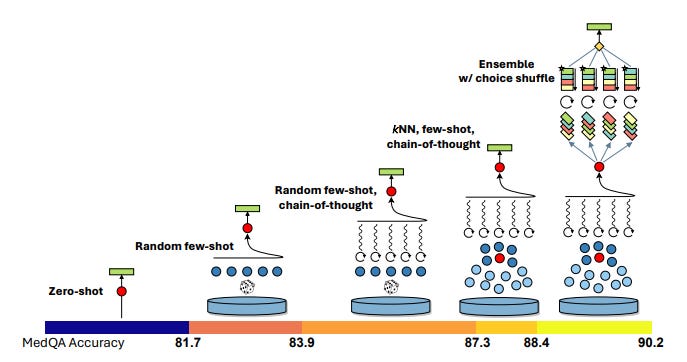
Is a general-purpose foundation LLM better than a fine-tuned medical LLM for medicine? To answer this, researchers at Microsoft developed Medprompt, built on GPT-4 and based on a composition of several prompting strategies. The prompting strategy combines kNN-based few-shot example selection with a medical version of “Let’s think step-by-step” and ensemble of final choice.
Putting these together, the Medprompt version of GPT-4 achieves state-of-the-art results on the MultiMedQA suite, with a 90.2% on MedQA:
Steering GPT-4 with Medprompt achieves a 27% reduction in error rate on the MedQA dataset.
On the reasoning front, the latest higher-level reasoning model o1 was assessed in the paper A Preliminary Study of o1 in Medicine: Are We Closer to an AI Doctor? They evaluated o1 across a number of medical evaluation benchmarks and found o1 showed superior reasoning to GPT-4 on complex clinical scenarios. Specifically, o1 improved over GPT-4 by an average of 6.2% and 6.6% across 19 datasets and two newly created complex QA scenarios; o1 scored 87.6% on MedQA.
The takeaway: Fine-tuning of foundation AI models on medical information can boost LLM performance for medical tasks. However, enhanced reasoning and prompting techniques are just as, if not more, effective.
Improving medical grounding with context, RAG, and rules
Another takeaway from analyzing medical LLMs is that problems remain in their hallucination. To make medical LLMs more reliable, they must be grounded in medical knowledge, for example, with retrieval-augmented generation (RAG) on medical knowledge.
The recent paper Boosting Healthcare LLMs Through Retrieved Context explored context retrieval methods within the healthcare domain, including using methods based on MedPrompt. They found in their comparisons that “an optimized retrieval system, can achieve performance comparable to the biggest private solutions on established healthcare benchmarks,” but they also found limitations; methods that score well on tests might still fail in real-world clinical tasks.
To address these findings, they proposed OpenMedPrompt, an optimized retrieval system that improves the generation of more reliable open-ended answers. This AI system combines elements for better reasoning (CoT, ToT, Reflection) and knowledge retrieval (relevant QA pairs added to context).
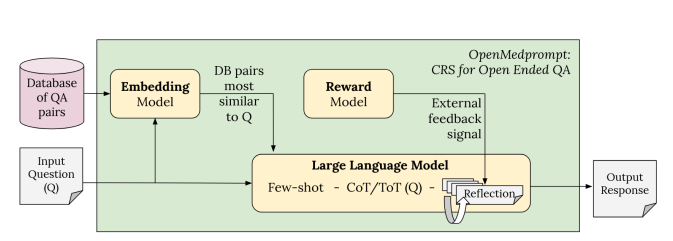
LLMs need to apply relevant medical knowledge in context to successfully answer clinical queries, such as diagnosis from an input of symptoms. Retrieval-augmented generation (RAG) on medical information is the most direct way to bring needed knowledge to bear to enhance LLM factuality and reliability.
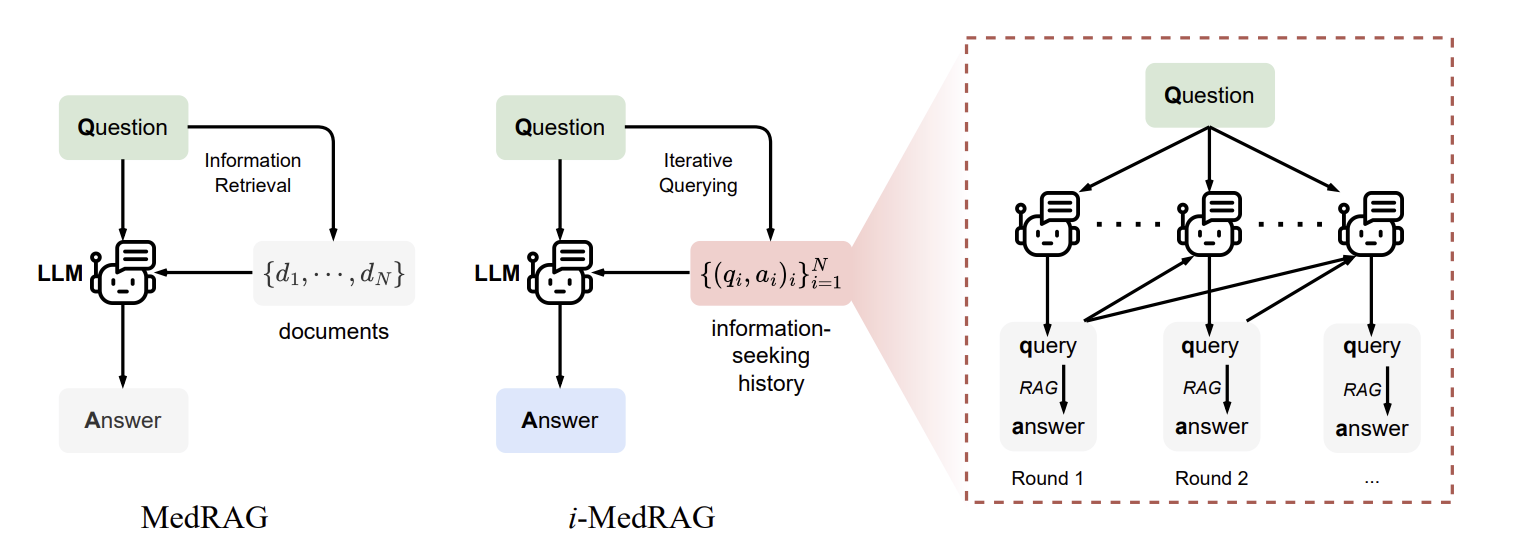
To that end, the paper Improving Retrieval-Augmented Generation in Medicine with Iterative Follow-up Questions developed a specific iterative RAG for medicine (i-MedRAG), where LLMs can iteratively ask follow-up queries based on previous information-seeking attempts. This method boosted results beyond prior prompt engineering and fine-tuning methods; for example, i-MedRAG on Llama-3.1 8B obtained 75% on MedQA.
The paper Enhancing Healthcare through Large Language Models: A Study on Medical Question Answering evaluated combined LLM configurations in processing clinical question-answering. They found that, of the configurations they evaluated, pre-processing clinical questions with the Sentence-t5 language model combined with Mistral 7B LLM demonstrated the best performance. This suggests that integrating multiple LLMs, advanced pretraining techniques, and best prompt construction.
Even advanced medical LLMs that score highly on medical benchmarks face challenges in making diagnoses akin to doctors. The paper RuleAlign: Making Large Language Models Better Physicians with Diagnostic Rule Alignment introduced the RuleAlign framework, designed to align LLMs with specific diagnostic rules used by physicians in their work. They developed a medical dialogue dataset comprising rule-based communications between patients and physicians to train this framework.
Medical Datasets: MedTrinity-25M and Kvasir-VQA
One challenge to AI models for medical applications is suitable data. Labelled or at least annotated data is needed for clinical decision-making. A specific annotated dataset example is presented in Kvasir-VQA: A Text-Image Pair GI Tract Dataset. The Kvasir-VQA dataset comprises 6,500 annotated images spanning various GI tract conditions and surgical instruments.
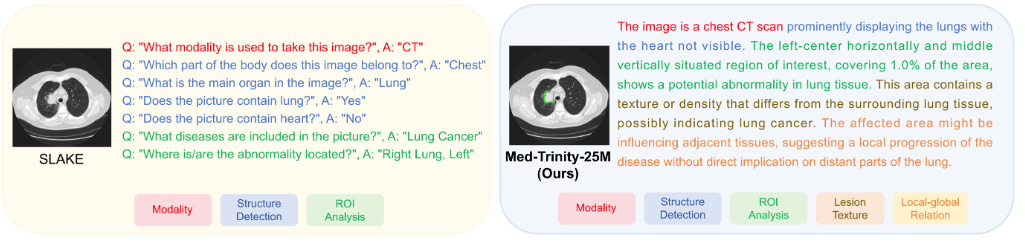
To scale medical data for use across data types and disease conditions, more automated collection and annotation is needed. The recent paper MedTrinity-25M: A Large-scale Multimodal Dataset with Multigranular Annotations for Medicine presents MedTrinity-25M, a comprehensive medical dataset that comprises over 25 million images across 10 modalities, with multigranular annotations for more than 65 diseases.
To scale up this dataset, they created an automated pipeline for annotations, which used expert systems and LLMs to generate visual and textual annotations from multimodal data. As a result:
“MedTrinity-25M provides the most enriched annotations, supporting a comprehensive range of multimodal tasks such as captioning and report generation, as well as vision-centric tasks like classification and segmentation.”
Evaluating LLMs in Clinical Applications: MEDIC and MedExpQA
Traditional benchmarks for medical LLMs such as MedQA, based on medical licensing exams, do not sufficiently reflect real-world performance on medical tasks.
The paper MEDIC: Towards a Comprehensive Framework for Evaluating LLMs in Clinical Applications addresses this gap with MEDIC, a comprehensive framework for evaluating LLMs in clinical applications.
MEDIC evaluates LLMs across five critical dimensions: medical reasoning, ethics and bias, data and language understanding, in-context learning, and clinical safety. … MEDIC features a novel cross-examination framework quantifying LLM performance across areas like coverage and hallucination detection, without requiring reference outputs.
The MedExpQA benchmark, released and presented in MedExpQA: Multilingual benchmarking of Large Language Models for Medical Question Answering, innovates in two ways: It is a multilingual benchmark for MedicalQA, and it includes gold reference explanations, written by medical doctors, of the correct and incorrect options in the exams.
AI Models for Decision Support and Diagnosis
When there is sufficient patient data to train the model, machine-learning (ML) models are well-suited in classifying conditions based on analyzing many variables and detecting subtle differences across biomarkers and datasets. Thus, most AI systems in diagnostics and clinical decision support are currently based on ML classifier models.
RECOMED is a comprehensive pharmaceutical recommendation system, built on a deep learning model developed from patient outcome data and a drug information knowledge base. The RECOMED knowledge-based recommendation system can recommend an acceptable combination of medicines with improved accuracy, sensitivity, and hit rate.
A new study revealed that ABiMed, a medication decision-making tool, significantly improved medication reviews by pharmacists. The paper, A randomized simulation trial evaluating ABiMed, a clinical decision support system for medication reviews and polypharmacy management, evaluated ABiMed with a randomized simulation trial with community pharmacists. With ABiMed, pharmacists spotted 1.6 times more drug-related issues and made better recommendations without working longer hours.
Another example is the recent paper Clinical Validation of a Real-Time Machine Learning-based System for the Detection of Acute Myeloid Leukemia by Flow Cytometry, which presents an AI model to detect Acute Myeloid Leukemia and analyzes its deployment and clinical use.
The exciting paper Toward Robust Early Detection of Alzheimer's Disease via an Integrated Multimodal Learning Approach tackles Alzheimer's Disease (AD), a complex neurodegenerative disease where early diagnosis is difficult:
This study introduces an advanced multimodal classification model that integrates clinical, cognitive, neuroimaging, and EEG data to enhance diagnostic accuracy. …. By employing Cross-modal Attention Aggregation module, the model effectively fuses Magnetic Resonance Imaging (MRI) spatial information with EEG temporal data, significantly improving the distinction between AD, Mild Cognitive Impairment, and Normal Cognition.
Thus, by incorporating numerous biomarkers of different modalities, the authors developed a more accurate diagnosis model that could detect Alzheimer’s earlier than previously possible.
Developing ML-based models for diagnosis of AD is a promising and active area of research. Other serious and chronic diseases can benefit from a similar approach.
Conclusion
AI applied to healthcare has the promise to make our lives significantly better. AI can support more accurate and effective clinical decisions and healthcare communications. Multi-modal AI models that glean insights from complex, multi-modal datasets can diagnose disease more precisely. AI can help deliver higher-quality data-driven personalized medicine efficiently.
However, we are not there yet. The authors of the survey on transformers in healthcare note that despite LLMs scoring highly on MedQA benchmarks and passing the Medical Licensing Examination (USMLE), the path to LLM adoption in medicine is slow:
The impressive advancements of foundation models have not yet permeated into medical AI. These early approaches are limited by a lack of large, diverse medical datasets, the complex nature of medical data, federal patient data privacy regulations, and the recency of the general-purpose foundation models.
AI model developers and medical researchers are overcoming technical challenges rapidly. Non-technical hurdles, such as regulations and organizational inertia, are another matter.