
AI models unleashed! Llama 3 launches!
New AI models: Meta's Llama 3 8B & Llama 3 70B, Reka Core, Mistral's Mixtral 8x22B


Summary
TL;DR - The AI models keep coming, with these new AI models released this week:
LLama3
Meta has introduced Meta Llama 3 as an open weights AI model, making it in Meta’s own words “The most capable openly available LLM to date.”
Llama 3 8B and 70B both are the most capable current AI models for their size: Llama 3 8B instruct surpasses Mistral 7B instruct, other 7B AI models, and even Llama 2 70B, on MMLU (score of 68.4) and HumanEval (score of 62.2). The new Llama 3 70B is on par with Claude 3 Sonnet and Gemini 1.5 Pro; it matches them on MMLU (82.0) and GSM-8K (93.0) and beats them both in HumanEval (81.7).
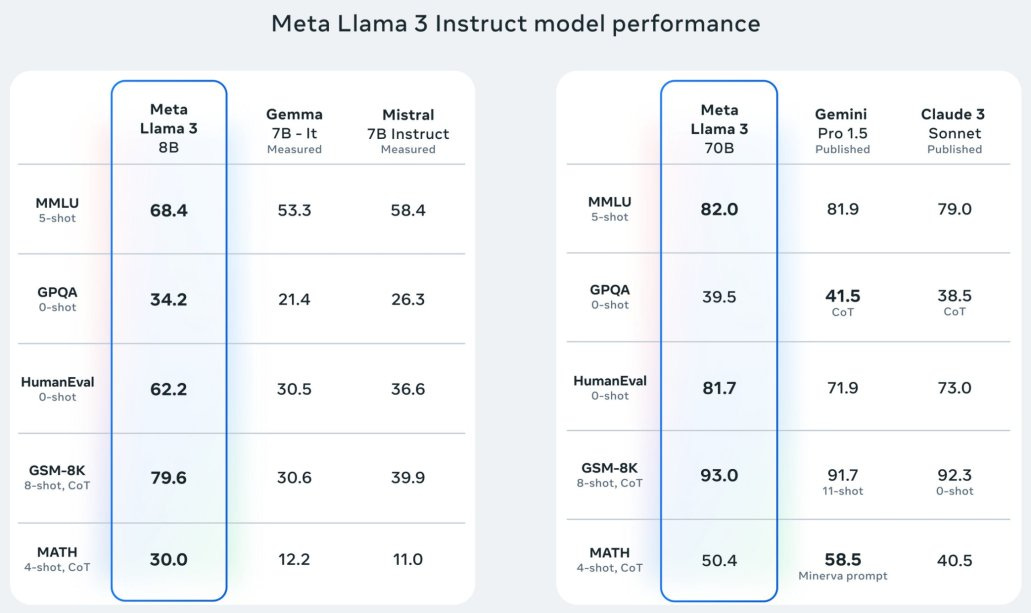
Some limitations of Llama 3. It’s a pure LLM with no multi-modal features, and it has a context window of 8K, quite limited compared to other frontier AI models.
Some key info and data on Llama 3’s training and architecture from the Llama 3 model card and Meta’s blog post introducing Llama3:
Pre-training compute used: Llama3 was trained on 7.7M GPU hours of H100s, using Meta’s two recently announced custom-built 24K GPU clusters. They achieved a top 400 TFLOPS per GPU compute utilization, and overall managed be three times more efficient at training than with Llama 2. Meta’s huge GPU clusters helped them train these models quickly.
LLama 3 8B and 70B were both trained on over 15T tokens of data – a training dataset 7x larger than that used for Llama 2, including 4x more code. This is a remarkable trend:
“ … while the Chinchilla-optimal amount of training compute for an 8B parameter model corresponds to ~200B tokens, we found that model performance continues to improve even after the model is trained on two orders of magnitude more data. Both our 8B and 70B parameter models continued to improve log-linearly after we trained them on up to 15T tokens.”
Llama 3 uses a large 128K vocabulary tokenizer (tik-token) that encodes language much more efficiently and improves model performance.
They are still training their largest Lllama 3 LLM, a 400B+ parameter model, and it looks to be world-class on benchmarks.

To address trust and safety concerns, Meta updated their Responsible Use Guide (RUG) and released Llama Guard 2, an 8B parameter Llama 3-based LLM safeguard model. Similar to Llama Guard, Llama Guard 2 indicates whether a given LLM prompt or responses is safe or unsafe, and if so, what policies it violates.
These Llama 3 models are already available on a number of cloud services, such as Azure, and the Replicate pricing chart show Llama3-70B model costs just $0.65/1M tokens input, $2.75/ 1M tokens, one-tenth the cost-per-token of GPT-4 turbo on OpenAI’s API. Llama3-8B model is a tenth of that, just $0.05/1M tokens input, $0.25 tokens output.
As an open weights model, you can download Llama3 directly to run it locally. Nous Research has 4-bit quantized versions of the 8B Llama3 that can also be downloaded and run locally.
Meta.AI and social-media-feed AI is a Big Deal
Meta also launched Meta AI, a new AI Assistant built with Llama 3; you can access Llama3 through Meta AI’s chatbot interface available here.
Meta.AI has nice chatbot features with capable Llama 3 doing the AI work. It hooks up to Bing search to give you sourced answers for current topical queries, similar to Bing Chat / CoPilot; you can generate images (see our cover art) in Meta.AI.
Beyond that, they are inserting their AI assistant across their social media platforms:
You can use Meta AI in feed, chats, search and more across our apps to get things done and access real-time information, without having to leave the app you’re using.
Why it’s a big deal: With their social media sites, Meta has a channel to an audience in the billions. By sprinkling AI in user’s feeds, Meta is using AI as a feature to keep people on their social media platforms. As a result, they are exposing billions to AI, and could quickly become a major channel for consumer use of AI.
Reka Core
On April 15th, Reka launched Reka Core, a new multimodal LLM that can handle text, image, audio, and video inputs. Reka Core is their biggest AI model release that compliments their smaller Reka Flash (21B) and Reka Edge (7B) multi-modal LLMs that Reka released earlier. Reka is partnering with Oracle to host their AI models.
Reka Core is a high-performing frontier AI model for multi-modality: It outperforms Claude 3 Opus in multimodal human evals, Gemini Ultra in video, and was competitive with GPT-4 on image understanding.
Reka shared a technical report, “Reka Core, Flash, and Edge: A Series of Powerful Multimodal Language Models,” that describes in detail their models’ performance. However, Reka released these as proprietary AI models, and their report doesn’t many details about the training dataset, process, or model architecture.
They are leaning in on the multi-modal features of their model, as they show in their benchmark comparisons, which includes multi-modal tests such as MMMU, VQA, where it is competitive with GPT-4 and Gemini Ultra. On those, Reka Core is a best-in-class contender, although Grok-1.5 vision is very strong in this space as well.
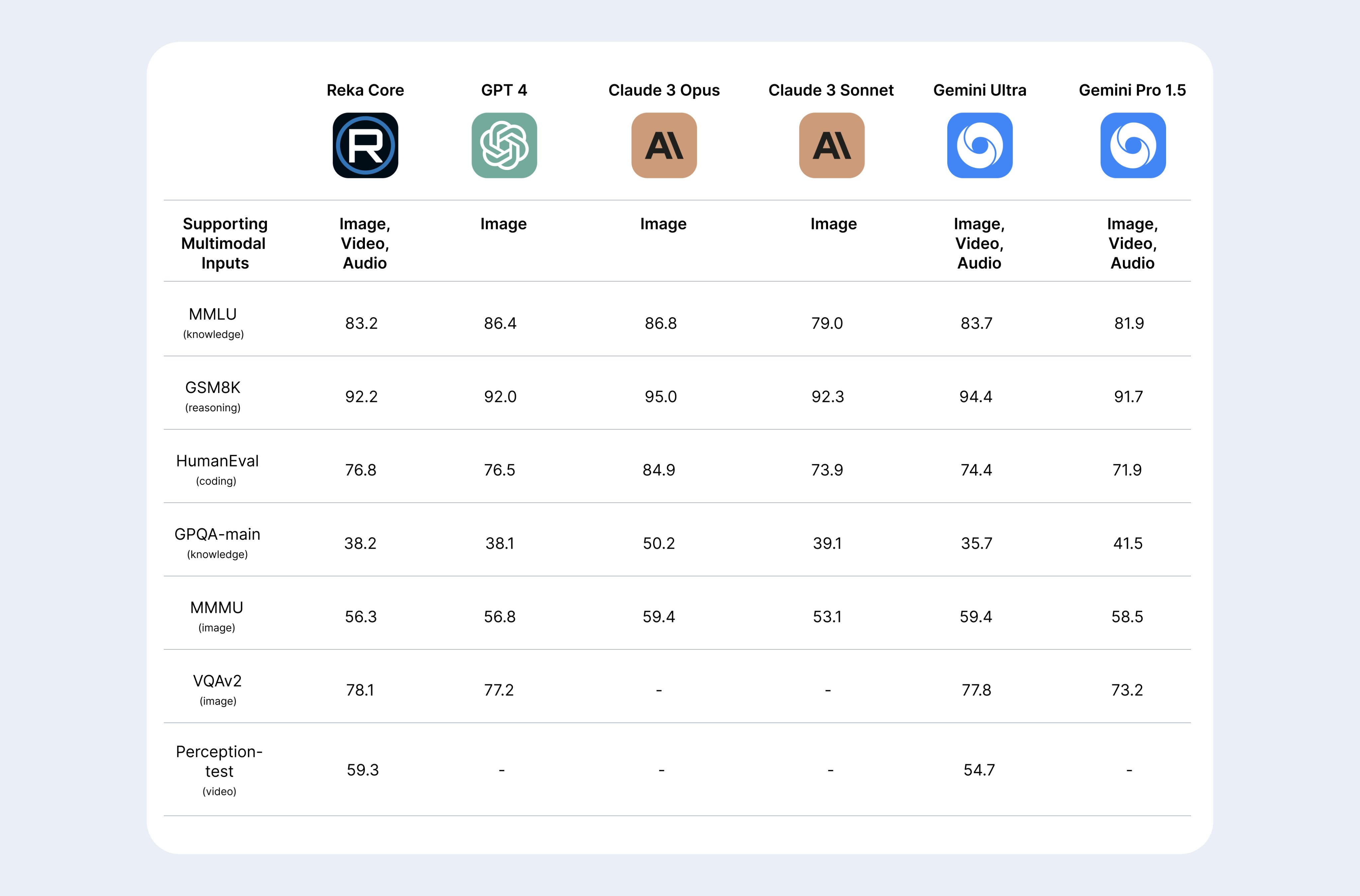
More remarkable, Reka is a 20-person AI startup that got $60 million in funding last summer. They noted in their report that more than 90% of their compute (2.5K H100s and 2.5K A100s) came online in mid-December 2023. They had a late start, but created very solid AI models in just a few months.
Co-founder Yi Tay describes Reka’s ML engineering and infrastructure challenges journey to train their AI models in a blog post: Training great LLMs entirely from ground up in the wilderness as a startup.
Mixtral 8x22B gets officially launched
Mistral made a more official announcement of their big Mixtral 8x22B model, releasing their Instruct model and making it available on their LeChat interface and LePlatforme APIs. Some highlights of Mixtral 8x22B:
Good on multi-lingual European languages (like all Mistral AI models).
Natively capable of function calling, which is an important feature for embedded application and AI Agent development.
64K tokens context window.
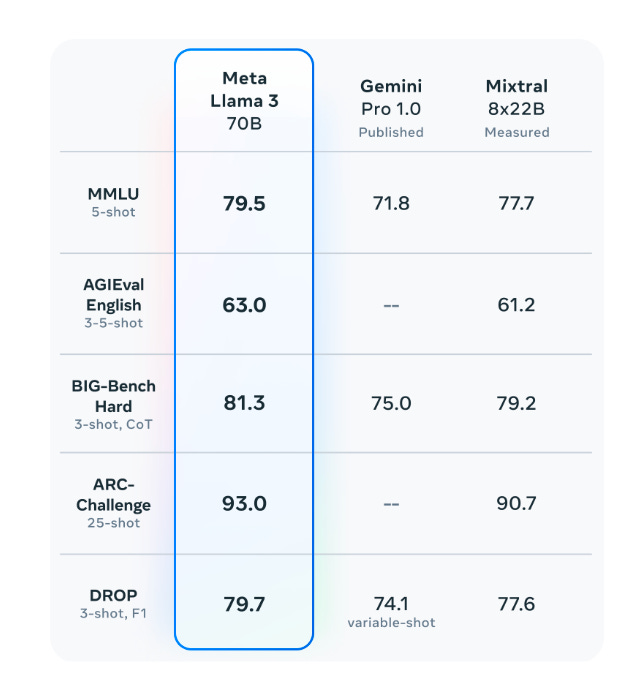
How does Mixtral 8x22B performance stack up? Last week, we could describe Mixtral 8x22B as the best open LLM; with an MMLU of 77.7, it was great but its reign was short-lived. Llama 3 70B stole the crown, edging it out on benchmarks.
WizardLM-2
This week, WizardLM-2 was released and then withdrawn: “We accidentally missed an item required in the model release process - toxicity testing.” They will re-release it soon. It’s apparently a solid model, but we’ll await a real successful release to assess it.
Conclusion
Some have speculated that the spate of AI model releases for the past few weeks was from AI model companies trying to get out ahead of Llama 3. We can see why. Meta’s Llama 3 8B and 70B are fantastically good AI models, even though they are just 8K context small sized LLMs.
The secret was simple and no real secret: Train on it longer with more data; in Llama 3’s case, 15 trillion tokens of data did the trick.
There is another reason for the flood of new AI models lately, hinted at by Reka’s statement of not getting their H100s until December 2023. Many companies lacked the GPUs to train AI models quickly; demand for H100s was backlogged. All those H100s that NVidia sold in 2023 have been turned into AI models in 2024.
The AI model flood will continue. Meta will release Llama 3 400B+ in coming months. Gemini 1.5 is on deck. More to come.
If Meta applied the same data-to-parameter ratio used to train the Llama 3 8B model, 2,000 (15T tokens/ 8B parameters), then they could train a 400B+ model on a stunning 800 T tokens. Worth it? Does such data even exist? Could they afford the compute cost?
Are we hitting a GPT-4 ‘plateau’ because the insatiable training data and compute needed to push further is out of reach? Meta says the improvement is ‘log-linear’ which another way to say you need to scale training compute exponentially to get linear performance gains.
Only those with huge amounts of compute can go to the next level, beyond GPT-4 level AI models. Meta used a stunning 48K H100 GPUs to train Llama 3. They have the resources to afford to train harder and longer than practically any other company, except perhaps Google and OpenAI.
Your move, Google. Your move, OpenAI.