
AI Research Review 24.06.13: Benchmarks
Recent progress in AI model benchmarks: ML-Agent-Bench, LiveBench, MMLU-Redux, McEval for coding, CS-Bench for CS, WildBench, Test of Time - temporal reasoning.


Introduction
Our AI research highlights for this week will focus on benchmarks. We need benchmarks in AI so we can quantitatively grasp where we are. Because AI is evolving so rapidly, benchmarks need to evolve with them. LLM benchmarking is further challenged by the data contamination problem, where benchmark questions find themselves in LLM pre-training datasets.
For all these reasons, improving AI model benchmarks is an active area of AI research. This week, there’s been two recent announcements of benchmarks:
ML-Agent-Bench, an update of ML-Bench for AI agent benchmarking
LiveBench: A Challenging, Contamination-Free LLM Benchmark
There was also a recent LatentSpace podcast on ICLR 2024 that including coverage of ICLR papers on AI benchmark. They highlighted two papers and an invited talk:
An invited ICLR talk on “The emerging science of benchmarks” by Moritz Hardt; he gives a high-level perspective on benchmarks and why they work.
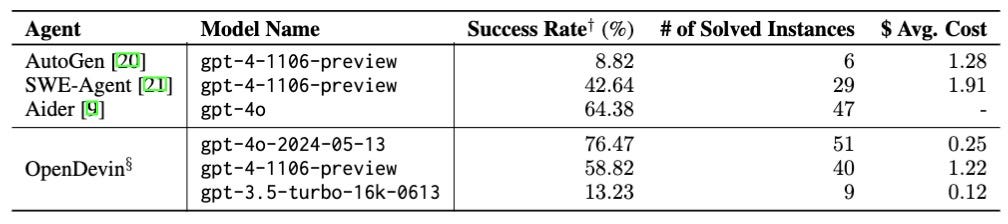
SWE-bench, described in “SWE-bench: Can Language Models Resolve Real-World GitHub Issues?” SWE-bench has become the go-to benchmark to evaluate AI coding agents such as Devin, OpenDevin, SWE-Agent, and Aider.
GAIA, a benchmark for General AI Assistants, proposes real-world questions based on fundamental abilities such as reasoning, multi-modality handling, web browsing, and tool-use proficiency. Think of it like a real-world AGI test. GAIA questions are conceptually simple for humans yet challenging for most advanced AIs, with authors showing “human respondents obtain 92% versus 15% for GPT-4 equipped with plugins.”
Several new AI benchmark-related papers came out on Arxiv in this past week:
MMLU-Redux: Are We Done with MMLU?
McEval: Massively Multilingual Code Evaluation
CS-Bench: A Comprehensive LLM Benchmark for Computer Science Mastery
WildBench: Benchmarking LLMs with Challenging Real-World Tasks
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
We will share further details on these new benchmark results and papers below.
When you can measure what you are speaking about, and express it in numbers, you know something about it; but when you cannot measure it, when you cannot express it in numbers, your knowledge is of a meagre and unsatisfactory kind: it may be the beginning of knowledge, but you have scarcely, in your thoughts, advanced to the stage of science, whatever the matter may be. - Lord Kelvin
ML Agent Bench
The makers of ML-Bench just announced ML-Agent-Bench, an AI agent benchmark based on a revamped ML-Bench. They extended it to cover AI agent performance.
The ML-Bench benchmark, presented in the paper “ML-Bench: Evaluating Large Language Models and Agents for Machine Learning Tasks on Repository-Level Code,” is designed evaluate LLMs for real-world coding applications, where LLMs need to understand and execute repository-level code.
LLMs like GPT-4 excel in function-level code generation, but they struggle with processing long contexts of complex file interactions. However, within an agent framework like OpenDevin, GPT-4o demonstrates decent performance in such complex task resolution. ML-Agent-Bench is designed to evaluate that agentic approach to complex coding tasks.
To evaluate both LLMs and AI agents, two setups are employed:
ML-LLM-Bench for assessing LLMs' text-to-code conversion within a predefined deployment environment, and
ML-Agent-Bench for testing autonomous agents in an end-to-end task execution within a Linux sandbox environment.
They manually curated their dataset, enlisting numerous students for task annotation. The resulting benchmark data set was “9,641 examples across 18 GitHub repositories.”

Benchmark results shows:
In the more demanding ML-Agent-Bench, GPT-4o achieves a 76.47% success rate, reflecting the efficacy of iterative action and feedback in complex task resolution.
LiveBench: A Challenging, Contamination-Free LLM Benchmark
Abacus AI partnered with Yann LeCunn and his team to create LiveBench AI, a living benchmark with novel challenges designed to address the problems of benchmark test set contamination and biases from LLM-generated questions and assessments. Bindu Reddy announced LiveBench AI on X as “The WORLD'S FIRST LLM Benchmark That Can't Be Gamed!”
As they explain in their paper “LiveBench: A Challenging, Contamination-Free LLM Benchmark,” LiveBench avoids test set contamination and the pitfalls of LLM judging and human crowdsourcing in these ways: To do this:
Livebench contains frequently updated questions from recent information sources, such as math competitions, arXiv papers, news articles, and datasets; new tasks and questions will be added and updated on a monthly basis.
Livebench scores answers automatically according to objective ground-truth values;
Livebench contains a wide variety of challenging tasks, spanning math, coding, reasoning, language, instruction following, and data analysis; LiveBench is difficult, with top current models (GPT-4o) achieving below 60% accuracy.
They evaluated a number of closed-source and open-source LLMs on LiveBench, which confirmed GPT-4o as the leading LLM, followed by Claude 3 Opus and Gemini 1.5 pro. They released all benchmark data and code on HuggingFace and Github, and have a leaderboard, and have links to everything on LiveBench.ai.

MMLU-Redux: Are We Done with MMLU?
Despite being the most widely-used benchmark for LLMs, MMLU has problems: Vague questions, ground truth errors, and more. The authors of Are We Done with MMLU? found that 57% of the analyzed questions in the Virology subset contain errors. Several MMLU subjects have over 10% error rates in questions and answers.

Rather than toss out MMLU, the authors decided to find and fix errors, creating a revamped MMLU called MMLU-Redux, which developed a subset of 3,000 manually re-annotated questions across 30 MMLU subjects.
This revamped MMLU showed there were “significant discrepancies with the model performance metrics that were originally reported.” Models like Claude 3 Opus, GPT-4o and Gemini 1.5 Pro did better than reported on Virology, Business Ethics and other MMLU topics.
So the authors advocate not to abandon MMLU, but to revise it with MMLU-Redux corrections, so it’s a reliable benchmark for evaluating LLMs.
Our results strongly advocate for revising MMLU's error-ridden questions to enhance its future utility and reliability as a benchmark. “ - From “Are We Done with MMLU?”
McEval: Massively Multilingual Code Evaluation
Most existing LLM coding benchmarks,such as HumanEval, primarily focus on a limited number of languages, such as Python. The paper McEval: Massively Multilingual Code Evaluation proposes a more wide-ranging coding benchmark:
To further facilitate the research of code LLMs, we propose a massively multilingual code benchmark covering 40 programming languages - McEval - with 16K test samples, which substantially pushes the limits of code LLMs in multilingual scenarios. The benchmark contains challenging code completion, understanding, and generation evaluation tasks with finely curated massively multilingual instruction corpora McEval-Instruct.

The rich set of 16K test samples give McEval the ability to assess AI coding models with granular detail. The results showed outperformance of GPT-4o and GPT-4 Turbo relative to some of the coding specific models like DeepSeek Coder and CodeQwen 1.5 across different languages, paradigms, and application types.

The instruction corpora, evaluation benchmark, and leaderboard are available at the McEval website.
CS-Bench: A Comprehensive LLM Benchmark for Computer Science Mastery
As explained in “CS-Bench: A Comprehensive Benchmark for Large Language Models towards Computer Science Mastery,”CS-Bench addresses a gap in AI model benchmarks: All-around evaluation of computer science knowledge and skills. While related to both programming capabilities and math reasoning, this is distinct from both.
CS-Bench is the first bilingual (Chinese-English) benchmark dedicated to evaluating the performance of LLMs in computer science:
CS-Bench comprises approximately 5K meticulously curated test samples, covering 26 subfields across 4 key areas of computer science, encompassing various task forms and divisions of knowledge and reasoning.
They evaluated over 30 LLMs on CS-Bench, revealing the relationship between CS performance and model scaling, as well as a high correlation between LLMs' capabilities in computer science and their abilities in mathematics and coding. Being bilingual, they were able to test Chinese AI models; Ernie4 was just behind GPT-4 on CS-Bench Chinese.
Their leaderboard is on their CS-Bench project website, and CS-Bench data and evaluation code are available at the CS-Bench Github page.
WildBench: Benchmarking LLMs with Challenging Real-World Tasks
WildBench is described in the paper “WildBench: Benchmarking LLMs with Challenging Tasks from Real Users in the Wild” as an automated evaluation framework designed to benchmark large language models (LLMs) using challenging, real-world user queries:
WildBench takes a set of curated real-world tasks, “1,024 tasks carefully selected from over one million human-chatbot conversation logs.” It evaluates model outputs with task-specific checklists and structured explanations that justify scores.
To automate evaluation with WildBench, they developed WB-Reward, to pairwise compare model responses and WB-Score, to evaluate model outputs individually and directly. They compute these with advanced LLMs such as GPT-4-turbo.

Benchmark results on WildBench show strong correlation (0.98) with the human-voted Elo ratings from Chatbot Arena on hard tasks. WB-Reward and WB-Score ratings correlate highly with other benchmarks, such as ArenaHard (0.91) and AlpacaEval2.0 (0.89).
More important than the WildBench benchmark itself, the automated process to turn real-world tasks into benchmarking test-cases is a powerful and general concept for benchmark development.
Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning
Temporal reasoning is a special kind of reasoning that humans naturally acquire but which often eludes AI models. The paper “Test of Time: A Benchmark for Evaluating LLMs on Temporal Reasoning” introduces specially designed synthetic datasets to assess LLM temporal reasoning abilities in AI models:
The diversity of question types across these datasets enables systematic investigation into the impact of the problem structure, size, question type, fact order, and other factors on LLM performance.

The datasets and evaluation framework are open-source and shared on HuggingFace.