


AI Research Roundup 24.04.13
AutoCodeRover, Mini-CPM, LLM2Vec, ChatGLM-Math, OpenEQA, Zero shot needs exponential data, better LLM reasoning with pseudocode compilers, and defining the intelligence in AI.


Introduction
It’s been a busy week on all fronts of AI. Here are our AI research highlights for this past week:
AutoCodeRover is a New SOTA Coding Agent - 22% on SWE-Bench-lite
Zero-shot Requires Exponential Data - Scaling is log-linear
Defining intelligence across human and artificial
MiniCPM: Small Language Models with Scalable Training Strategies
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Better Reasoning Using LLMs as Pseudocode Compilers
ChatGLM-Math Improves LLM Problem-Solving with Self-Critique
OpenEQA: Embodied Question Answering
AutoCodeRover is a New SOTA Coding Agent
AutoCodeRover is the new coding agent champion! It gets SOTA results (22%) on SWE-Bench lite, beating both Devin and SWE-Agent on SWE-bench benchmarks. The paper “AutoCodeRover: Autonomous Program Improvement”, from National University of Singapore, explains their approach. Even better, it’s open source and they’ve shared their code and collateral.

Software engineering is the work of developing and maintaining software, and it often goes beyond code generation. AutoCodeRover presents an automated approach to solving Github issues: Code search to find root causes; code understanding and code updates in the context of a project understood as a representation, not just a collection of files; testing to localize faults and verify corrections.

The AutoCodeRover authors declare “this workflow enables autonomous software engineering” and validate it with state-of-the-art SWE-bench-lite benchmarking results of 22%. (SWE-bench consists of 300 real-life Github issues involving bug fixing and feature additions.) Expect more activity in AI Agents for software engineering; it’s highly valuable to automate, and we are far from solving it fully.
Zero-shot Requires Exponential Data
One recent study from researchers at Cambridge, Oxford, Google Deepmind, and the University of Tübingen found that as AI models grow, they require exponential amounts of data to achieve just linear downstream performance results — possibly limiting how much we can scale AI model performance.
Their paper is called “No “Zero-Shot” Without Exponential Data: Pretraining Concept Frequency Determines Multimodal Model Performance.” Looking at multi-modal AI models that generate images, such as CLIP, they ask the question: How is the performance of multimodal models on downstream concepts influenced by the frequency of these concepts in their pretraining datasets?
They answer, unsurprisingly, is that more data is better, but the surprise is the amount of data needed - exponential:
We consistently find that, far from exhibiting “zero-shot” generalization, multimodal models require exponentially more data to achieve linear improvements in downstream “zero-shot” performance, following a sample inefficient log-linear scaling trend. This trend persists even when controlling for sample-level similarity between pretraining and downstream datasets, and testing on purely synthetic data distributions.
The bottom-line is that models scale on data at a log-linear rate, and perform poorly on “long-tailed data” with few samples in the training dataset; we need better “sample-efficient learning on the long-tail.”
Is ‘zero-shot’ a parlor trick? No, but if you need a lot of data to make it happen, it suggests limits to performance. This study was done on image AI models, but it raises questions about scalability of other models, including LLMs.
Defining intelligence across human and artificial
When Sam Altman says GPT-5 will be “smarter” what does that mean? Defining AI, AGI (Artificial General Intelligence) has been a challenge in the AI field.
The paper “Defining intelligence: Bridging the gap between human and artificial perspectives” tries to nail down what intelligence means in AI. The authors explain differences between human and artificial intelligence (AI), highlight how intelligence is multidimensional, and propose “a refined nomenclature” to harmonize the definitions of human and artificial intelligence.
Specifically, the paper looks at how intelligence is measured and calls for 'AI metrics':
Paralleling psychometrics, ‘AI metrics’ is suggested as a needed computer science discipline that acknowledges the importance of test reliability and validity, as well as standardized measurement procedures in artificial system evaluations. Drawing parallels with human general intelligence, artificial general intelligence (AGI) is described as a reflection of the shared variance in artificial system performances.
They point out that what is described as intelligence in AI is often “observation of artificial achievement and expertise.” This leads to confusion of terms. In the end, however, it’s the achievement and capability of AI that matters, not whether it matches our human definitions of general intelligence.
MiniCPM: Small Language Models with Scalable Training Strategies
The paper “MiniCPM: Unveiling the Potential of Small Language Models with Scalable Training Strategies” show the capability of well-trained Small Language Models (SLMs) as a resource-efficient alternative to larger LLMs.
They present the MiniCPM family - MiniCPM-DPO, MiniCPM-MoE and MiniCPM-128K - in 1.2 and 2.4B parameter sizes, and show they perform as good or better than many larger 7B and 13B counterparts:
MiniCPM has very close performance compared with Mistral-7B on open-sourced general benchmarks with better ability on Chinese, Mathematics and Coding after SFT. The overall performance exceeds Llama2-13B, MPT-30B, Falcon-40B, etc.
Much of their studies to get to highly optimized SLM was using “extensive model wind tunnel experiments for stable and optimal scaling.” They showed that training a smaller model can match the performance of a larger one with an acceptable increase in training compute. This helped them “derive the much higher compute optimal data-model ratio than Chinchilla Optimal.”
A larger data-to-model ratio is more efficient for inference and deployment, so expect new LLMs to continue to trend towards higher data-to-model-size ratios and higher performance-per-model-size. MiniCPM models are available at this Github repo.
LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders
Before LLMs, natural language processing (NLP) tasks required complex pipelines to process tasks. LLMs have displaced the complex NLP flows, but some NLP tasks still remain. The paper “LLM2Vec: Large Language Models Are Secretly Powerful Text Encoders” introduces LLM2Vec, a simple unsupervised approach that can transform any decoder-only LLM into a strong text encoder.
We demonstrate the effectiveness of LLM2Vec by applying it to 3 popular LLMs ranging from 1.3B to 7B parameters and evaluate the transformed models on English word- and sequence-level tasks. We outperform encoder-only models by a large margin on word-level tasks and reach a new unsupervised state-of-the-art performance on the Massive Text Embeddings Benchmark (MTEB).
It’s not surprising that larger LLMs can solve problems previously done by smaller special-purpose models, but the demonstration shows that LLMs can be general-purpose NLP task-solvers.
Better Reasoning Using LLMs as Pseudocode Compilers
Research from Yonsei University present a new approach to improve algorithmic reasoning in LLMs, in the paper “Language Models as Compilers: Simulating Pseudocode Execution Improves Algorithmic Reasoning in Language Models.” Algorithmic reasoning refers to understanding complex patterns in a problem and decomposing them into reasoning steps to obtain a solution.
They call their approach “Think-and-Execute,” a two-step process:
(1) In Think, we discover a task-level logic that is shared across all instances for solving a given task and then express the logic with pseudocode;
(2) In Execute, we further tailor the generated pseudocode to each instance and simulate the execution of the code.
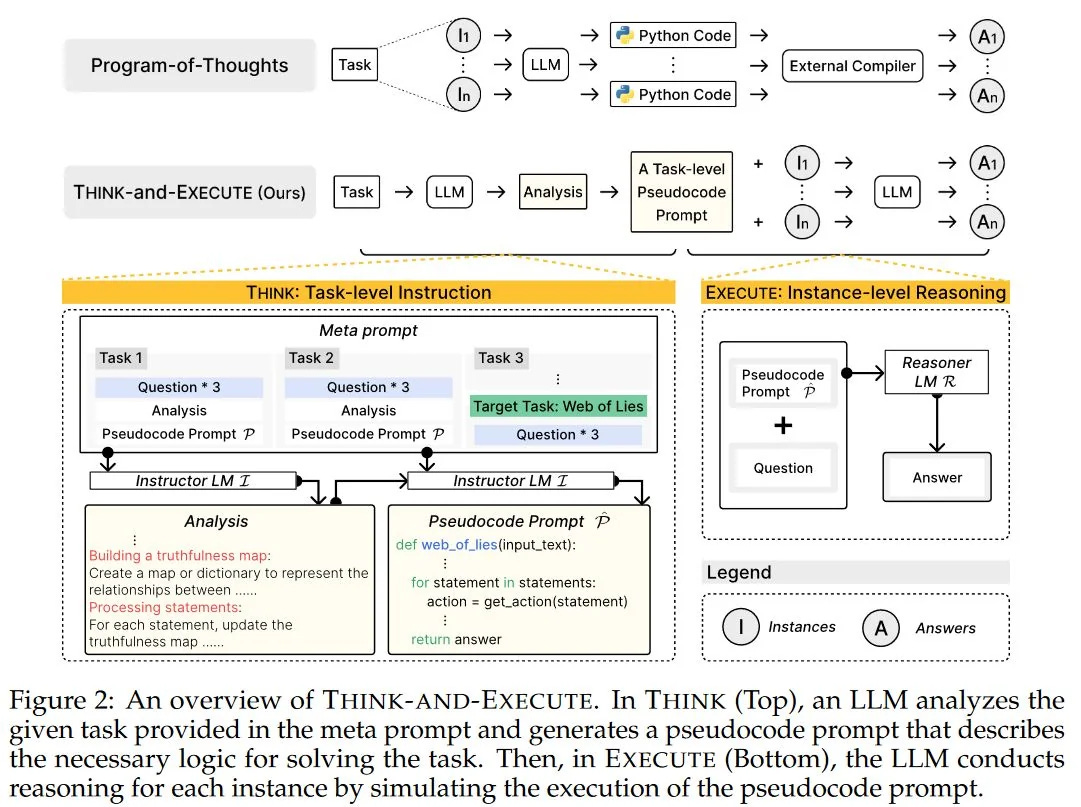
The pseudo-code acts as a guide for the thought process, and simulating the execution a guided-step-by-step. This approach outperforms other prior reasoning prompt approaches, such as chain-of-thought (CoT) and program-of-thought (PoT). The authors explain why:
“Compared to natural language, pseudocode can better guide the reasoning of LLMs, even though they are trained to follow natural language instructions.”
ChatGLM-Math Improves LLM Problem-Solving with Self-Critique
Mathematical problem-solving is good material for AI research, since LLMs struggle at reasoning, but can get coaxed to perform better with the right approach.
The paper “ChatGLM-Math: Improving Math Problem-Solving in Large Language Models with a Self-Critique Pipeline” takes an approach of using self-critique to create a fine-tuned LLM with superior math skills.
They start by training a special-purpose LLM, a Math-Critique model, and using it in a self-critique pipeline to provide feedback and improve results. Then they use fine-tuning and DPO (direct preference optimization) using the Critique-DPO dataset from the prior critiques of LLM answers.

With this pipeline, they produced a fine-tuned with significantly enhanced mathematical problem-solving skills while still maintaining its language ability. Specifically, their ChatGLM3-32B based fine-tuned LLM outperformed all but GPT-4 on a panel of math problem-solving benchmarks. More info and data is shared on Github.

OpenEQA: Embodied Question Answering
“We present a modern formulation of Embodied Question Answering (EQA) as the task of understanding an environment well enough to answer questions about it in natural language. An agent can achieve such an understanding by either drawing upon episodic memory, exemplified by agents on smart glasses, or by actively exploring the environment, as in the case of mobile robots.” - From “OpenEQA” paper
How do you evaluate how good your robot is at navigating and understanding their environment? That’s what Meta’s Fundamental AI Research (FAIR) addresses in “OpenEQA: Embodied Question Answering in the Era of Foundation Models.”
To evaluate this, they develop OpenEQA – the first open-vocabulary benchmark dataset for EQA (embodied question answering):
OpenEQA contains over 1600 high-quality human generated questions drawn from over 180 real-world environments. In addition to the dataset, we also provide an automatic LLM-powered evaluation protocol that has excellent correlation with human judgement.

They found that on these rather ‘common sense’ tests of understanding the world, identifying objects in it, and remembering things, multi-model LLMs fall far behind humans on this OpenEQA benchmark. Humans have the upper hand, for now.
