
AI Research Roundup 24.05.17
Platonic Representation Hypothesis, Chameleon multimodel model, Idefic2 VLM, ALPINE planning for LLMs, CAT3D 3D model gen, Online RLHF workflow


Introduction
Here are our AI research highlights for this week:
The Platonic Representation Hypothesis
Chameleon: Mixed-Modal Early-Fusion Foundation Models
Idefic2: What matters when building vision-language models?
ALPINE: Unveiling the Planning Capability of Autoregressive Learning in Language Models
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
RLHF Workflow: From Reward Modeling to Online RLHF
The Platonic Representation Hypothesis
“The Platonic Representation Hypothesis: Neural networks, trained with different objectives on different data and modalities, are converging to a shared statistical model of reality in their representation spaces.”
In The Platonic Representation Hypothesis, Huh and co-authors from MIT present a simple but profound claim, that representations in AI models, particularly deep networks, are converging, showing alignment between different models trained on different datasets and tasks, even across modalities like vision and language.
The authors show that as vision models and language models grow larger “they measure distance between datapoints in a more and more alike way,” converging towards a shared statistical representation. This shared representation is hypothesized to be a statistical model of the underlying reality that generates the data we observe. This is termed the “platonic representation,” drawing inspiration from Plato's concept of an ideal reality underlying our perceptions.

The authors suggest that this observed convergence is driven by factors such as the pressure to solve multiple tasks, the increased capacity of larger models, and the inherent bias of deep networks towards simple (but complete) solutions.
The implications of this are far-reaching. For example, they explain training data can be shared across modalities and point out “… if you want to build the best LLM, you should also train it on image data.” We see that the best frontier AI models, GPT-4o and Gemini 1.5 Pro, are now natively multi-modal.
Another implication is that future scaling of models will lead to even greater convergence of frontier AI models. Those models will also have reduced hallucinations and biases, by being more aligned with the underlying structure of the world.
The most critical implication is highly advanced AI models will converge to become similar idealized models, using similar training datasets and architectures to representing the same underlying reality.
Chameleon: Mixed-Modal Early-Fusion Foundation Models
FAIR at Meta presents “Chameleon: Mixed-Modal Early-Fusion Foundation Models,” a family of mixed-modal (image, text and code) models that comes in two sizes, 7B and 34B. It is trained from scratch on an interleaved mixture of ∼10T tokens of all modalities, and can take a mixture of text and image input as well as produce a mix of text and image output.

Chameleon represents all modalities - images, text, and code - as tokens, and takes an early-fusion approach, where all modalities are projected into a shared representational space from the start. Early fusion allows for seamless reasoning and generation, but it also presents significant technical challenges in optimization stability and scaling.

Chameleon models are capable across a range of tasks, including visual question answering, image captioning, text generation, image generation, and long-form mixed modal generation. Chameleon models were evaluated on a variety of text, image and combined understanding and generation tasks, and compared with other models. It showed:
… state-of-the-art performance in image captioning tasks, outperforms Llama-2 in text-only tasks while being competitive with models such as Mixtral 8x7B and Gemini-Pro, and performs non-trivial image generation, all in a single model. It also matches or exceeds the performance of much larger models, including Gemini Pro and GPT-4V, according to human judgments on a new long-form mixed-modal generation evaluation,
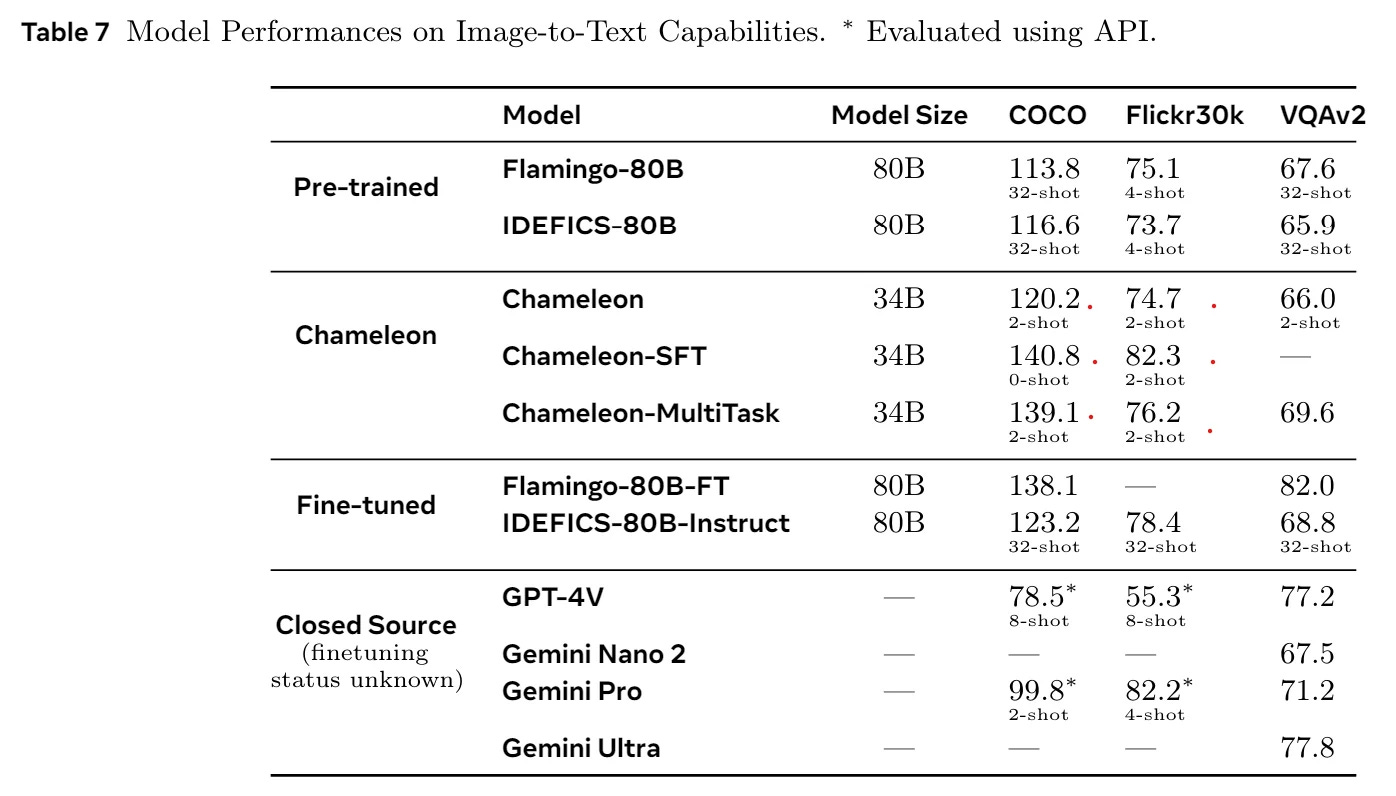
Since we don’t have technical details for the native multi-modal Gemini model and GPT-4o, it’s significant and helpful that Meta is providing Chameleon technical details; it’s a significant step forward to multimodal models.
Idefic2: What matters when building vision-language models?
What matters when building vision-language models? AI researchers at the Sorbonne and Hugging Face ask this question in a paper that considers design decisions for vision-language models (VLMs), and presents Idefics2, an efficient foundational VLM of 8 billion parameters.
They claim that critical decisions regarding the design of VLMs are often not justified, impeding progress on model performance. They review the VLM literature and perform experiments to evaluate design choices and derive several findings that help them design the Idefic2 VLM. For example, they chose an auto-regressive (versus cross-attention) approach for the VLM.

They produced the open VLM Idefics2 model, an 8B parameter model which performs well on OCR, document understanding and visual reasoning. It achieves state-of-the-art performance within its size category across various multimodal benchmarks, such as on VQAv2. Idefics2 models (base, chat, instruct) were released on HuggingFace, along with the datasets created for its training.

ALPINE: Unveiling the Planning Capability of Autoregressive Learning in Language Models
The paper “ALPINE: Unveiling the Planning Capability of Autoregressive Learning in Language Models” explores the ability of LLMs to perform planning tasks. The researchers investigate whether LLMs can effectively plan and reason about sequences of actions to achieve specific goals, without relying on specialized planning algorithms or architectures.
The researchers used a technique called "ALPINE" (Autoregressive Language models for Planning and Inference) to test the planning capabilities of Transformer-based LLMs:
We abstract planning as a network path-finding task where the objective is to generate a valid path from a specified source node to a designated target node. In terms of expressiveness, we show that the Transformer is capable of executing path-finding by embedding the adjacency and reachability matrices within its weights. Our theoretical analysis of the gradient-based learning dynamic of the Transformer reveals that the Transformer is capable of learning both the adjacency matrix and a limited form of the reachability matrix.
Their theoretical results were validated through experiments on path-finding on trained transformer models, as wall as applying the methodology to the Blocksworld real-world planning benchmark.
Path-finding is an analog to the step-by-step process needed in general planning, and a key result is determining how transformers learn planning capabilities:
“The Transformer architecture is adjusting its learning by balancing the consideration between the immediate continuation of the next step and its final goal of reaching the target.”
However, planning in Transformers has limitations, such as “it cannot identify reachability relationships through transitivity.” Thus, it fails when concatenation is needed to generate a path. LLMs will continue to leverage other techniques (such as external planning tools) to overcome these limitations in planning.
CAT3D: Create Anything in 3D with Multi-View Diffusion Models
Google DeepMind gives us “CAT3D: Create Anything in 3D with Multi-View Diffusion Models,” another advance in 3D scene generation from 2D inputs. What’s new about this approach is turn inputs to generate the 3D scene into a multi-view diffusion model:
Given any number of input images and a set of target novel viewpoints, our model generates highly consistent novel views of a scene. These generated views can be used as input to robust 3D reconstruction techniques to produce 3D representations that can be rendered from any viewpoint in real-time.
This makes it very flexible in the inputs it can take in to generate the 3D rendering: Text-to-image-to-3D, single image to 3D, or multiple image views to 3D.

CAT3D can create entire 3D scenes in as little as one minute and has superior rendering of 3D scenes from single image or few images over existing methods. They share results and interactive demos in their project page.
RLHF Workflow: From Reward Modeling to Online RLHF
There has been a lot of progress in improving fine-tuning in the open source AI community in the past year. The paper “RLHF Workflow: From Reward Modeling to Online RLHF” from AI researchers at Salesforce AI Research continues this trends and presents the workflow for Online Iterative Reinforcement Learning from Human Feedback (RLHF).
Online iterative learning in RLHF means that we deploy and test intermediate models and obtain human feedback on the model responses, updating policy and reward models. With this online feedback loop, online iterative RLHF outperforms its offline counterpart by a large margin.

Existing open-source RLHF projects are still largely confined to the offline learning setting and online human feedback is usually infeasible for open-source communities with limited resources. So the authors of this project use a diverse set of open-source datasets to construct preference models, using the constructed proxy preference model to approximate human feedback.
They have trained fine-tuned LLMs using this technique and shared the on RLHFflow team page on HuggingFace. Their latest model LLama-3-iterative-DPO-final shows best-in-class benchmarks, such as 8.46 on MTBench, up from 8.15 on the Llama 3 8B base instruct model.
The RLHFflow team made their curated datasets, step-by-step code guidebooks, and model fine-tunes publicly available at their RLHFflow Github repo and on their HuggingFace page.