AI Research Roundup 24.06.28 - Agents and Reasoning
Octo-planner, MCTSr - Monte Carlo Tree Search self-refine, Agile Coder multi-agents for agile SW development, Mixture of Agents


Introduction
Personal note: I am in San Francisco for the AI Engineer’s World’s Fair that just concluded. I met some great people from around the world and in all parts of the AI ecosystem. To those I met who are new subscribers, thanks for joining!
I’ll give a full report on the AI Engineers World’s Fair later, but one topic that was front and center was AI agents: LlamaIndex Llama Agents, OpenAI hinting at agents, and standing room only for CrewAI announcing code execution and ‘bring your own’ AI agents from others frameworks, etc.
The road to making AI agents production-ready and reliable enough for prime-time has been rocky, but there has been steady progress at methods to improve reasoning, planning, tool use, RAG (retrieval augmented generation), and more.
Here are some recent AI research results in this area:
Octo-planner: On-device Language Model for Planner-Action Agents
MCTSr: Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
Agile Coder: Dynamic Collaborative Agents for Software Development based on Agile Methodology
Mixture of Agents
Octo-planner: On-device Language Model for Planner-Action Agents
For AI agents to complete complex tasks well, planning is essential to break those tasks into the correct discrete subtasks. This is best done in a flow that separates planning and action execution into two distinct components.
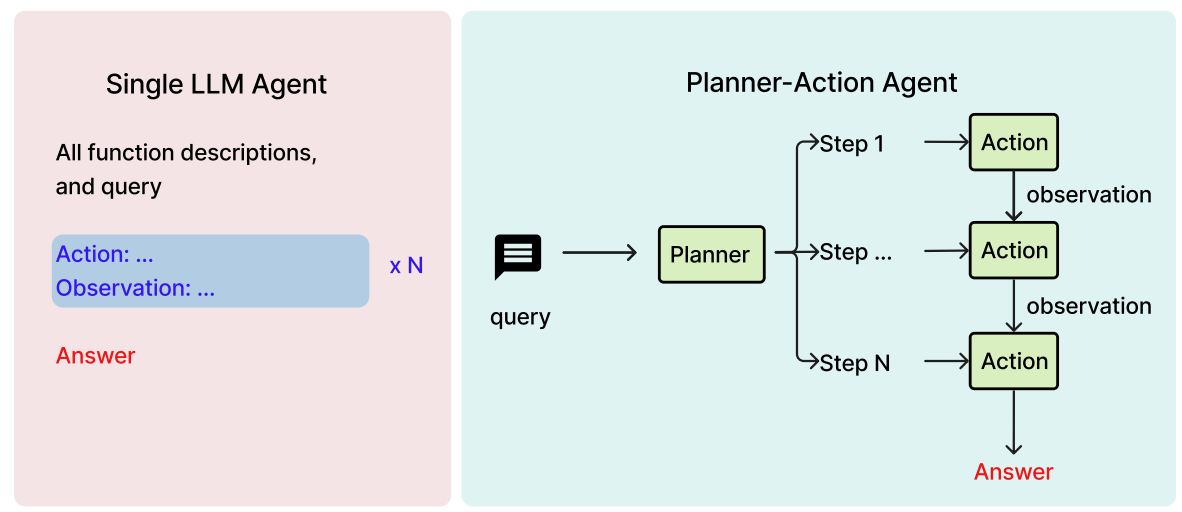
To implement this flow for on-device AI models, Nexa AI presents Octo-planner: On-device Language Model for Planner-Action, an on-device planning agent based on 3.8 billion parameter Phi-3 Mini, that is fine-tuned for planning tasks and designed to work alongside action agents like Octopus V2 for function execution.
Our approach involves using GPT-4 to generate diverse planning queries and responses based on available functions, with subsequent validations to ensure data quality. We fine-tune the Phi-3 Mini model on this curated dataset, achieving a 97% success rate in our in-domain test environment.

They tried both a full model retraining and LoRA fine-tuning, finding LoRA achieved 85% success rate. They also developed a multi-LoRA training method to address multi-domain planning challenges. This merged LoRA model weights.
While AI agents typically are using the best frontier AI models for planning, this approach shows the efficacy of distilling the planning task to smaller fine-tuned AI models, giving users advantages of speed, cost, and running on-device.
They open-sourced model weights on HuggingFace and have a demo here.
MCTSr: Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B
“Agents can learn decision-making and reasoning from the trial-and-error as humans do.”
One underlying premise of most progress in AI reasoning is the concept of trial-and-error exploring and learning via feedback. While these are well-known, there is a challenge integrating these with LLMs and their next-token sequential process.
The paper “Accessing GPT-4 level Mathematical Olympiad Solutions via Monte Carlo Tree Self-refine with LLaMa-3 8B” takes on this challenge with MCT Self-Refine (MCTSr) algorithm, an innovative integration of LLMs with Monte Carlo Tree Search (MCTS):
MCTSr leverages systematic exploration and heuristic self-refine mechanisms to improve decision-making frameworks within LLMs. The algorithm constructs a Monte Carlo search tree through iterative processes of Selection, self-refine, self-evaluation, and Backpropagation, utilizing an improved Upper Confidence Bound (UCB) formula to optimize the exploration-exploitation balance.
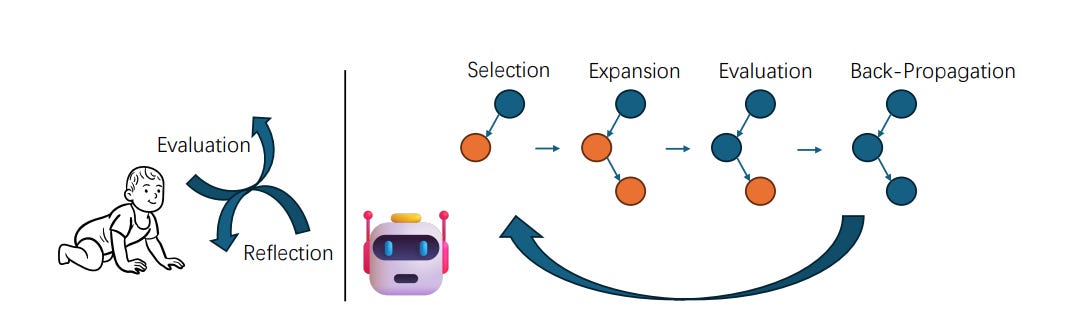
The Sr part of MCTSr is self-refine. The LLM self-refines its answers based on the search of solutions via MCTS, and can be viewed as an extensive multi-turn form of self-refine.
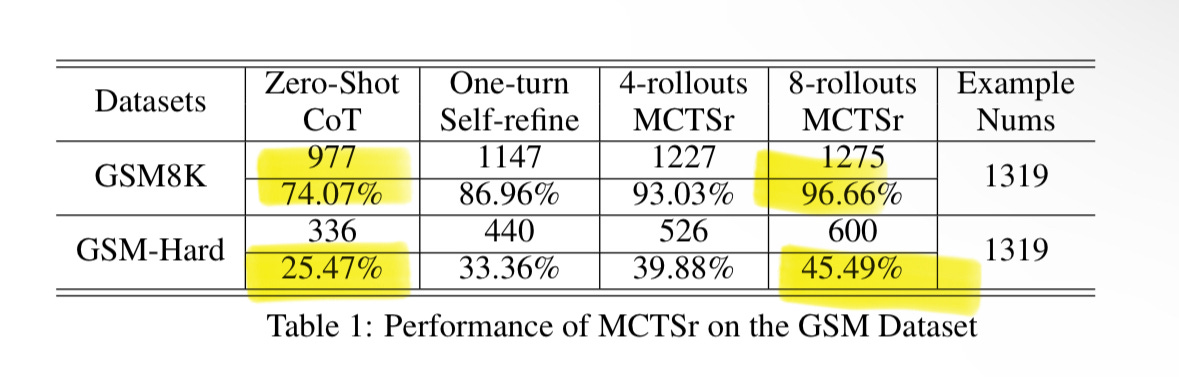
MCTSr’s results are stunning. Llama 3 8B with MCTSr gets 96.7% on the math benchmark GSM8K (versus 74% for Llama 3 8B CoT). It also drastically improves results on GSM Hard, MATH, and Olympiad-level benchmarks, including Math Odyssey, AIME, and OlympiadBench.
Agile Coder: Dynamic Collaborative Agents for Software Development based on Agile Methodology
Developed by a group in Vietnam, Agile Coder is an multi-agent framework for software development, with their research reported in “AgileCoder: Dynamic Collaborative Agents for Software Development based on Agile Methodology.”
Their specific angle is to integrate Agile Methodology (AM) into the framework:
AgileCoder mimics real-world software development by creating a backlog of tasks and dividing the development process into sprints, with the backlog being dynamically updated at each sprint. … This system assigns specific AM roles such as Product Manager, Developer, and Tester to different agents, who then collaboratively develop software based on user inputs.
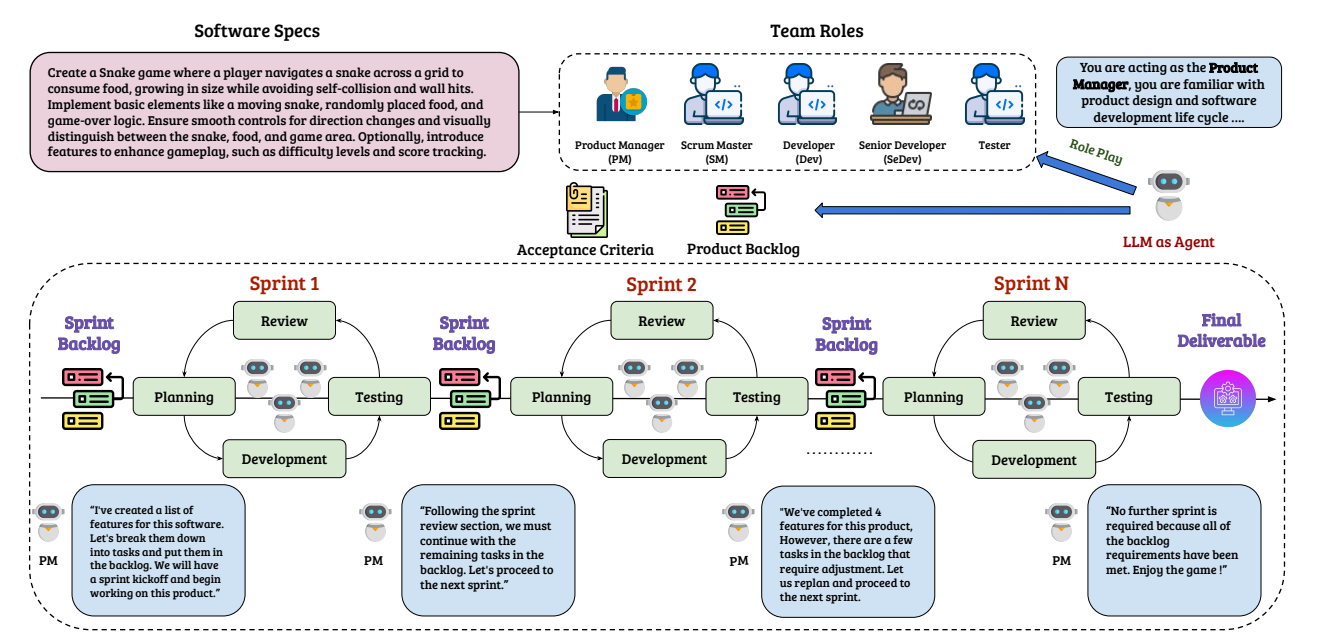
AgileCoder is encompassing the whole software development flow within a specific framework. This sort of process-defined multi-agent system can be expected to apply to many business workflows.
The authors show that AgileCoder surpasses prior agents frameworks, like ChatDev and MetaGPT, on HumanEval, but don’t show its performance on SWE-Bench, which is becoming the benchmark of choice for AI software coding agents.
How software engineering methodology changes in the era of AI is another question: Do we need sprints when an AI Agent could possibly chew through the tasks of a two-week sprint in an hour or even minutes? It’s something to consider.
Mixture of Agents
Presented by Together AI, Mixture of Agents is a simple but powerful architecture: Generate 3 initial GPT-4 completions, have GPT-4 reflect on them and review them, and then have GPT-4 produce a final output based on its deliberations.
They shared the work in a blog post as well as a paper “Mixture-of-Agents Enhances Large Language Model Capabilities.” The Mixture-of-Agents (MoA) methodology is about leveraging the efforts of multiple LLMs, as well as benefitting from review and revision:
In our approach, we construct a layered MoA architecture wherein each layer comprises multiple LLM agents. Each agent takes all the outputs from agents in the previous layer as auxiliary information in generating its response.

The Mixture of Agents approach achieves great results. They created Together MoA, a mixture of multiple open LLMs working together:
Together MoA, uses six open source models as proposers and Qwen1.5-110B-Chat as the final aggregators. The six open source models tested are: WizardLM-2-8x22b, Qwen1.5-110B-Chat, Qwen1.5-72B-Chat, Llama-3-70B-Chat, Mixtral-8x22B-Instruct-v0.1, dbrx-instruct. We design MoA to have a total of three layers, striking a good balance between quality and performance.
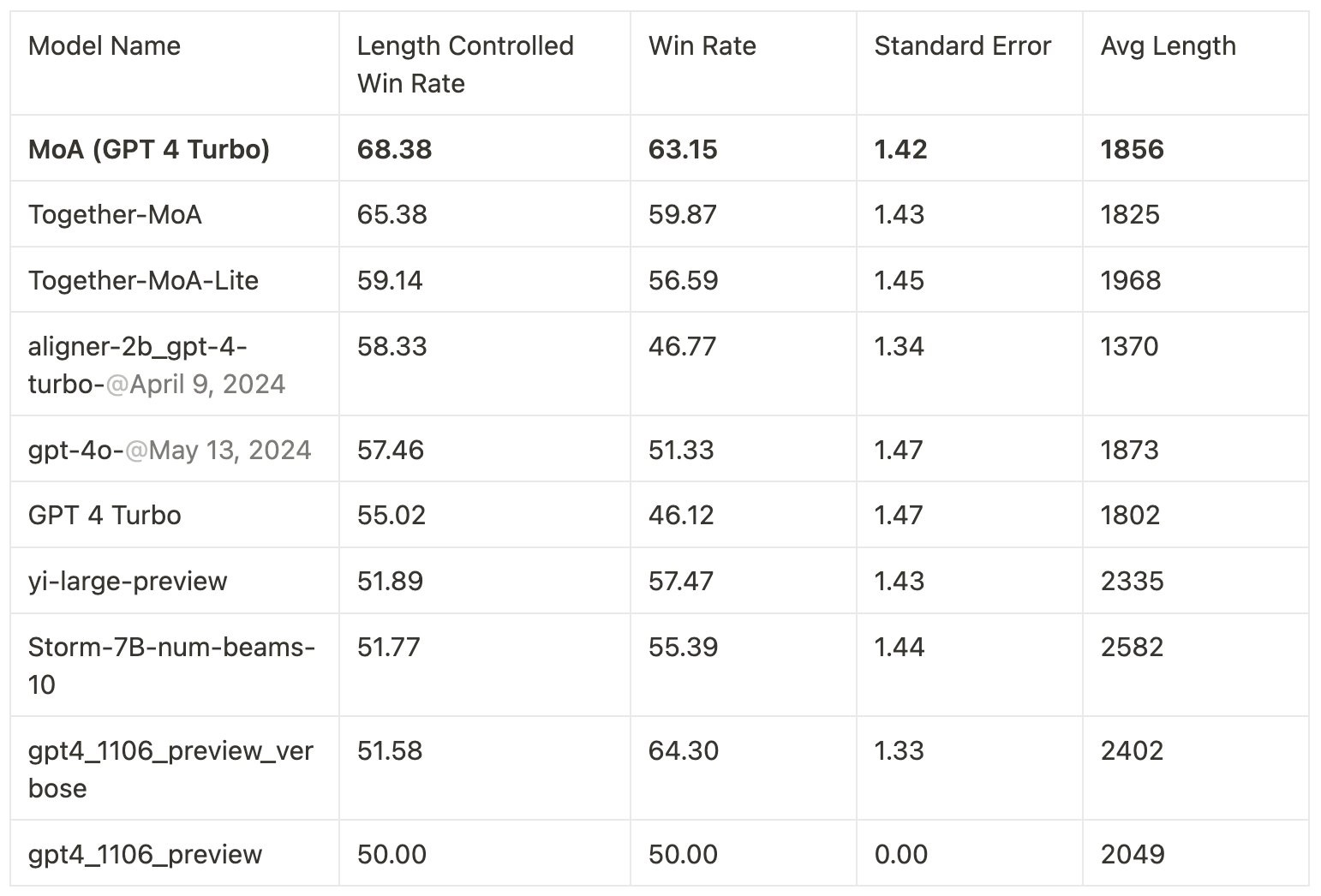
This MoA model achieved state-of-art performance on AlpacaEval 2.0 (65.3%), MT-Bench and other benchmarks, surpassing GPT-4o on benchmarks, but doing it 25 times cheaper.

A GPT-4 turbo-powered MoA model did even better.
There are several lessons from this result: As with MCTSr, methods of review and reflection raise scores. The underlying model matters, but iterating on a smaller AI model can overcome gaps with a bigger AI model.