AI Research Roundup 24.07.05
InternLM-XComposer-2.5 vision model, RouteLLM, Summary of a Haystack, APIGen function-calling datasets, ESFT - expert-specialized fine-tuning for MoE LLMs.


Introduction
Here are our AI research highlights for this week:
InternLM-XComposer-2.5: A Large Vision Language Model with Long Context
RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing
Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems
APIGen: Pipeline for Generating Function-Calling Datasets
ESFT: Expert-Specialized Fine-Tuning for Mixture of Experts (MoE)
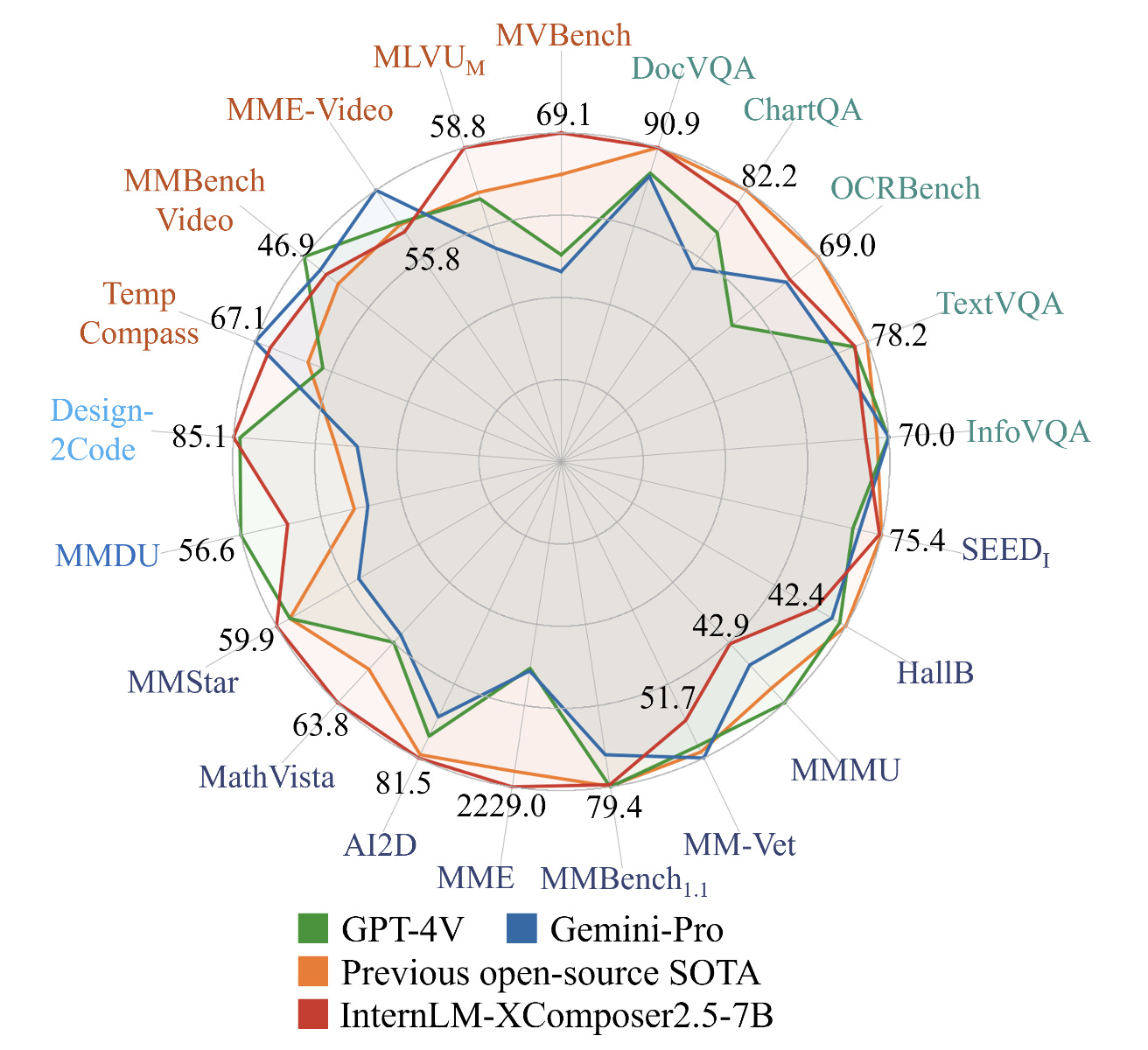
InternLM-XComposer-2.5: A Large Vision Language Model with Long Context
Coming out of Chinese Universities, the open-source vision model InternLM-XComposer-2.5 has long-context capabilities, ultra-high resolution understanding, fine-grained video understanding, and multi-turn multi-image dialogue. It’s presented in the paper “InternLM-XComposer-2.5: A Versatile Large Vision Language Model Supporting Long-Contextual Input and Output” and available on HuggingFace.
It’s trained on 24K interleaved image-text contexts and can extend to 96K long contexts via RoPE extrapolation, which gives it greater abilities on on tasks with long input and output contexts, such as ultra-high resolution and fine-grained video understanding, and multi-turn multi-image dialog.
In addition to comprehension, IXC-2.5 extends to two compelling applications using extra LoRA parameters for text-image composition: (1) Crafting Webpages and (2) Composing High-Quality Text-Image Articles.
With just a base 7B LLM for its backend, it “ surpasses or competes closely with GPT-4V and Gemini Pro on 16 key tasks” out of 28 benchmarks. This is an impressively useful model.
RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing
Using the most general and advanced frontier AI model for every query and task yields good results but can be costly, so the idea of LLM routing has arisen: Determine and use the best LLM for different specific queries.
This is done with a router that takes in each user's query and decides what LLM to route it to; this makes for good performance at lower cost. How do you decide the right LLM for a query?
RouteLLM: An Open-Source Framework for Cost-Effective LLM Routing has an answer in RouteLLM, an LLM routing framework based on preference data, and described in the paper “RouteLLM: Learning to Route LLMs with Preference Data”:
[In RouteLLM], we formalize the problem of LLM routing and explore augmentation techniques to improve router performance. We trained four different routers using public data from Chatbot Arena and demonstrate that they can significantly reduce costs without compromising quality, with cost reductions of over 85% on MT Bench, 45% on MMLU, and 35% on GSM8K as compared to using only GPT-4, while still achieving 95% of GPT-4’s performance.
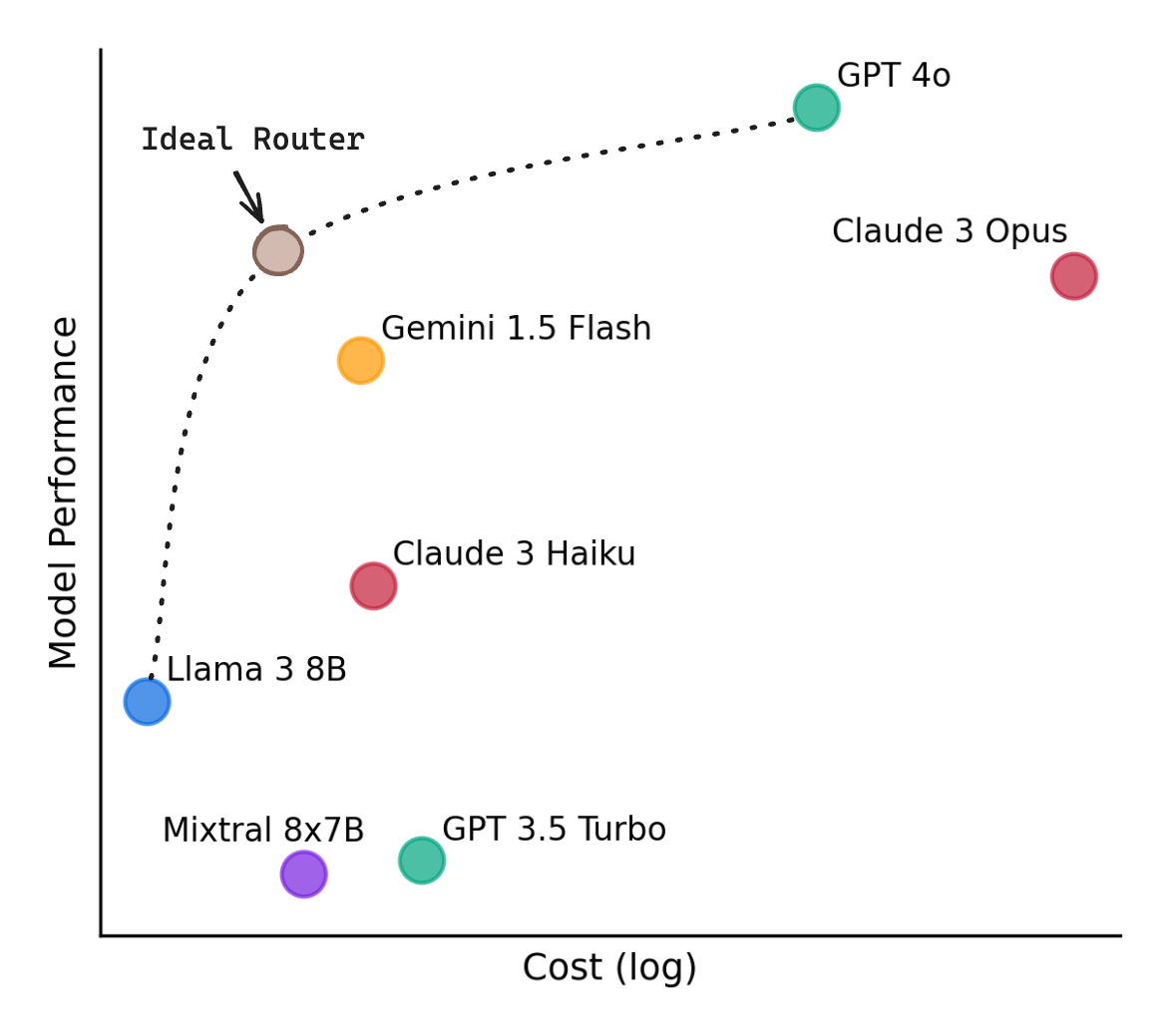
They trained the four routers on a task of choosing between a “strong” AI model (GPT-4 turbo) and a “weak” AI model (Mixtral 8x7B), using a mix of Chatbot Arena data and data augmentation:
A similarity-weighted (SW) ranking router that performs a “weighted Elo calculation” based on similarity
A matrix factorization model that learns a scoring function for how well a model can answer a prompt
A BERT classifier that predicts which model can provide a better response
A causal LLM classifier that also predicts which model can provide a better response
All models benefitted from data augmentation to perform better. Of the four router models, the best-performing was the Matrix Factorization model:
“Notably, matrix factorization is able to achieve 95% of GPT-4 performance using 26% GPT-4 calls, which is approximately 48% cheaper as compared to the random baseline.”
The authors publicly released code and datasets for their open-source RouteLLM framework on Github.
Summary of a Haystack: Evals of Long-Context LLMs and RAG Systems
We need better evaluations of how LLMs can recall information via RAG and their context beyond simple recall metrics like Needle-in-a-Haystack.
The paper “Summary of a Haystack: A Challenge to Long-Context LLMs and RAG Systems” proposes using summarization as an insightful metric - LLM responds to a query with a long-form answer (200-300 words) that requires identifying and summarizing insights:
We design a procedure to synthesize Haystacks of documents, ensuring that specific insights repeat across documents. The "Summary of a Haystack" (SummHay) task then requires a system to process the Haystack and generate, given a query, a summary that identifies the relevant insights and precisely cites the source documents.
Since we have precise knowledge of what insights should appear in a haystack summary and what documents should be cited, we implement a highly reproducible automatic evaluation that can score summaries on two aspects - Coverage and Citation.
Coverage is whether the information is covered in the summary, while citation is whether correct source for information is cited.

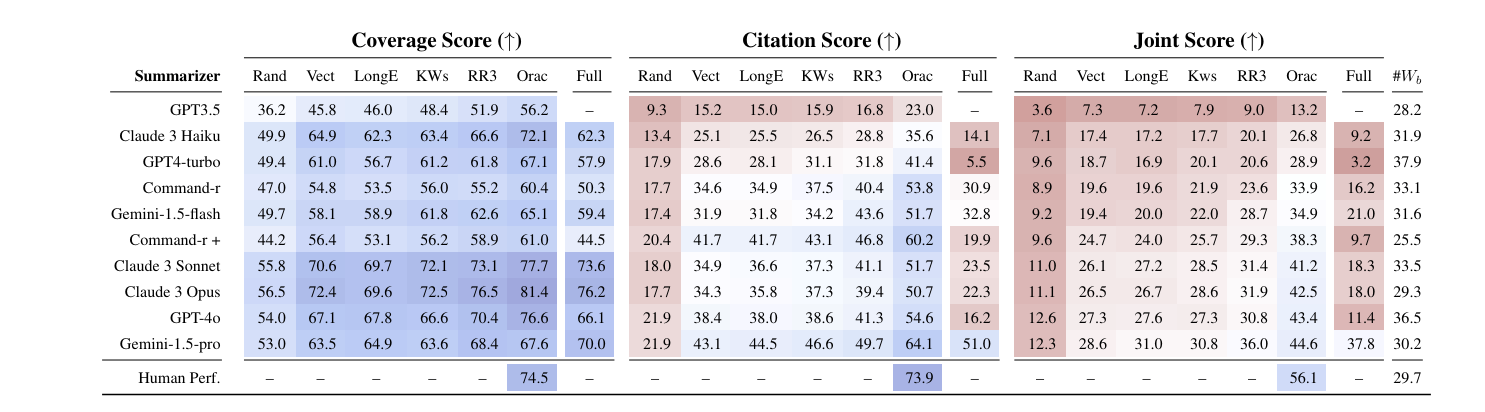
They evaluated SummHay on six retriever methods in RAG systems across 10 different LLMs. In evaluating LLMs and corresponding RAG systems, they found that:
Frontier AI models (Claude 3 Opus, GPT-4) without a retriever score well on some coverage tasks, but fall far short on citation and SummHay overall. “For use-cases where citation quality is important, optimizing retrieval is paramount.”
The best retriever method was Oracle signal, whose score is the number of subtopic insights that appear in a given document.
“Even systems provided with an Oracle signal of document relevance lag our estimate of human performance (56%) by 10+ points on a Joint Score.”
The bottom line is that current LLMs and RAG systems are not yet human-level at the SummHay is an unsolved task.
APIGen: Pipeline for Generating Function-Calling Datasets
Function-calling is a critical part of extending LLM capabilities with tools. The paper “APIGen: Automated Pipeline for Generating Verifiable and Diverse Function-Calling Datasets” presents APIGen, an “Automated PIpeline for Generating verifiable high-quality datasets for function-calling.”

They use a 3-stage verification process, checking format, execution, and semantics to ensure accuracy and applicability of each data entry generated. They sourced APIs from ToolBench, which after cleaning resulted in 3,673 APIs across 21 categories. They released this as a comprehensive dataset containing 60,000 entries.
They fine-tuned function-calling models using the dataset generated by APIGen, showing excellent performance on function-calling:
We demonstrate that models trained with our curated datasets, even with only 7B parameters, can achieve state-of-the-art performance on the Berkeley Function-Calling Benchmark, outperforming multiple GPT-4 models. Moreover, our 1B model achieves exceptional performance, surpassing GPT-3.5-Turbo and Claude-3 Haiku.
The dataset and project information is available via their APIGen project page and as a dataset on HuggingFace.
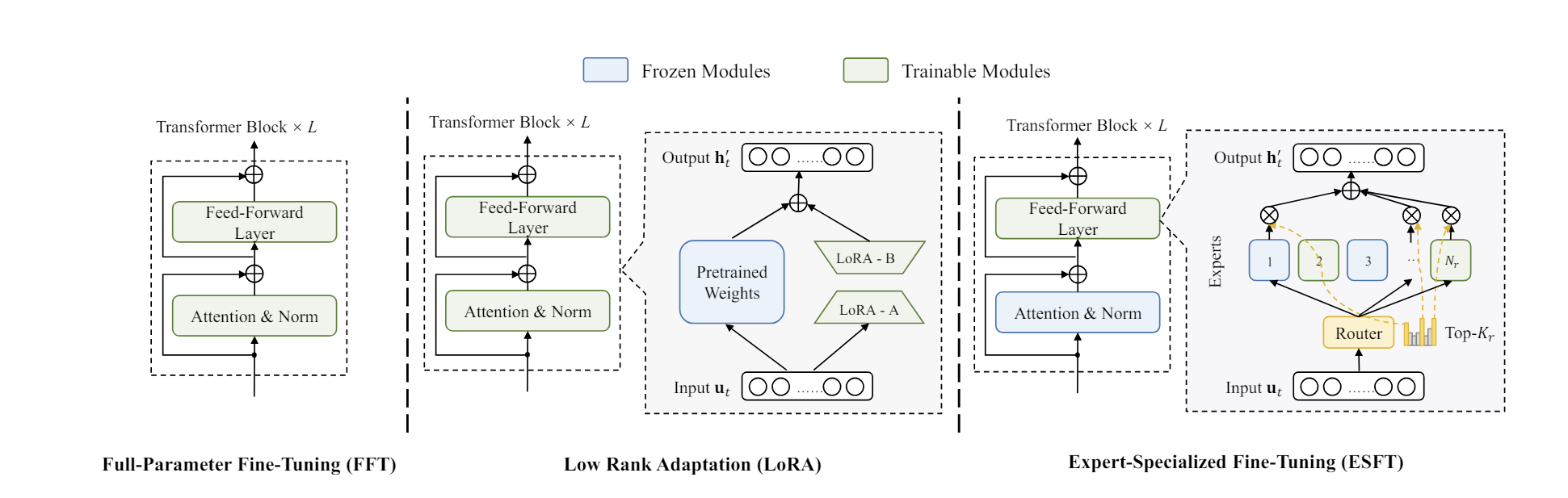
ESFT: Expert-Specialized Fine-Tuning for Mixture of Experts (MoE)
Research by Deepseek have brought together two important concepts, parameter-efficient fine-tuning and mixture-of-experts LLMs, in a paper whose title is a mouthful: “Let the Expert Stick to His Last: Expert-Specialized Fine-Tuning for Sparse Architectural Large Language Models.”
We propose Expert-Specialized Fine-Tuning, or ESFT, which tunes the experts most relevant to downstream tasks while freezing the other experts and modules.
A key observation to make the ESFT method work is that “Expert Routing is Concentrated in the Same Task.” You can fine-tune by specific tasks if you identify the right experts to apply to given tasks. The best experts are selected for training by calculating relevance scores for each expert.
ESFT doesn’t work as well for coarse-grained MoEs with a limited number of experts like Mixtral as for fine-grained MoEs.
Their method was tested on their own DeepSeek-V2-Lite MoE model, which has 8 active experts out of 66 total experts activated at a time. Experimental results showed that ESFT reduced memory by up to 90% and time by 30% while maintaining performance of full-parameter fine-tuning (FFT). ESFT also outperforms LoRA by up to 10%.
ESFT is a promising parameter-efficient fine-tuning technique for fine-grained MoE AI models.