


AI Research Roundup 24.07.26
DeepMind's AlphaProof and AlphaGeometry2, TextGrad, Open Artificial Knowledge (OAK), LLM lie detector, Internal consistency and self-feedback, OpenDevin, CoD - Chain of Diagnosis AI medical Agent.


Introduction
Our AI research highlights for this week touch on the build-out of AI beyond LLMs - agents, math problem-solving AI systems, and TextGrad, back-prop for AI systems:
AlphaProof and AlphaGeometry2 earn silver medal at Math Olympiad
TextGrad: Automatic “Differentiation” via Text
Open Artificial Knowledge
Truth is Universal: Robust Detection of Lies in LLMs
Internal Consistency and Self-Feedback in Large Language Models: A Survey
OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis
AlphaProof and AlphaGeometry2 earn silver medal at Math Olympiad
Google DeepMind’s latest AI breakthrough has made headlines: Google claims math breakthrough with proof-solving AI models. Google Deep Mind shared their own account of the feat in their blog post: AI achieves silver-medal standard solving International Mathematical Olympiad problems.
At the International Math Olympiad (IMO) 2024, held this month, the combination of AlphaProof and AlphaGeometry2 was able to solve 4 out of 6 difficult Math Olympiad problems completely, scoring 28 out of 42, which earned them a “Silver” rank that put them ahead of all but 59 of 609 contestants.
We were introduced to AlphaGeometry in January of this year. Google DeepMind has since improved it to AlphaGeometry2, which could solve 83% of all historical IMO geometry problems.
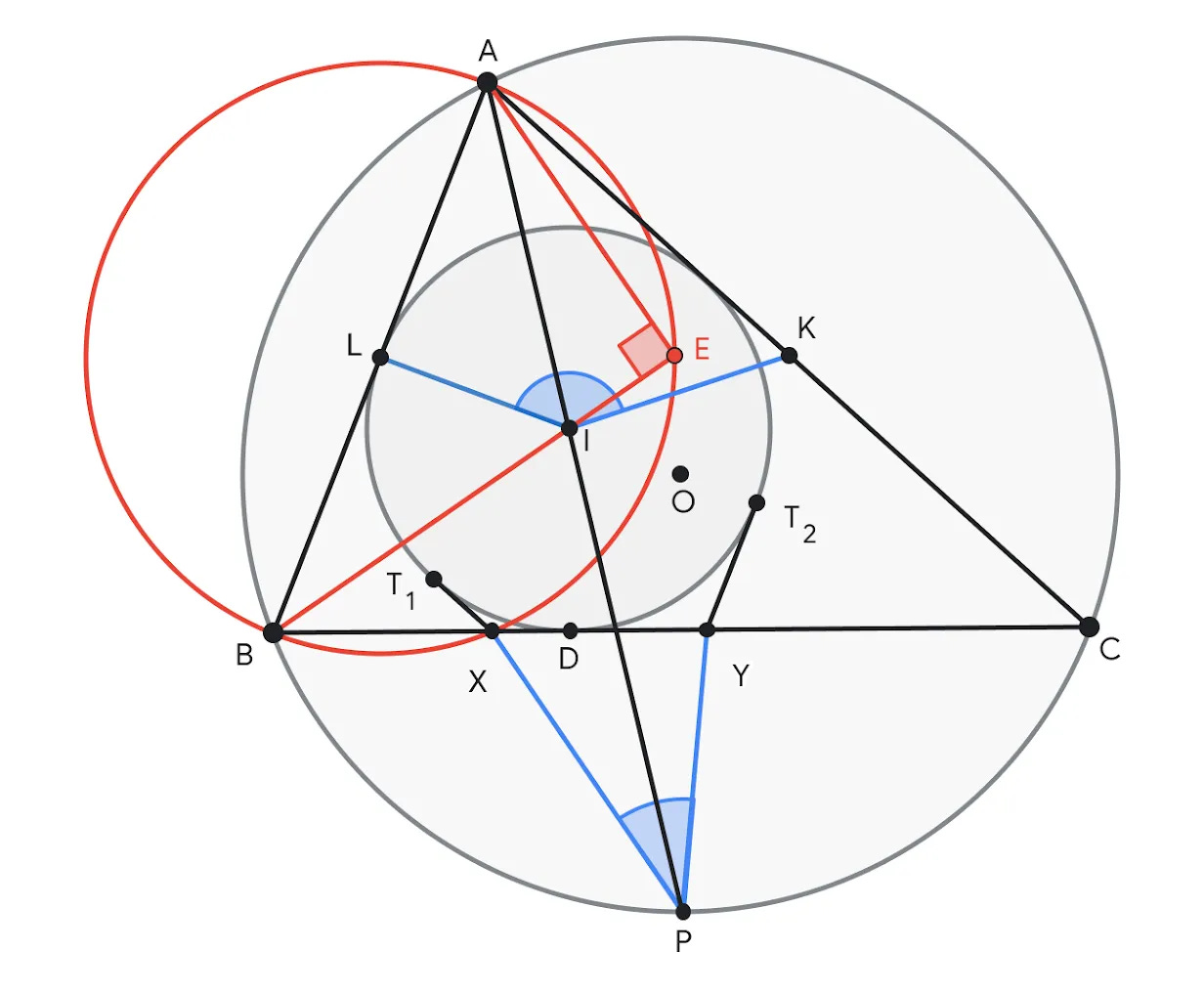
AlphaGeometry2 solved the IMO 2024 Problem 4 geometry problem, shown in the figure above, in a mere 19 seconds. DeepMind notes that AlphaGeometry2’s symbolic engine is two orders of magnitude faster than before. It’s problem-solving capabilities are greatly enhanced:
When presented with a new problem, a novel knowledge-sharing mechanism is used to enable advanced combinations of different search trees to tackle more complex problems. …
Powered with a novel search algorithm, AlphaGeometry 2 can now solve 83% of all historical (IMO) problems from the past 25 years - compared to the 53% rate by its predecessor.
Formal theorem-proving system AlphaProof was used to solve the other 3 problems. DeepMind trained AlphaProof to prove mathematical statements in the formal language Lean, using the same self-play and reinforcement learning techniques that made AlphaGo so effective. That is, starting with a pre-trained language model, they further trained AlphaProof on a large number of problems, in the millions, building up AlphaProof’s capabilities as it solved them:
When presented with a problem, AlphaProof generates solution candidates and then proves or disproves them by searching over possible proof steps in Lean. Each proof that was found and verified is used to reinforce AlphaProof’s language model, enhancing its ability to solve subsequent, more challenging problems.
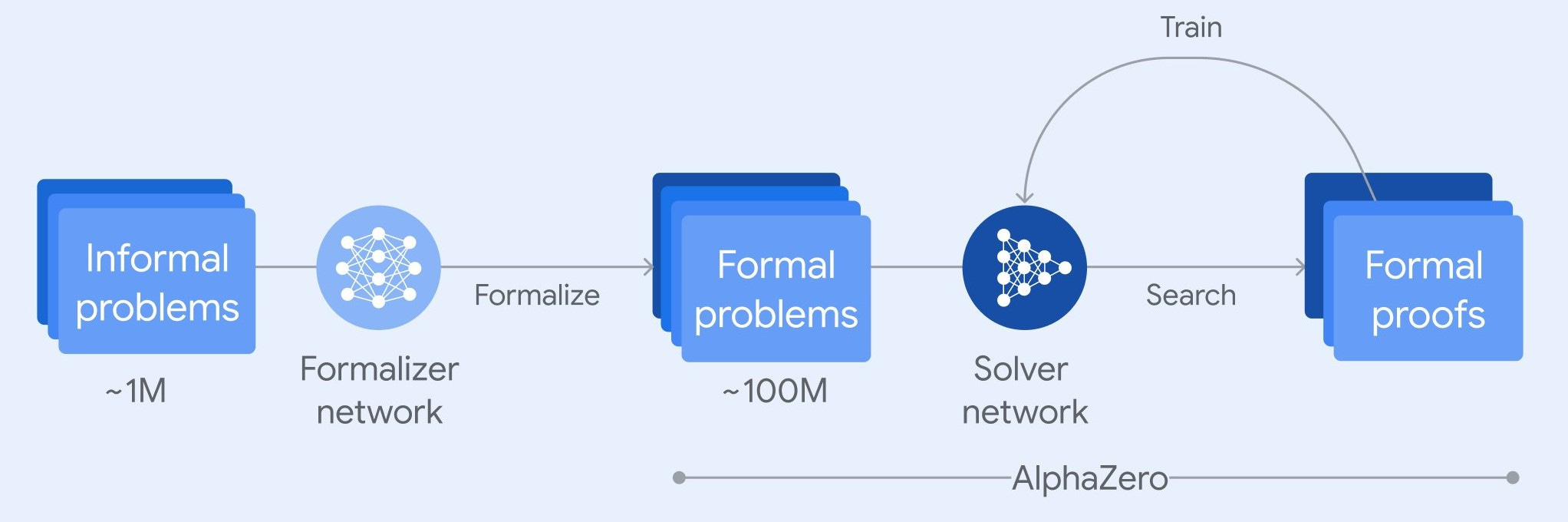
Takeaways: AI techniques that complement LLM scaling – reinforcement learning, search techniques, and formal-theorem proving – are essential to advanced AI problem-solving. Synthetic data and self-play can boost-strap AI models to higher performance. Google DeepMind’s innovations may be a path to AGI. The speed of improvement is rapid, so expect AI to win the Gold rank next year.
Text Grad: Automatic “Differentiation” via Text
Complex AI systems such as multi-agent AI assistants with discrete steps and output present a challenge: How to improve each stage to optimize the AI system? A recent paper that came out of Stanford last month, TextGrad: Automatic “Differentiation” via Text, shows a way.
In deep learning, models are trained by propagating changes from the output backwards through a model (hence, back-propagation) to more accurately reflect a desired output. Backpropagation methods for training LLMs and other deep-learning models are well-established. TextGrad applies an analog of backpropagation to improving AI systems. TextGrad holistically trains complex AI through by treating each stage of an LLM pipeline as if it’s a layer in a deep learning network, with each stage back-propagating desired changes upstream to improve the AI system.
In TextGrad, each LLM stage or module receives a (query, prompt) pair and outputs an answer; then they ask an LLM to "improve the prompt given the (query, answer) pair" and back-propagate that prompt. TextGrad follows PyTorch-like syntax and abstractions, to make it easy to use and apply.
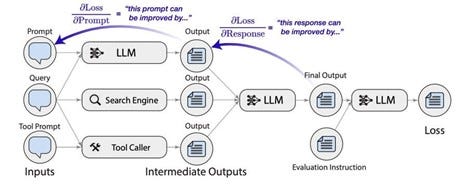
They applied TextGrad to a number of different applications, such as code optimization, molecular design, radiotherapy treatment planning, showing it has excellent performance. In particular, this approach “yields 20% relative performance gain in optimizing LeetCode-Hard coding problem solutions.” It’s just a first step and a general solution with open source implementation, so we can expect follow-on efforts.
Open Artificial Knowledge
Open Artificial Knowledge is a paper describing the Open Artificial Knowledge (OAK) dataset, a new 500 million token dataset covering diverse domains. It was generated using state-of-the-art LLMs, including GPT4o, LLaMa3-70B, LLaMa3-8B, Mixtral-8x7B, Gemma-7B, and Gemma-2-9B. The OAK dataset is focused on knowledge coverage, coherence, and factual accuracy to better align LLMs, as well as open and ethically sourced training data.

Their methodology starts with Wikipedia topic categories to generate prompts, those are fed to LLMs to elicit fact-based text responses. The OAK dataset is freely available on Hugging Face and the OAK dataset website.
Truth is Universal: Robust Detection of Lies in LLMs
The paper Truth is Universal: Robust Detection of Lies in LLMs tackles the question: How can you detect when an LLM is lying? They are able to investigate LLM internals:
(i) We demonstrate the existence of a two-dimensional subspace, along which the activation vectors of true and false statements can be separated. Notably, this finding is universal and holds for various LLMs, including Gemma-7B, LLaMA2-13B and LLaMA3-8B.
(ii) Building upon (i), we construct an accurate LLM lie detector.
Their LLM lie detector is able to determine simple true and false statements with 94% accuracy and detect complex real-world lies with 95% accuracy.
Internal Consistency and Self-Feedback in Large Language Models: A Survey
The paper Internal Consistency and Self-Feedback in Large Language Models: A Survey addresses broad questions around how LLMs often fail to respond consistently, and the various methods of self-refinement, self-consistency, and self-improvement to fix it.
The paper develops a framework called Internal Consistency to explain phenomena such as the lack of reasoning and the presence of hallucinations. It assesses the coherence among LLMs’ latent states, decoded tokens and final response:
Expanding upon the Internal Consistency framework, we introduce a streamlined yet effective theoretical framework capable of mining Internal Consistency, named Self-Feedback. The Self-Feedback framework consists of two modules: Self-Evaluation and Self-Update.
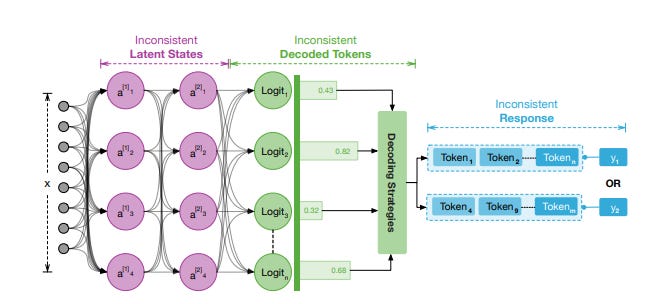
Using this consistency framework, they survey various types of self-evaluations and self-updates used to improve LLM consistency, aid reasoning, and reduce reduce hallucinations. For example, in one section, they review the types of reasoning enhancements using different topologies of self-review, chain-of-thought (CoT), self-consistency, etc.

Summarizing the field, they ask the question: “Does Self-Feedback Really Work?” Their answer is:
Self-Feedback framework can enhance model consistency by reinforcing the model’s fit to corpus priors, thereby eliminating uncertainty and improving consistency. According to the “Consistency Is (Almost) Correctness” hypothesis, this leads to an overall improvement in the model’s performance
OpenDevin: An Open Platform for AI Software Developers as Generalist Agents
Open Devin is an open source AI agent project for software engineering that emerged in March in response to the Devin AI Agent demo that went viral. It shares some of the same features as the original Devin: It can generate code, interact via a command line, and browse the web to access information and take actions.
The world of AI moves fast. This project is barely 5 months old, but they already have a paper describing their progress, in OpenDevin: An Open Platform for AI Software Developers as Generalist Agents:
We describe how the platform allows for the implementation of new agents, safe interaction with sandboxed environments for code execution, coordination between multiple agents, and incorporation of evaluation benchmarks.

OpenDevin’s performance on coding benchmarks is competitive; they claim 26% on SWE-Bench-lite for OD CodeActAgent v1.8 combined with Claude 3.5 Sonnet. More impressive though is that OpenDevin is open source (permissive MIT license) and has a strong community behind it (1.3K contributions from over 160 contributors). The OpenDevin github repo is here.
CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis
In the medical field, interpretability is key to having confidence in AI-based diagnosis. The paper CoD, Towards an Interpretable Medical Agent using Chain of Diagnosis considers how to improve interpretability for a medical agent. Similar to how chain-of-thought improves reasoning, the paper introduces Chain-of-Diagnosis (CoD):
CoD transforms the diagnostic process into a diagnostic chain that mirrors a physician's thought process, providing a transparent reasoning pathway. Additionally, CoD outputs the disease confidence distribution to ensure transparency in decision-making. This interpretability makes model diagnostics controllable and aids in identifying critical symptoms for inquiry through the entropy reduction of confidences.
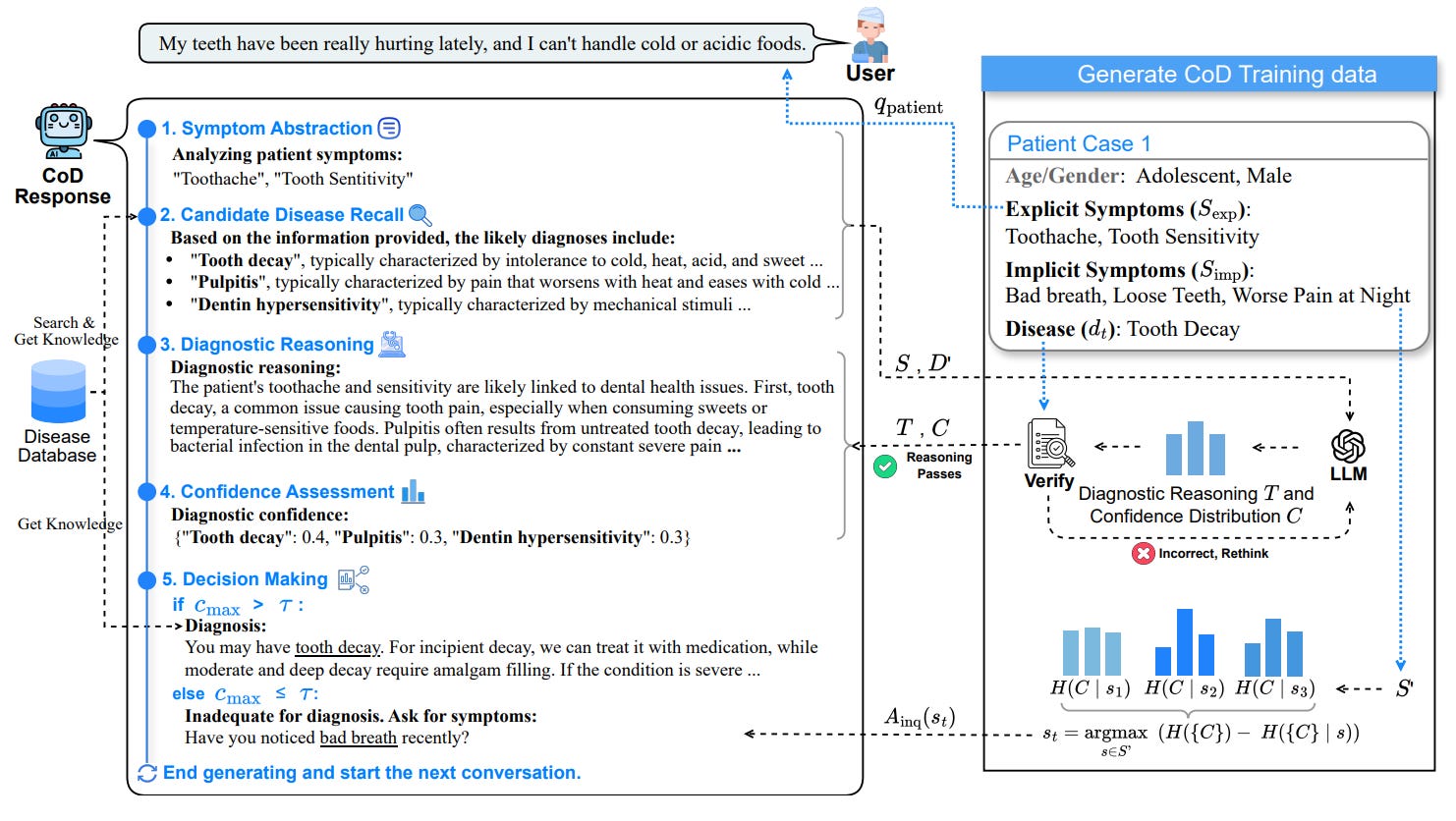
To implement the CoD, the researchers constructed CoD training data based on patient cases; they were able to construct a database containing 9,604 diseases and synthesized 48,020 unique cases (due to privacy concerns, real patient data access was limited). From there, they fine-tuned the Yi-34B-Base LLM to develop DiagnosisGPT, which takes given symptoms as input and outputs a chain-of-diagnosis (CoD) result.
DiagnosisGPT outperforms other LLMs on diagnostic benchmarks (based on real doctor-patient interaction data), including the best frontier LLMs. DiagnosisGPT provides interpretability while ensuring controllability in diagnostic rigor.