


AI Research Roundup 24.08.29
Surveys on Controllable Text Generation and Foundation Models for Music, WiM: Writing in the Margins, LSLM: LLMs can listen while speaking, code data in pre-training helps LLM performance.


Introduction
Here are our AI research highlights for this week, both surveys and new research on making LLMs better in multiple ways:
Controllable Text Generation for Large Language Models: A Survey
Foundation Models for Music: A Survey
Writing in the Margins: Better Inference Pattern for Long Context Retrieval
Language Model Can Listen While Speaking
To Code, or Not To Code? Exploring Impact of Code in Pre-training
Controllable Text Generation for Large Language Models: A Survey
The paper "Controllable Text Generation for Large Language Models: A Survey" by Liang et al. offers a comprehensive overview of the rapidly evolving field of Controllable Text Generation (CTG) with LLMs. CTG is the control of LLM text output so that it generates text that not only meets high-quality standards but also adheres to specific control conditions, such as safety guidelines, desired sentiment, or thematic focus.
The survey categorizes two primary types of Controllable Text Generation (CTG): Content control (managing specific textual elements like structure and vocabulary) and attribute control (governing abstract qualities like sentiment, style, and topic). The authors then detail the core methods employed in CTG, classifying them into training-stage methods (including retraining, fine-tuning, and reinforcement learning) and inference-stage methods (encompassing prompt engineering, latent space manipulation, and decoding-time intervention).

The survey covers the automatic, LLM-based and human-based approaches to evaluating CTG tasks, including the various evaluation metrics and benchmarks used. It also highlights the diverse applications of CTG across various domains. and presents future challenges in this advancing field. This broad review of CTG is a valuable resource for understanding and working with controllable text generation in LLMs.
Foundation Models for Music: A Survey
The paper "Foundation Models for Music: A Survey” provides a comprehensive overview of the current state of foundation models (FMs) in the music domain. The authors (many of them with the Centre for Digital Music at Queen Mary University of London) cover a wide range of topics in the 64-page survey, including music representations, the evolution of AI in music, technical details of foundation models, datasets, evaluation methods, and ethical considerations.
Music can be represented in many ways, from acoustic representations like spectrograms and MFCCs to symbolic representations like MIDI and ABC notation. The paper highlights the unique challenges of music data, including polyphonic signals, long durations, and high sample rates:
Unlike speech and language signals, music usually has several simultaneous “speakers”, and the “meaning” of what they “say” is not grounded in real-world objects or events. The occurrences of different note events are not independent, making it a challenging modelling task to capture the “language(s)” of music.
The authors explain the modalities targeted by foundation models and point out that “many of the music representations are underexplored in FM development.”

The survey describes technical details of music foundation models in depth, covering model design, tokenization, pre-training strategies, , finetuning methodologies, and adaptation techniques. As with LLMs, music FMs utilize self-supervised learning on large-scale datasets for pre-training. Several pre-training strategies are used for pre-training, including Contrastive Learning and Clustering, Generative Pre-training, and Masked Modelling.

Music FMs can perform a wide range of music-related tasks with impressive accuracy and efficiency, including music information retrieval (MIR) and text-to-music generation. However, the authors note these gaps in current understanding:
limited work has investigated the integration of music domain knowledge in the pre-training paradigm and the technique of instruction tuning remains largely unexplored.
The authors explore multimodal representations that combine music with other modalities such as text and images, and present challenges associated with evaluating music FM performance. They also discuss in depth the ethical and social implications of using foundation models in music, such as cultural impacts and copyright concerns, emphasizing the need for responsible development of these technologies.
This survey is a helpful and comprehensive guide for understanding AI foundation models for music.
Writing in the Margins: Better Inference Pattern for Long Context Retrieval
The paper “Writing in the Margins: Better Inference Pattern for Long Context Retrieval” introduces a novel inference pattern, Writing in the Margins (WiM), designed to enhance the handling of long input sequences in retrieval-oriented tasks for Large Language Models (LLMs).
The core idea behind WiM is to leverage the chunked prefill mechanism commonly used in LLMs to generate intermediate "margins" or extractive summaries at each step of the prefill process, akin to the human practice of making margin notes while reading long texts. Similar to "scratchpad" techniques that meticulously record then use step-by-step calculations, WiM then incorporates these margin notes into the final segment predictions, thereby improving long context comprehension.
The key advantage of WiM is that it adds minimal additional computation while significantly enhancing the performance of off-the-shelf LLMs without requiring fine-tuning.

The paper presents experimental results of using WiM on various long-context datasets, demonstrating its effectiveness:
Specifically, we observe that WiM provides an average enhancement of 7.5% in accuracy for reasoning skills (HotpotQA, MultiHop-RAG) and more than a 30.0% increase in the F1-score for aggregation tasks (CWE).
WiM also fits into an interactive retrieval design, providing end-users with real-time insights into the computational progress through streamed margin notes.
By generating and integrating intermediate summaries, WiM offers a promising inference-time approach to overcome the limitations of LLMs in processing long-context inputs. This work opens up new approaches for KV cache-aware prompting to improve reasoning capabilities and long context comprehension of LLMs.
The WiM implementation using Hugging Face Transformers library has been released on Github.
Language Model Can Listen While Speaking
The most natural way humans communicate is speech. This is why developers pursue ever-more natural speech interfaces, in audio-enabled chatbots, speech-enabled LLMs and Speech Language Models (SLMs). While early chatbots have been turn-based, GPT-4o’s voice mode recently attracted excitement for both its emotive voices and its ability to respond to getting interrupted, just like humans do.
The paper “Language Model Can Listen While Speaking” tackles the challenge of replicating that capability, known as 'full-duplex modeling' (FDM), which enables interactive conversations where the AI can be interrupted or given commands mid-speech, much like human conversations. To solve this challenge, it introduces listening-while-speaking language model (LSLM), a novel end-to-end speech language model capable of simultaneous listening and speaking:
Our LSLM employs a token-based decoder-only TTS for speech generation and a streaming self-supervised learning (SSL) encoder for real-time audio input. LSLM fuses both channels for autoregressive generation and detects turn-taking in real time.
The TTS component generates speech tokens autoregressively, while the SSL encoder processes incoming audio, allowing the model to 'listen' while 'speaking.' The fusion of these two channels, enabling real-time turn-taking detection, is explored through three strategies: Early, Middle, and Late Fusion.
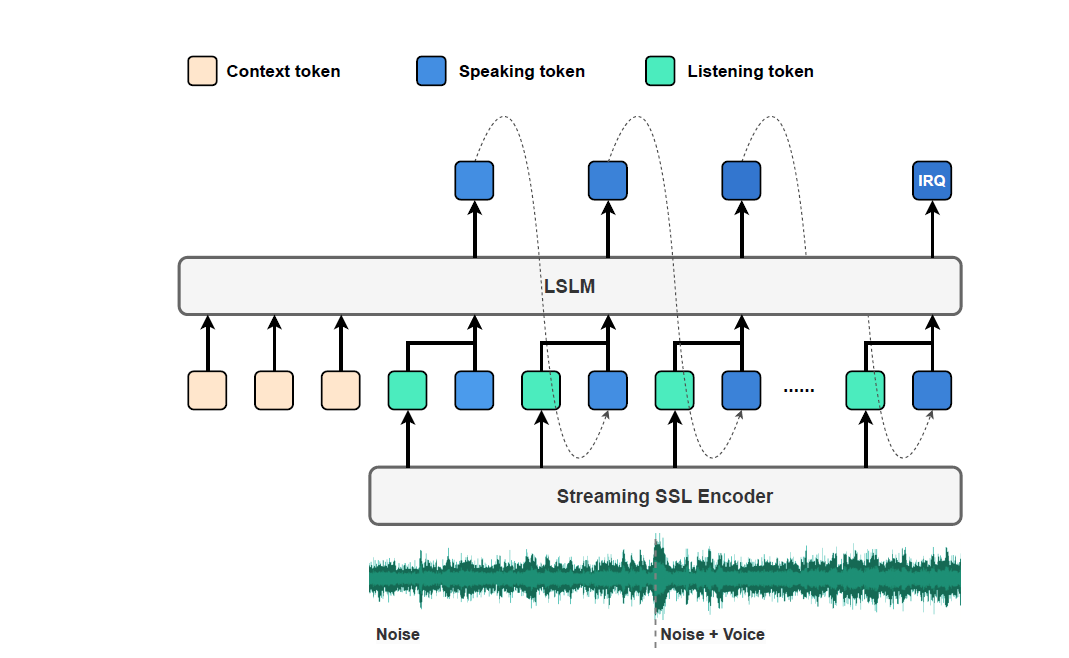
The authors evaluate LSLM in two scenarios: command-based FDM, where interruptions are limited to specific keywords, and voice-based FDM, where interruptions can be any word from unseen speakers. The model's performance is assessed based on its TTS capability (measured by word error rate or WER) and its interactive capability (measured by precision, recall, and F1 score).
The results demonstrate that LSLM with Middle Fusion “demonstrates a superior balance between speech generation and real-time interaction capabilities.” It effectively handles duplex communication with minimal impact on speech generation quality. It is robust in noisy environments and sensitive to diverse instructions, even from unfamiliar voices. The visualization of the IRQ (interruption) token probability further illustrates the model's internal mechanism for turn-taking detection.
LSLM represents a significant step towards more natural and interactive speech-based AI systems, and this result may help extend listening-while-speaking FDM capability to more AI models beyond GPT-4o.
To Code, or Not To Code? Exploring Impact of Code in Pre-training
The paper "To Code, or Not To Code? Exploring Impact of Code in Pre-training” investigates the effects of incorporating code data into the pre-training mix of LLMs, even when those models aren't specifically designed for code generation. The prevailing assumption by model developers is that code data enhances general LLM performance, but there's been limited research analyzing this impact, particularly on non-coding tasks.
To answer this question, the authors conducted extensive experiments, ablations and evaluations, focusing on the timing of code introduction, code proportions, scaling effects, and code quality. They evaluated models ranging from 470M to 2.8B parameters on diverse tasks, including natural language reasoning, world knowledge, code generation, and LLM-as-a-judge win rates.
Their findings consistently demonstrate that code data is crucial for improving performance beyond just coding tasks:
compared to text-only pre-training, the addition of code results in up to relative increase of 8.2% in natural language (NL) reasoning, 4.2% in world knowledge, 6.6% improvement in generative win-rates, and a 12x boost in code performance respectively.
Evaluations showed high-quality synthetic code and code-adjacent data like commits proved beneficial. Additionally, incorporating code during the 'cooldown' phase, where high-quality datasets are emphasized, further enhanced performance across all tasks.
The authors conclude that “investments in code quality and preserving code during pre-training have positive impacts.” They recommend including code in all pre-training phases, using a balanced mix initially, reducing the proportion during continued pre-training, and reintroducing it during cooldown.
This research supports the inclusion of code data in LLM pre-training even for general-purpose models, and it offers valuable insights into optimizing code data in pre-training to enhance LLM performance.