


AI Research Roundup 24.09.05
Sapiens Human Vision model, Law of Vision Representation, Project Sid, Automated Design of Agentic System (ADAS), Self-training algorithm for robots, Mixture-of-Domain-Experts, OLMoE-1B-7B.


Summary
Our weekly AI Research Roundup covers major trends and important papers to explain AI research progress. However, with over 600 AI research papers published on Arxiv every week, we can only report a sample of AI research results.
It is often unclear which specific papers will be most impactful and ‘stand the test of time.’ Many results are incremental, not fundamental; an outside-the-box result may end up either profoundly important or a dead end.
Here’s this week’s AI research results and papers we review below:
Specific (e.g., human) and scalable vision representations for multi-modal LLMs:
Sapiens: Foundation for Human Vision Models
Law of Vision Representation in MLLMs
Simulated communities of AI agents with Project Sid.
Better algorithms to train robots and automatically build agentic systems:
Automated Design of Agentic Systems
Practice makes perfect with "Estimate, Extrapolate, and Situate" Self-Training Algorithm for Robots
Improved use of MoE (mixture-of-experts) to build efficient AI models:
Flexible and Effective Mixing of Large Language Models into a Mixture of Domain Experts
OLMoE (Open Mixture-of-Experts Language Models)
The larger AI research trend is in two main directions:
Continued innovation in foundation AI models: training algorithms, architectures, dataset innovations and modalities (like vision).
Broadening AI model applications and use: Specific domain applications, multi-modal uses, AI agent systems, robotics.
There is a third dimension - scale; it’s not just research, but investment that dictates progress. I do my best each week to show solid research that indicates the shape of AI progress overall, but the truly big picture is that AI progress is relentless and rapid.
Sapiens: Foundation for Human Vision Models
Researchers at Meta recently released Sapiens, a model family for human-centric vision tasks, and the associated paper “Sapiens: Foundation for Human Vision Models.” The Sapiens models natively support 1K high-resolution inference and handle four human-centric vision tasks: 2D pose estimation, body-part segmentation, depth estimation, and surface normal prediction.
They built Sapiens using a dataset of over 300 million in-the-wild human images, using a masked-autoencoder approach to pretrain the model in a self-supervised manner. They built models that scaled from 0.3B to 2B, and the Sapiens models could generalize across a variety of in-the-wild face, upper-body, full-body, and multi-person images, surpassing previous state-of-the-art baselines for the four tasks.

The learning from this is that significant and specific data, including synthetic data, tailored for specific tasks, can lead to an excellent AI model for those tasks. The Sapiens project page is at Meta’s Reality Labs.
Law of Vision Representation in MLLMs
The paper Law of Vision Representation in MLLMs investigates the key factors of vision representation that impact MLLM performance. It aims to explain that impact MLLM benchmarks performance.
Through extensive experiments and evaluations, they found that cross-modal Alignment and Correspondence (AC) of the vision representation are strongly correlated with model performance:
Specifically, an increase in the AC of the selected vision representation leads to improved model performance. To quantify this relationship, we define an AC score that measures cross-modal alignment and correspondence in vision representation. The AC score and model performance exhibit a linear relationship, with a coefficient of determination of 95.72%.
From this they develop their "Law of Vision Representation" that states that the performance of a MLLM, denoted as Z, depends on two factors, cross-modal alignment (A) and correspondence (C) of the vision representation:
Z ∝ f(A, C)
Currently, developers of multi-modal LLMs empirically test different vision representations to pick the best one based on benchmarks. By leveraging this Law of Vision Representation relationship, MLLM developers can identify and train the optimal vision representation only, with high AC scores, saving a large search-space exploration. This results in a significant 99.7% reduction in computational cost for model training.
Project Sid: Autonomous AI Agents in Minecraft
Project Sid is an experiment by Altera AI that simulated 1,000 autonomous agents collaborating in a Minecraft-based virtual world. News about Project Sid was shared by their CEO Robert Yang on X.
Altera is an AI company “Building digital human beings that live, love, and grow with us. Starting in gaming.” ( Note, they are not the programmable chip maker Altera owned by Intel.) They created “truly autonomous AI Agents,” which Altera defines as: Long-term autonomous; organizational and collaborative; pro-human motivated; communicative of conscious thoughts and feelings.
As with other experiments with communities of AI agents, surprising things happened:
We saw agents form a merchant hub, vote in a democracy, spread religions, & collect 5x more distinct items than ever before.
Like GameNGen (AI creating DOOM on the fly) shared last week, this kind of project sparks a lot of imagination about how games, simulations, and environments might be created in the future. It also raises questions, that Robert Yang poses, about the future of AI agents:
(1) How can we meaningfully measure true long-term progression in a general way?
(2) How to build agents that actually care about human growth?
(3) How to build machines consciously aware of their actions and the consequences?
(4) How far can we scale an AI civilization?

Automated Design of Agentic Systems
The history of machine learning teaches us that hand-designed solutions are eventually replaced by learned solutions.
The paper Automated Design of Agentic Systems introduces Automated Design of Agentic Systems (ADAS) as a novel research area: The automatic creation of powerful AI agent systems. Since AI is now helping write code, brainstorm on research, find new drugs, etc. why not use AI to help architect new AI agent systems?
The core idea of ADAS is to define agents using code and then employ a "meta-agent" to iteratively generate and refine new agents within this code space, leveraging previously discovered agents:
We present a simple, yet effective algorithm named Meta Agent Search to demonstrate this idea, where a meta-agent iteratively programs interesting new agents based on an ever-growing archive of previous discoveries. Through extensive experiments across multiple domains including coding, science, and math, we show that our algorithm can progressively invent agents with novel designs that greatly outperform state-of-the-art hand-designed agents.

The authors show that that agents invented by Meta Agent Search maintain superior performance across domains and models.
The authors also note that since programming languages are Turing Complete, this approach theoretically enables learning any possible agentic system, including novel prompts, tool use, control flows, and combinations. Encoding a system design generation task as an AI code generation task is a general concept that is applicable to complex system design across many engineering fields.
ADAS can help us accelerate the development of powerful AI agents and to gain deeper insights into the capabilities of foundation models.
Practice Makes Perfect with Self-Training Algorithm for Robots
Researchers from MIT CSAIL and the AI Institute present a groundbreaking algorithm to help robots self-train on skills in “Practice Makes Perfect: Planning to Learn Skill Parameter Policies,” presented recently at Robotics Science and Systems (RSS) 2024. The article “Helping robots practice skills independently to adapt to unfamiliar environments” explains further:
A new algorithm helps robots practice skills like sweeping and placing objects, potentially helping them improve at important tasks in houses, hospitals, and factories.
The authors define the algorithm "Estimate, Extrapolate, and Situate" (EES), which allows robots to train themselves through a method of self-guided learning. EES has several steps:
1. Estimate / select: The robot selects skills to practice based on estimated skill improvement.
2. Situate / practice: Robot plans and initiates conditions to practice skill, then engages in practice.
3. Extrapolate / update: Results of practice to update parameter policy to improve skill.
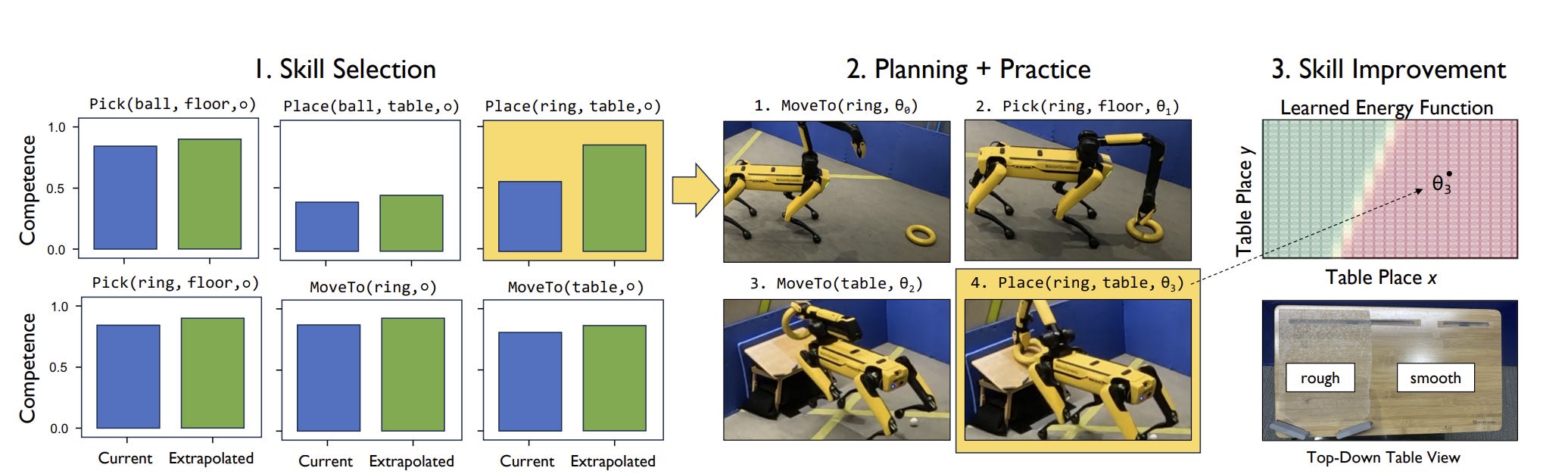
By mimicking a 'practice makes perfect' approach, the "Estimate, Extrapolate, and Situate" (EES) algorithm can significantly reduce time and effort needed for robotic training. One use case is to help a robot understand granular details of its skills in an actual environment, ‘fine-tuning’ the robot for real use.
Addressing future work, the authors consider using simulated training; they suggest a “future direction that could address multiple limitations simultaneously would be to give the agent access to a simulator.”
Mixing LLMs to make a Mixture of Domain Experts
The paper “Flexible and Effective Mixing of Large Language Models into a Mixture of Domain Experts” from IBM presents a toolkit to create Mixture-of-Domain-Experts (MOE) models from pre-trained LLMs. Mixture-of-Domain-Experts draws inspiration from mixture-of-experts (MoE) architecture and model merging techniques.
They create a toolkit that combines existing LLMs together into a merged MoE architecture language model. They introduce two specific MOE architectures: the Gate-less MOE, which assigns equal weight to all expert models, and the Noisy MOE, which employs a randomized “top K” expert selection strategy.
The toolkit enables the creation of MOEs that leverage the specialized knowledge of different models, thereby enhancing the performance of the base model across various domains:
We perform extensive tests and offer guidance on defining the architecture of the resulting MOE using the toolkit.
They show that “Mixed MOEs can perform better than the baselines and constituent experts,” as expected and hoped. The paper also discusses the potential benefits of router training and provides the option to train routers or a combination of routers and embedding layers within the toolkit.
OLMoE (Open Mixture-of-Experts Language Models)
Allen AI has introduced OLMoE (Open Mixture-of-Experts Language Models), fully open LLMs that leverages a mixture-of-experts approach, and released OLMoE-1B-7B, that has seven billion (B) parameters but uses only 1B active parameters on input.
They report on OLMoE in “OLMoE: Open Mixture-of-Experts Language Models,” a 61-page technical report. They share details on the 5T token pre-training dataset, describe training settings and process, analyze MoE architecture and present performance results.

OLMoE-1B-7B-Instruct achieves an MMLU score of 54.1, showing decent performance for having only 1B active parameters:
Our models outperform all available models with similar active parameters, even surpassing larger ones like Llama2-13B-Chat and DeepSeekMoE-16B.
As a small language model, it serves more as a proof-of-concept than competitive LLM. However, the most appealing part of the work of researchers at Allen Institute for AI is that they open-source all their work: model weights and training data on HuggingFace, code on GitHub, and even share training logs, etc. so that others can build on what they’ve done.