


AI Research Roundup 24.09.12
Llama-Omni, Attention heads, Unified View of Preference Learning, scalable IRL for LLM training, OneGen one-pass retrieval and generation, role of in-context learning.


Introduction
Our AI research highlights for this week focus on LLMs:
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
Attention Heads of Large Language Models: A Survey
Towards a Unified View of Preference Learning for LLMs
Imitating Language via Scalable Inverse Reinforcement Learning
OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs
Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs
LLaMA-Omni: Seamless Speech Interaction with Large Language Models
LLaMA-Omni is a new audio-to-audio speech language model designed to interact by voice in the style of GPT-4o voice-mode. The research behind this speech LLM is presented in “LLaMA-Omni: Seamless Speech Interaction with Large Language Models.”
LLaMA-Omni is not built as a speech AI model from the ground up. It is instead based on Llama 3.1 8B and integrates a pretrained speech encoder, a speech adaptor, and a streaming speech decoder around the LLM. The result is an AI model that takes spoken input and encodes speech output as soon as each (text) token is generated; this produces spoken responses with extremely low latency - as low as 226ms.
They used a dataset of 200K speech instructions and responses to align the model to speech interaction, which took takes less than 3 days on just 4 GPUs. This low-cost alignment is very promising for future open weights voice-mode LLMs, including ones you can run locally. Llama-3.1-B-Omni is an open weights LLM available on Hugging Face.

Attention Heads of Large Language Models: A Survey
the survey paper “Attention Heads of Large Language Models: A Survey” by Tsinghua University researchers aims to advance understanding of the internal mechanisms of LLMs. It concentrates on the interpretability and underlying mechanisms of attention heads, the key component in transformer architectures LLMs. Attention heads help LLMs recall information, connect various disparate pieces of information together, reason on it, and generate relevant output. Attention heads help LLMs “think.”
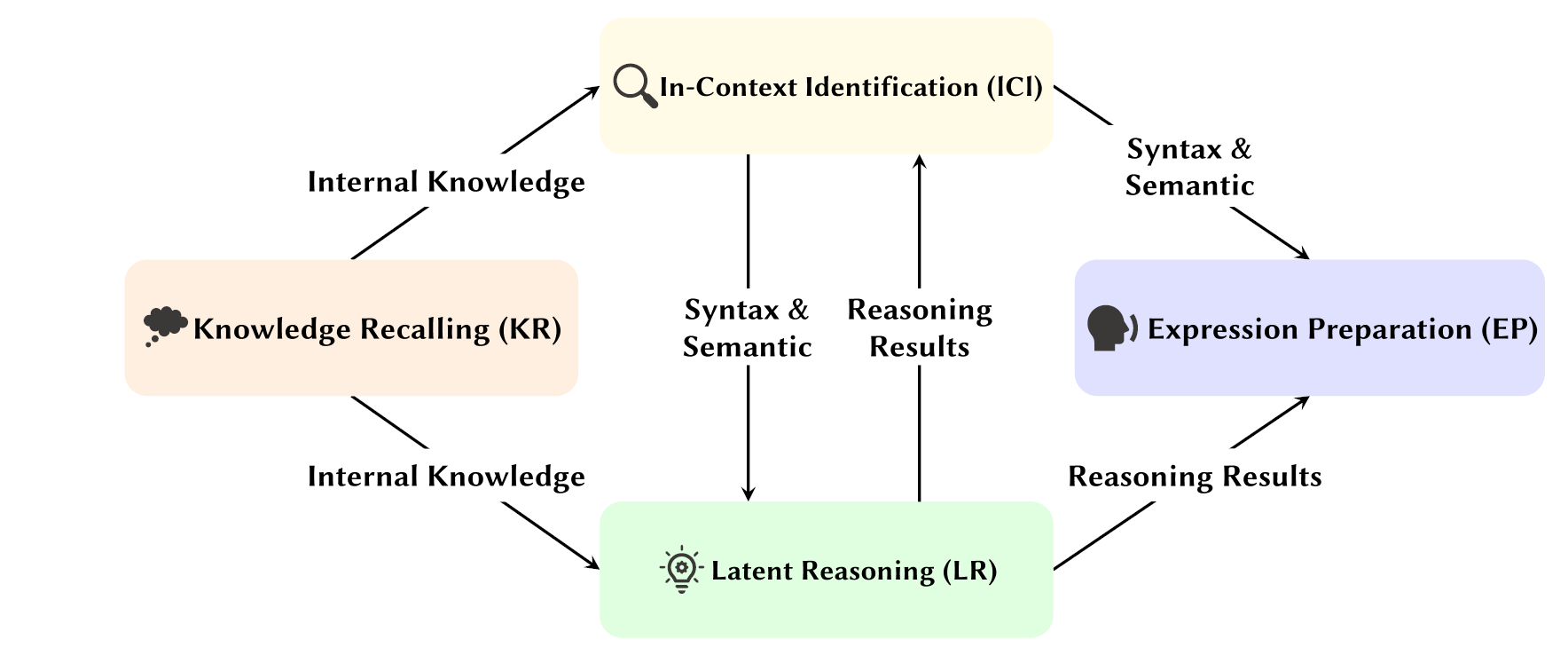
The survey describes the LLM thought process in human cognition terms, as a four-stage framework: Knowledge Recalling, In-Context Identification, Latent Reasoning, and Expression Preparation. From this, they review the current research to further categorize the functions and behavior of specific attention heads in LLMs. In a deep learning network like an LLM, the roles attention heads play in models depend on their depth in the network.

We are just beginning to understand the internal mechanisms of LLMs. This survey shows the progress made and makes great strides in explaining role of attention, but it also shows how much further we need to go in LLM interpretability.
Towards a Unified View of Preference Learning for LLMs
The paper “Towards a Unified View of Preference Learning for Large Language Models: A Survey” from Alibaba and Peking University surveys the task of aligning LLM output to human preferences.
New strategies, algorithms and datasets in this area have evolved rapidly, but the authors note:
While effective, research in this area spans multiple domains, and the methods involved are relatively complex to understand. The relationships between different methods have been under-explored, limiting the development of the preference alignment.
Their contribution is a unified framework to better understand the current alignment strategies and how different approaches relate. They decompose alignment into four components: model, data, feedback, and algorithm.
Within each of these categories, there are many approaches: For example, feedback can be human (RLHF), LLM-as-judge (RLAIF), rule-based, etc. They detail various feedback methods and algorithms in depth.
They also compare the various loss functions for the different algorithms, such as DPO, PPO, IPO, ORPO, etc. They note the objectives of RL and SFT methods can all be described in the same framework, and also observe:
We believe that although the core objectives of these alignment algorithms are essentially similar, their performance can vary significantly across different application scenarios.
This unified view is helpful for understanding where the different approaches stand relative to each other. It also opens up possibilities to synergize different alignment strategies to combine their strengths.
Imitating Language via Scalable Inverse Reinforcement Learning
Google Deepmind author Markus Wulfmeier explains their latest paper on X:
Imitation is the foundation of #LLM training. And it is a #ReinforcementLearning problem! Compared to supervised learning, RL -here inverse RL- better exploits sequential structure, online data and further extracts rewards.
The paper “Imitating Language via Scalable Inverse Reinforcement Learning” looks at the basis of LLM training - imitation learning:
The simplicity and scalability of maximum likelihood estimation (MLE) for next token prediction led to its role as predominant paradigm. However, the broader field of imitation learning can more effectively utilize the sequential structure underlying autoregressive generation.
In particular, there are inverse reinforcement learning (IRL) techniques that can operate “directly optimizing sequences instead of individual token likelihoods” and could be more general:
We provide a new angle, reformulating inverse soft-Q-learning as a temporal difference regularized extension of MLE. This creates a principled connection between MLE and IRL and allows trading off added complexity with increased performance and diversity of generations in the supervised fine-tuning (SFT) setting.
What they find is IRL extends MLE to a more comprehensive optimization that produces better results. Through training and experiments, they show that there were clear advantages for IRL-based imitation, with improved task performance for models trained on IRL.
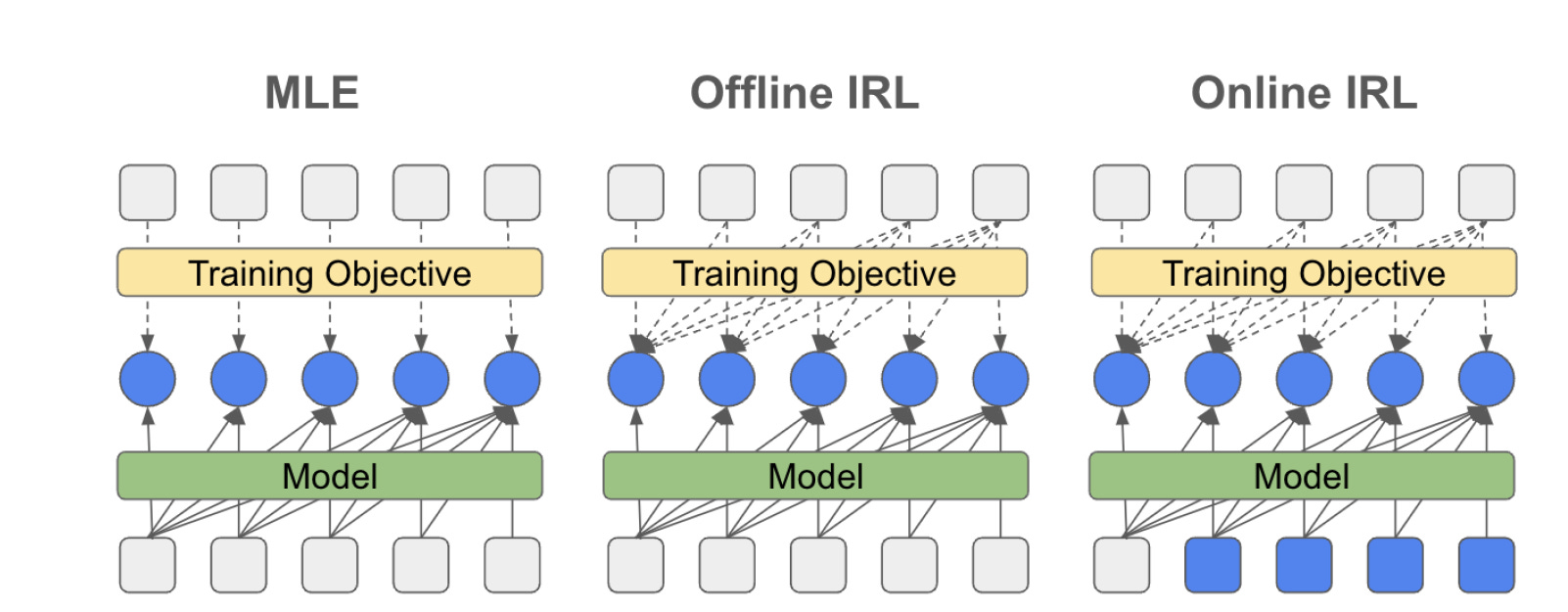
This approach bridges approaches used in pre-training and preference-based alignment. As such, it has benefits in tighter integration of supervised and preference-based LLM post-training, allowing for more robust reward functions throughout the training process.
OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs
The paper OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs presents a powerful and novel idea: Integrated retrieval and generation in an LLM. OneGen replaces the sequential RAG process with a single-pass generation and retrieval framework:
The proposed OneGen framework bridges the traditionally separate training approaches for generation and retrieval by incorporating retrieval tokens generated autoregressively. This enables a single LLM to handle both tasks simultaneously in a unified forward pass.
This could be viewed as a ‘just-in-time’ form of RAG, calling on retrieval information when needed. This makes the retrieval more precise to the generation task at hand.
Furthermore, our results confirm that integrating generation and retrieval within the same context does not negatively impact the generative capabilities of LLMs, while also providing significant enhancements in retrieval capabilities.
LLMs have been trained to generate tokens for other uses beyond output text: reflection, verify facts, tool use, etc. Using it for factual retrieval tasks inline is a natural extension of this trend.
Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs
In-context learning in LLMs, while powerful, is not fully understood. The paper Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs studies in-context learning (ICL) in LLMs, and and argues that ICL uses a combination of both learning from in-context examples and retrieving internal knowledge:
In this work, we propose a framework for evaluating in-context learning mechanisms, which we claim are a combination of retrieving internal knowledge and learning from in-context examples by focusing on regression tasks.
They study multiple LLMs and datasets, showing that LLMs can learn from regression examples of realistic datasets in-context, and they measure the extent to which the LLM retrieves its internal knowledge versus learning from in-context examples.
They also offer insights on prompt engineering methods that leverage understanding of in-context learning mechanisms, which can optimize knowledge retrieval and improve application results.