

AI Research Roundup 24.10.18 - Video and multimodality
Multimodal LLM benchmarks: MMIE, HumanEval-V, MixEval-X. AI video generation: MovieGen, PyramidFlow. Multimodal LLMs: Emu3, MIO, MM-1.5. DepthPro for depth perception.

Introduction
This week, our Research Roundup covers multi-modality and AI video generation models.
We have three papers on multi-modal LLM Benchmarks:
MMIE: Massive Multimodal Interleaved Comprehension Benchmark for Large Vision-Language Models
HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks
MixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures
We have 6 papers on AI video generation models, multi-modal LLMs, and a depth perception model:
Movie Gen: A Cast of Media Foundation Models
Pyramidal Flow Matching for Efficient Video Generative Modeling
Emu3: Next-Token Prediction
MIO: A Foundation Model on Multimodal Tokens
MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Benchmarks for multi-modal LLMs
New multi-modal LLMs that can comprehend both visual and textual inputs are advancing rapidly. These AI models are outpacing benchmarks, which suffer from limitations in data scale, scope, and evaluation depth, or lack reliability for practical applications. This has led to several efforts at developing new benchmarks for Vision-Language Models (VLMs) and multimodal LLMs.
One such new benchmark is MMIE, described in MMIE: Massive Multimodal Interleaved Comprehension Benchmark for Large Vision-Language Models:
MMIE comprises 20K meticulously curated multimodal queries, spanning 3 categories, 12 fields, and 102 subfields, including mathematics, coding, physics, literature, health, and arts. It supports both interleaved inputs and outputs, offering a mix of multiple-choice and open-ended question formats to evaluate diverse competencies.
The new HumanEval-V benchmark is a code generation benchmark that evaluates visual understanding and reasoning capabilities and is described in HumanEval-V: Evaluating Visual Understanding and Reasoning Abilities of Large Multimodal Models Through Coding Tasks. HumanEval-V is intended to address a lack of coding benchmarks that assess models on translating visual reasoning into code.
HumanEval-V includes 108 carefully crafted, entry-level Python coding tasks derived from platforms like CodeForces and Stack Overflow. Each task is adapted by modifying the context and algorithmic patterns of the original problems, with visual elements redrawn to ensure distinction from the source, preventing potential data leakage. LMMs are required to complete the code solution based on the provided visual context and a predefined Python function signature outlining the task requirements. Every task is equipped with meticulously handcrafted test cases to ensure a thorough and reliable evaluation of model-generated solutions.
They evaluated 19 LMMs with HumanEval-V and found models like GPT-4o achieved only 13% pass@1, while open-weight models with 70B parameters scored below 4% pass@1. Thus, even state-of-the-art multimodal LMMs have room for much improvement in vision reasoning for coding.
The paper MixEval-X: Any-to-Any Evaluations from Real-World Data Mixtures identifies two major issues in current evaluations:
Inconsistent standards, shaped by different communities with varying protocols and maturity levels; and
Significant query, grading, and generalization biases.
They introduced MixEval-X, an any-to-any real-world benchmark, to address these issues and optimize and standardize evaluations across input and output modalities:
Extensive meta-evaluations show our approach effectively aligns benchmark samples with real-world task distributions and the model rankings correlate strongly with that of crowd-sourced real-world evaluations (up to 0.98).
No benchmark can ever fully represent all real-world use cases, which is why it is necessary to assess AI models by running it on your own workloads. This work to align benchmarks to the real-world use is a worthwhile complement.
Movie Gen: A Cast of Media Foundation Models
MovieGen is an AI video generation system capable of generating high-quality videos with sound from text descriptions, that also has powerful text-based video editing features. The developers of MovieGen at Meta shared how they made Movie Gen in a paper, and they posted the paper “Movie Gen: A Cast of Media Foundation Models” to Arxiv.
MovieGen consists of two models, MovieGen Video and MovieGen Audio:
Movie Gen Video: A 30B parameter foundation model for joint text-to-image and text-to-video generation that generates high-quality HD videos of up to 16 seconds duration that follow the text prompt. The model naturally generates high-quality images and videos in multiple aspect ratios and variable resolutions and durations.
Movie Gen Audio: A 13B parameter foundation model for video- and text-to-audio generation that can generate 48kHz high-quality cinematic sound effects and music synchronized with the video input and follow an input text prompt.
The video generation model was pre-trained jointly on about 100 million videos and a billion images that came from licensed and publicly available datasets. The architecture is a joint video and image generation model, combining diffusion models with LLM training and introducing Flow Matching.
MovieGen has features beyond text-to-video generation: Personalization conditions a video on an image, for example to use an image of person to appear in a video; text-based video-to-video editing can edit videos based on instructions; most impressively, it MovieGen Audio can add soundtrack effects to video, generating audio that is coherent with the video context.
MovieGen is very impressive, especially thanks to adding editing and personalization features natively to AI video generation models, but it is not yet released, so it is hard to assess its quality ‘in the wild.’ However, Meta’s technical report on MovieGen ran 96 pages, with extreme detail on its performance on many specific tasks. It sets a standard for competing AI video generation model makers to match.

Pyramidal Flow Matching for Efficient Video Generative Modeling
Many high-quality AI video generation models have been released this year, but with the exceptions such as recently released PyramidFlow, most are closed source. This makes the exceptional papers explaining technical details of state-of-the-art AI video generation valuable.
The paper Pyramidal Flow Matching for Efficient Video Generative Modeling, by researchers from Chinese Universities, presents a computationally efficient method for AI video generation without sacrificing quality. Existing methods spend a lot of computation on very noisy latent spaces, which is computationally expensive, or employ a cascaded architecture to avoid direct training with full resolution, which sacrifices flexibility.
The authors’ solution is a pyramidal flow matching algorithm:
This work introduces a unified. It reinterprets the original denoising trajectory as a series of pyramid stages, where only the final stage operates at the full resolution, thereby enabling more efficient video generative modeling. Through our sophisticated design, the flows of different pyramid stages can be interlinked to maintain continuity. Moreover, we craft autoregressive video generation with a temporal pyramid to compress the full-resolution history.
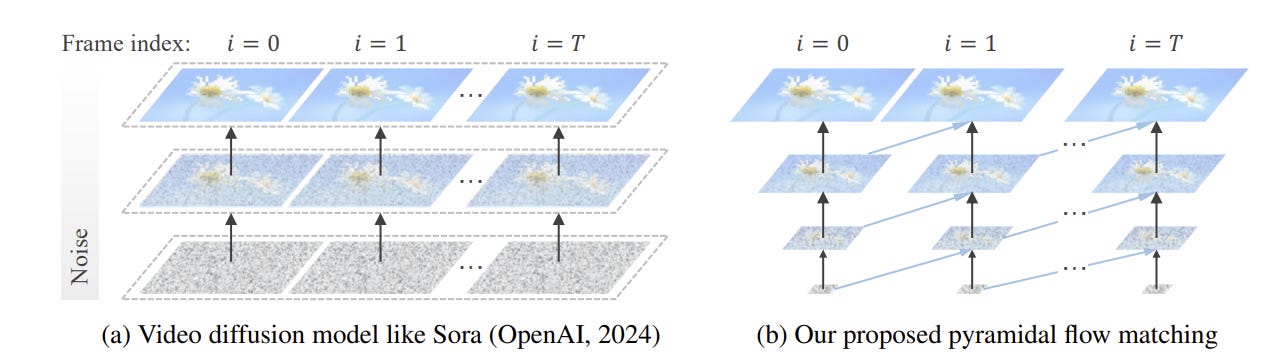
Pyramid Flow can be implemented in a single unified Diffusion Transformer (DiT), and it can be trained more efficiently than full-res video generation model. The resulting model is high-quality and efficient, generating high-quality 5-second videos at 768p resolution and 24 FPS.

Emu3: M-modal Next-Token Prediction
Emu3 is a new multimodal model that uses next-token prediction for image, text, and video tasks. Emu3 outperforms traditional models like SDXL and LLaVA-1.6 without relying on diffusion or compositional approaches. It’s presented in the paper Emu3: Next-Token Prediction is All You Need.
The Emu3 multi-modal model retains the transformer architecture of established text-only LLMs, while expanding the embedding layer to accommodate discrete vision tokens, while avoiding composition approaches (such as CLIP combined with LLMs):
By tokenizing images, text, and videos into a discrete space, we train a single transformer from scratch on a mixture of multimodal sequences. Emu3 outperforms several well-established task-specific models in both generation and perception tasks, surpassing flagship models such as SDXL and LLaVA-1.6, while eliminating the need for diffusion or compositional architectures.
One surprising benefit of this is that Emu3 can generate video and images via next-token prediction, making the multi-modal representation and generation more seamless.

MIO: A Foundation Model on Multimodal Tokens
The paper MIO: A Foundation Model on Multimodal Tokens presents the MIO foundation model, that processes and generates multimodal content, including speech, text, images, and videos, using multimodal tokens.
To enable interleaved any-to-any multi-modal generation, MIO is trained on a mixture of tokens across four modalities in a 4-step process:
alignment pre-training,
interleaved pre-training,
speech-enhanced pre-training, and
comprehensive supervised fine-tuning on diverse textual, visual, and speech tasks.
This special training process gives MIO advanced multi-modal capabilities, such as interleaved video-text generation, chain-of-visual-thought reasoning, visual guideline generation, and guided image editing.
Our experimental results indicate that MIO exhibits competitive, and in some cases superior, performance compared to previous dual-modal baselines, any-to-any model baselines, and even modality-specific baselines.

MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning
MM1.5 is a family of multimodal LLMs focused on improving text-rich image understanding (including OCR), visual grounding, and multi-image reasoning. Developed by researchers at Apple, MM1.5 is presented in the paper MM1.5: Methods, Analysis & Insights from Multimodal LLM Fine-tuning.
MM1.5 builds on MM1architecture and includes models of sizes 1B, 3B, 7B, and 30B parameters, all dense models with some mixture-of-experts (MoE) variants. They also introduced two specialized variants: MM1.5-Video, designed for video understanding, and MM1.5-UI, tailored for mobile UI understanding.
They trained MM1.5 using careful data curation on a mix of multi-modal data. Pre-training data consists of 2B image-text pairs, 600M interleaved image-text documents with 1B images in total, and 2T tokens of text-only data. This was followed by continued pre-training with OCR data to enhance text-rich image understanding.
This work shows that Apple is continuing to put their AI research effort into smaller multi-modal AI models, suitable for AI applications and services on smartphones.

Depth Pro: Sharp Monocular Metric Depth in Less Than a Second
Researchers at Apple developed Depth Pro, which can generate sharp depth estimates from images in under a second. Depth Pro is a new foundation model for monocular depth estimation that can synthesize high-resolution depth maps with absolute scale and high-frequency details, without requiring camera intrinsics. It is fast, producing a 2.25-megapixel depth map in 0.3 seconds on a standard GPU.
This is achieved through several technical contributions: an efficient multi-scale vision transformer for dense prediction, a training protocol combining real and synthetic datasets, new evaluation metrics for boundary accuracy, and focal length estimation from a single image. Depth Pro outperforms previous methods in terms of boundary accuracy and speed, while maintaining competitive metric depth accuracy.
