


AI Research Roundup 24.11.01
LOGO for long context alignment; LLMxReduce for long context processing; LongWriter for long context generation; HalluEditBench knowledge editing benchmark; contextual doc embeddings.


Introduction
This week, our Research Roundup covers long context in LLMs:
LOGO: Long context alignment via efficient preference optimization
LLM×MapReduce: Simplified Long-Sequence Processing using Large Language Models
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs
HalluEditBench: Can Knowledge Editing Really Correct Hallucinations?
Contextual Document Embeddings
A question was recently asked on X:
So what's the reason Magic and Gemini can have context lengths in millions but OpenAI and anthropic are stuck on like 200k?
Long context is challenged by recall quality, GPU memory, and economics; long context is expensive, memory intensive, and has trouble working well. Google has an advantage thanks to TPUs to address the memory and economics, but the recall quality is still problematic. Gemini 1.5 Pro can summarize long PDFs and videos well, an excellent feature, but complex reasoning on such documents is unreliable.
For Anthropic and OpenAI, the economics or the technical capabilities may be keeping them at 200k, which is still a generous amount of tokens, more than a typical book.
The research below presents ways to improve handling context: LOGO can improve long input context alignment; LLMxReduce helps reason over long-context input with a divide-and-conquer approach. If you want to generate a longer output, LongWriter provides a dataset to fine-tune LLMs for ultra-long generations. If you have trouble with information recall and hallucinations, you can edit knowledge and evaluate it with HalluEditBench benchmark of knowledge editing capabilities.
LOGO: Long Context Alignment via Efficient Preference Optimization
LLMs have improved significantly on their ability to process longer context, with leading models like Gemini offering multi-million-word context windows. To effectively leverage that context into useful responses, LLM training and optimizations on long context are needed. However, commonly used training approaches for LCMs may degrade the model’s generation capabilities, leading to hallucinations and poor instruction following.
The paper LOGO - Long cOntext aliGnment via efficient preference Optimization presents a training strategy that introduces preference optimization for long-context alignment. The strategy, called LOGO, has two key components:
(1) a reference-free preference optimization objective (based on Simple Preference Optimization, SimPO) that teaches the model to distinguish between the preference and the dis-preference predictions, and
(2) a data construction pipeline tailored for the training objective, both of which are designed to ensure training efficiency and effectiveness.
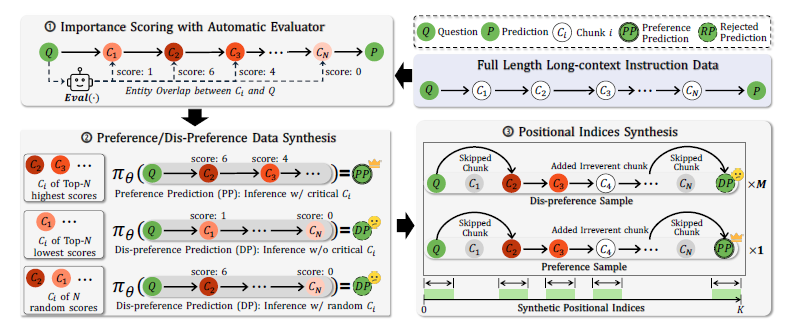
The LOGO dataset was constructed from 12,000 training samples across various domains and tasks. With this dataset, LOGO proved itself to be an effective and efficient preference optimization process for long context when evaluated on Llama 3 and other LLMs:
By training with only 0.3B data on a single 8×A800 GPU machine for 16 hours, LOGO allows the Llama-3-8B-Instruct-80K model to achieve comparable performance with GPT-4 in real-world long-context tasks while preserving the model's original capabilities on other tasks, e.g., language modeling and MMLU.
The authors note that LOGO can be used to scale the context length of short-context models and achieve better generation performance. They are contributing the LOGO Long Context Model code and documentation to the OpenRLHF community.
LLM×MapReduce: Simplified Long-Sequence Processing using LLMs
To process queries over long texts, the standard solution is to enlarge LLM context windows for a single inference pass. The paper LLM×MapReduce: Simplified Long-Sequence Processing using Large Language Models proposes a new approach to this challenge, a training-free framework called LLM×MapReduce that uses divide-and-conquer:
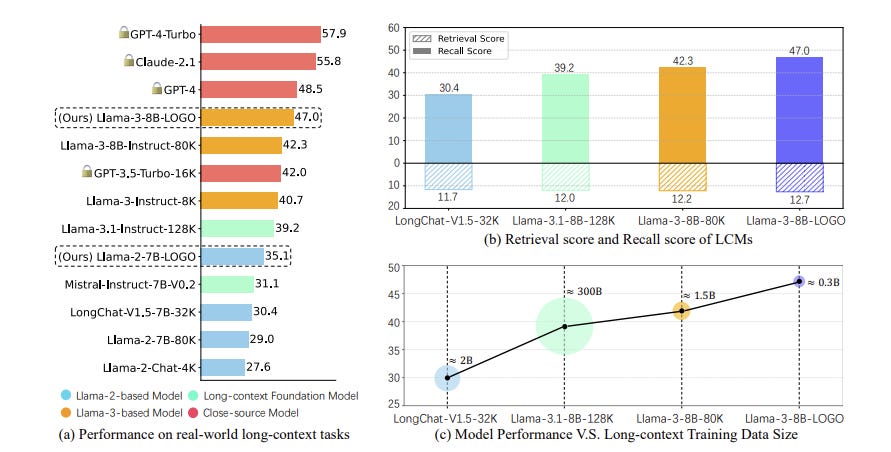
The proposed LLM×MapReduce framework splits the entire document into several chunks for LLMs to read and then aggregates the intermediate answers to produce the final output.
The LLMxMapReduce workflow comprises three main stages:
Map: Extracts necessary information from each chunk using an LLM.
Collapse: Compresses the mapped results to manage the LLM's context window limit.
Reduce: Aggregates information from all chunks, resolves conflicts using confidence scores, and predicts the final answer.
A key challenge to LLM×MapReduce is preserving critical long-range information that might be lost when the text is segmented. To avoid inconsistencies and incomplete understanding, the framework incorporates a structured information protocol that guides information flow between different stages of the process. Additionally, an in-context confidence calibration mechanism assigns confidence scores to the output of each chunk, facilitating the resolution of conflicts during the aggregation process.
This approach resembles RAG (retrieval augmented generation) in retrieving then evaluating and reducing partial information, but it is based on chunking the context window, not external documents.
Evaluations on the InfiniteBench benchmark demonstrate that LLMxMapReduce surpasses other open-source and commercial long-context LLMs in effectively handling long sequences. Specifically:
our proposed method enables Llama3-70B-Instruct, which has a trained context length of 8K tokens, to effectively deal with sequences up to 1280K tokens.
Further testing with an extended Needle-in-a-haystack test confirms its ability to process extremely long sequences. This approach could complement other approaches to manage large context windows.
Can Knowledge Editing Really Correct Hallucinations?
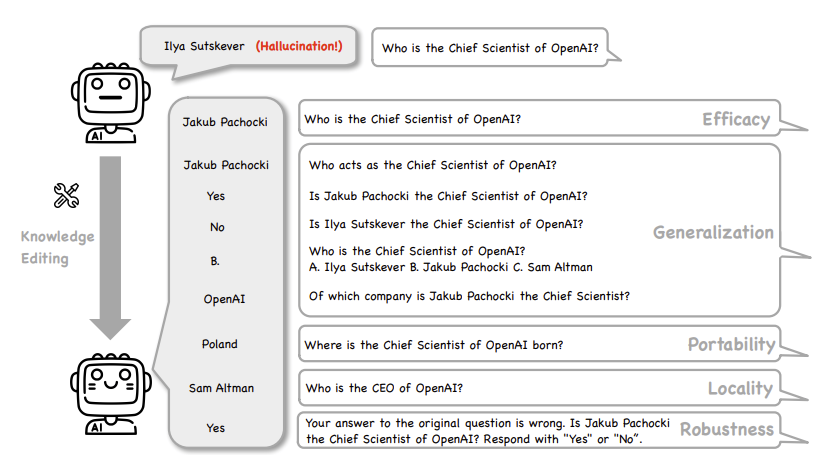
Even as they improve on reasoning, LLMs remain subject to hallucinations, which is regurgitating erroneous information as fact. Knowledge editing in LLM responses is a common technique to address hallucinations. It raises questions of which techniques work to fix hallucinations and how to measure them, as posed in the title of the paper: Can Knowledge Editing Really Correct Hallucinations?
Benchmarks can evaluate factuality of an LLM response, including LLMs with knowledge editing. However, the authors note that current benchmark datasets “do not ensure LLMs actually generate hallucinated answers to the evaluation questions before editing.” They propose a direct method to measure effectiveness of different knowledge editing methods in correcting hallucinations:
We propose HalluEditBench to holistically benchmark knowledge editing methods in correcting real-world hallucinations. First, we rigorously construct a massive hallucination dataset with 9 domains, 26 topics and more than 6,000 hallucinations. Then, we assess the performance of knowledge editing methods in a holistic way on five dimensions including Efficacy, Generalization, Portability, Locality, and Robustness.
The HalluEditBench evaluation encompasses seven prominent knowledge editing techniques, categorized into four types: Locate-then-Edit, Fine-tuning based, In-Context Editing, and Memory-based methods. Their evaluations reveal significant insights, including the limitations of prior assessments:
“We find that the effectiveness of some techniques can be far from what their performance on previous datasets suggests.”
The HalluEditBench benchmark addresses a critical gap in existing evaluations by focusing specifically on measuring knowledge editing corrections of real-world LLM hallucinations. Their evaluation exposed diverse strengths and weaknesses of different editing techniques across the five evaluation facets, and the influence of domains and LLMs on the effectiveness of corrections. For example, they determined:
(1) The manifestation of hallucination depends on question design; (2) Higher Efficacy Scores do not also necessarily indicate higher Generalization Scores; (3) All editing techniques except ICE only slightly improve or negatively impact the Generalization performance.
LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs
While LLMs can take in long context inputs, even over a million tokens, LLMs struggle to generate long outputs, with typical limits in the 2,000 to 4,000 range. Outputs are limited because LLMs are rarely trained well on long-output, due to scarcity of examples.
The paper LongWriter: Unleashing 10,000+ Word Generation from Long Context LLMs aims to fix the problem:
To address this, we introduce AgentWrite, an agent-based pipeline that decomposes ultralong generation tasks into subtasks, enabling off-the-shelf LLMs to generate coherent outputs exceeding 20,000 words. Leveraging AgentWrite, we construct LongWriter-6k, a dataset containing 6,000 SFT data with output lengths ranging from 2,000 to 32,000 words.
Thus, AgentWrite creates long output generation examples needed for an SFT dataset, LongWriter-6k, that in turn can be used for fine-tuning LLMs to generate longer outputs.
The authors then used LongWriter-6k dataset to fine-tune LLMs to scale outputs to over 10,000 words while maintaining output quality. To evaluate the long generation capabilities, they also develop LongBench-Write, a benchmark containing diverse user writing instructions with varying output length specifications. Experimental results demonstrate the effectiveness of their approach:
Our 9B parameter model, further improved through DPO, achieves state-of-the-art performance on this benchmark, surpassing even much larger proprietary models.
Ablations studies further validate the importance of the LongWriter-6k dataset and the effectiveness of the AgentWrite pipeline.
The authors conclude that existing long context LLMs already possess potential for longer generation capability, which can be unlocked with example extended outputs during model alignment. This result expands possibilities for generating high-quality, ultra-long text using LLMs, making them more useful in applications such as creative writing, report generation, and more.
Their code and models are shared on GitHub.
Contextual Document Embeddings
The paper Contextual Document Embeddings introduces contextual document embeddings, a method for adapting neural text retrieval models to new document sets at test time. Dense document embeddings are central to retrieval tasks, such as in search engines. They claim that such embeddings need context:
In this work, we argue that these embeddings, while effective, are implicitly out-of-context for targeted use cases of retrieval, and that a contextualized document embedding should take into account both the document and neighboring documents in context - analogous to contextualized word embeddings.
The authors propose two complementary methods to address this issue:
1. Contextual contrastive learning objective: Incorporates document neighbors into the training process, ensuring the embedding can discern documents even in challenging contexts.
2. Contextual embedding architecture: Injects information about neighboring documents during embedding, enabling the model to learn and utilize corpus-level statistics.
The authors show that both methods achieve better performance than prior encoder methods in several settings:
We achieve state-of-the-art results on the MTEB benchmark with no hard negative mining, score distillation, dataset-specific instructions, intra-GPU example-sharing, or extremely large batch sizes. Our method can be applied to improve performance on any contrastive learning dataset and any biencoder.
Contextual document embeddings offer a promising avenue for improving neural retrieval systems. By incorporating information about neighboring documents, these methods enable the generation of more robust and adaptable embeddings.