AI Research Roundup - More Models - 24.03.22
MineDreamer, MM1, Common Corpus, VLOGGER, Model Merging with Evolutionary Algs, MindEye2, and TacticAI.


Introduction
Up until now, the “AI Changes Everything” AI Weekly has included both AI research as well as AI product and business news. While it’s a great mix of content, I believe some of the AI research deserves more in depth discussion, without weighing down an already busy Weekly news summary.
So I am trying something new: Breaking out a more in-depth roundup of recent AI Research from the weekly. Comment and feedback to let me know if you like this change! Let’s begin …
On deck this week:
Apple’s MM1: A paper on developing a SOTA 30B parameter multi-model LLM.
MineDreamer: Using Chain of Imagination to help AI agents achieve goals.
Common Corpus: The largest public-domain (non-copyright) dataset for LLM training, with diverse works that total 500 billion words.
VLOGGER: Turning Audio into Speaking Avatars - now, with body movement.
Model Merging with Evolutionary Algorithms.
MindEye2: Faster AI mind-reading.
TacticAI: AI football (soccer) coach.
Apple’s MM1
Apple released a suite of multimodal LLMs, called MM1, up to a 30B parameter model that achieves state-of-the-art few-shot learning on multimodal benchmarks. They shared their results in the paper “MM1: Methods, Analysis & Insights from Multimodal LLM Pre-training.”
The researchers conducted extensive tests on different architectural choices and pre-training data mixtures to optimize model performance. They were able to assess the right mix of pre-training data - image plus text, caption, and text-only data - for best results. They also determined:
Image resolution has the biggest impact on performance, more than model size
Specific vision-language connector design has little effect
Synthetic caption data helps for few-shot learning
Thanks to large-scale pre-training, MM1 is able to do multi-image reasoning, enabling few-shot chain-of-thought prompting. The 30B dense MM1 model beats prior SOTA on VQA and captioning tasks, particular beating Gemini 1.0 and GPT-4 vision on the VQA benchmark.
This MM1 model is impressive in its own right, but sharing AI model results openly is encouraging for further open AI research on multi-modal LLMs.
MineDreamer & Chain of Imagination
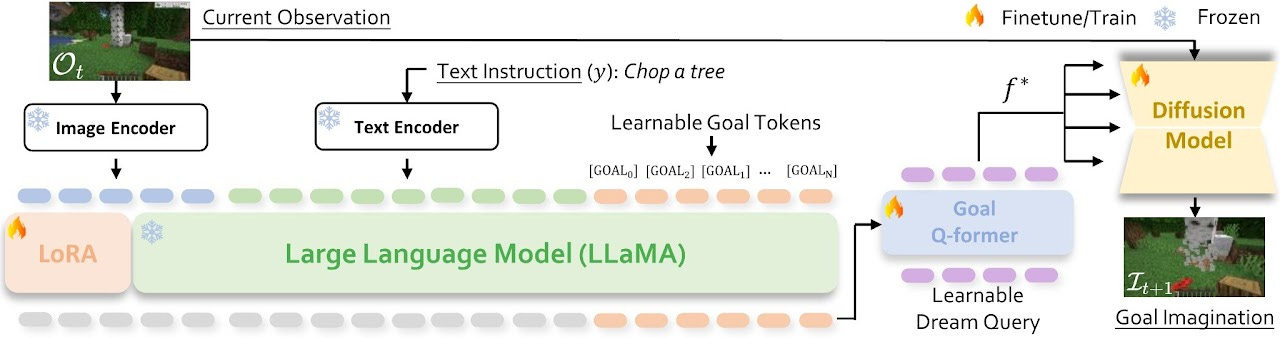
MineDreamer is an AI agent that excels at following complex instructions in the Minecraft world thanks to its innovative use of advanced language and vision models. The paper “MineDreamer: Learning to Follow Instructions via Chain-of-Imagination for Simulated-World Control” explains their work of building MineDreamer:
MineDreamer is developed on top of recent advances in Multimodal Large Language Models (MLLMs) and diffusion models, and we employ a Chain-of-Imagination (CoI) mechanism to envision the step-by-step process of executing instructions and translating imaginations into more precise visual prompts tailored to the current state; subsequently, the agent generates keyboard-and-mouse actions to efficiently achieve these imaginations, steadily following the instructions at each step.
In order to have a good generalist AI agent that follows it needs to have a good understanding of the steps to reach a complex goal. Their ‘Chain of Imagination’ mechanism you can think of this as the “think step-by-step” approach for action models. It introduces ‘self multi-turn interaction’ to sequential decision-making to achieve goals incrementally.

The Chain of Imagination process consists of three steps:
The Imaginator imagines a goal based on the instruction and current observation. (See Imaginator framework in Figure below.)
The Prompt Generator transforms this Imaginator output into a precise visual prompt.
The Visual Encoder encodes the current observation, and these together with prompt generator output are put through a VPT (video pre-training model, which in this work is a model called PolicyNet, trained on Minecraft videos), which determines the agent’s next action.
MineDreamer demo examples are shared in their project website, showing many video examples of MineDreamer in action achieving goals in Minecraft. Their published results show improvements over prior work:
Extensive experiments demonstrate that MineDreamer follows single and multi-step instructions steadily, significantly outperforming the best generalist agent baseline and nearly doubling its performance.
They also shows the MineDreamer approach is generalizable and so can be applied to other embodied AI agent domains.
Common Corpus
Common Corpus is the largest collection of fully open public-domain text for LLM training, comprising nearly 500 billion words
An international initiative has announced they are Releasing Common Corpus, the largest public domain dataset for training LLMs. Common corpus is an international initiative coordinated by French AI start Pleias with support of other AI companies, cultural and Governmental organizations (French Ministry of Culture), open AI organizations (Occiglot, Eleuther AI) and others. They released Common Corpus on HuggingFace:
Common Corpus is the largest public domain dataset released for training LLMs. It includes 500 billion words (600-700B tokens) in the public domain from a wide diversity of cultural heritage initiatives.
Common Corpus is multilingual and the largest corpus to date in English, French, Dutch, Spanish, German and Italian.
Common Corpus shows it is possible to train Large Language Models on fully open corpus. Due to the complexity of copyright check, we have only released a partial amount of the text we hold and will release way more in the months
There have been other efforts to generate widely available datasets, such as the work done by Together, the RedPajama-v2 30 trillion token dataset - and AI2’s Dolma, a 3 trillion token dataset. Th Common Corpus effort goes one step further, by ensuring the public domain intellectual property rights status of all their content.
Finally they mention that “this is only an initial part of what we have collected so far … we’ll continue to publish many additional datasets from other open sources.” So this validates that it may be possible to train frontier LLMs on fully open permissible data.
Vlogger - turning Audio into Speaking Avatars
Google DeepMind researchers shared their work on VLOGGER, a new AI model that generates talking avatar videos with full upper body motion from just a still image and audio clip. They shared their results in VLOGGER: Multimodal Diffusion for Embodied Avatar Synthesis.
While we’ve seen other lip-syncing and audio-to-avatar AI models and products, VLOGGER claims more broad capabilities than prior work.

Model Merging with Evolutionary Algorithms
Model merging creates a new LLM by merging parameter weights from multiple LLMs together, using tools like mergekit. These ‘frankenstein’ AI models surprisingly can work and be good AI models.
In “Evolutionary Optimization of Model Merging Recipes,” Japanese AI researchers took model merging to the next level, using evolutionary optimization techniques to determine the best merges of input LLMs.
we propose an evolutionary approach that overcomes this limitation by automatically discovering effective combinations of diverse open-source models, harnessing their collective intelligence without requiring extensive additional training data or compute. Our approach operates in both parameter space and data flow space, allowing for optimization beyond just the weights of the individual models. This approach even facilitates cross-domain merging, generating models like a Japanese LLM with Math reasoning capabilities.
They shared multiple positive results, including SOTA results on a Japanese Math LLM, and a culturally-aware Japanese VLM that outperforms previous Japanese VLMs. This is a more directed approach towards AI model merging.
MindEye2 - Faster AI mind-reading
Researchers at Stability AI and Princeton just introduced MindEye2, a leap in reconstructing images from brain activity. “MindEye2: Shared-Subject Models Enable fMRI-To-Image With 1 Hour of Data” presents a model that connects brain data to an image gen model to produce photorealistic reconstructions, in just an hour of scanning on new subjects.
The leap then is that they can “pretrain our model across 7 subjects and then fine-tune on minimal data from a new subject.” Before, models had to be trained independently on subjects.
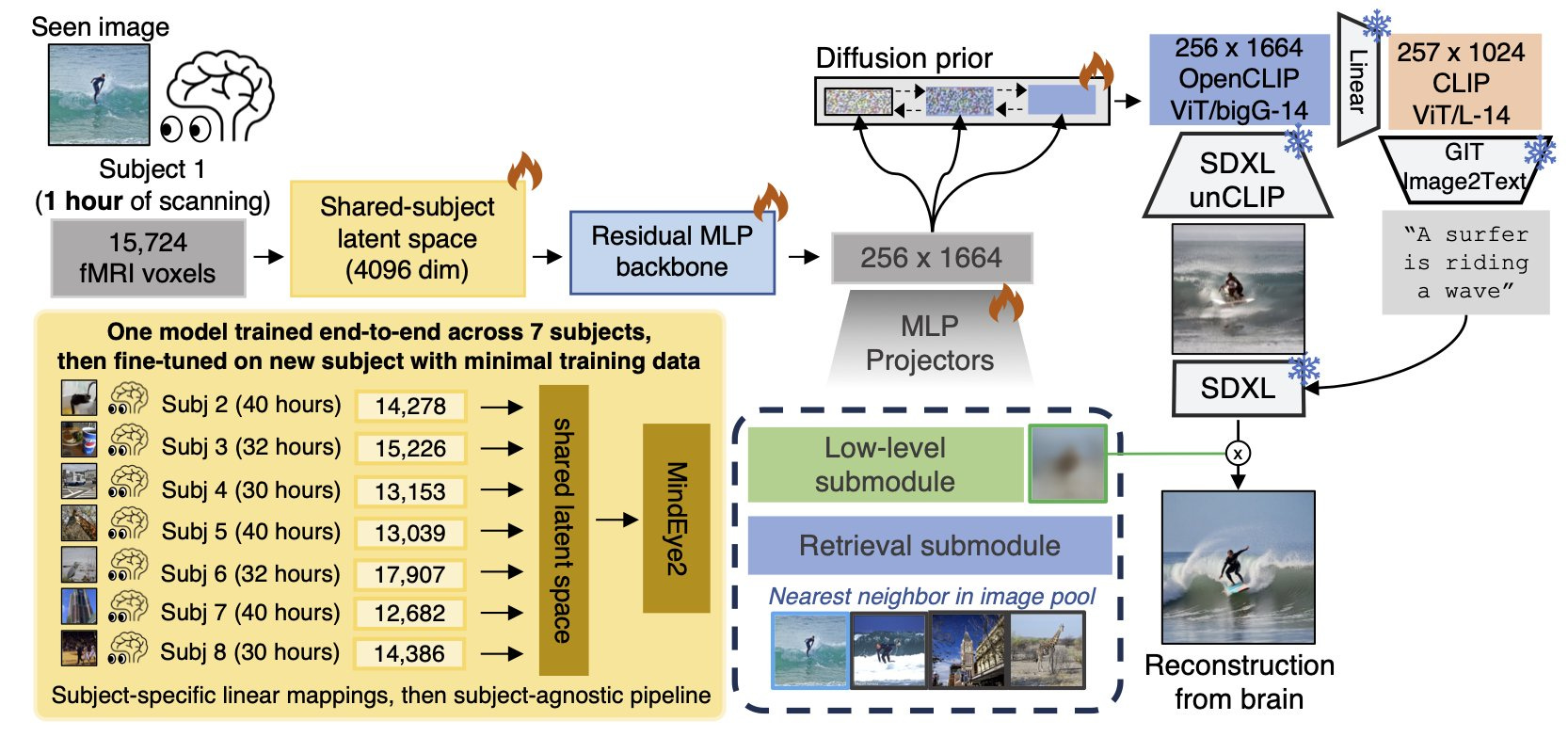
How they achieve it:
Our novel functional alignment procedure linearly maps all brain data to a shared-subject latent space, followed by a shared non-linear mapping to CLIP image space. We then map from CLIP space to pixel space by fine-tuning Stable Diffusion XL to accept CLIP latents as inputs instead of text.
They note that “MindEye2 demonstrates how accurate reconstructions of perception are possible from a single visit to the MRI facility.” This is one step closer to a practical mind-reading AI.
In related news, this week Neuralink revealed first human-trial patient, a 29-year-old quadriplegic who says brain chip is 'not perfect' but has changed his life. AI only keeps getting better, and this literally mind-warping technology will have profound applications.
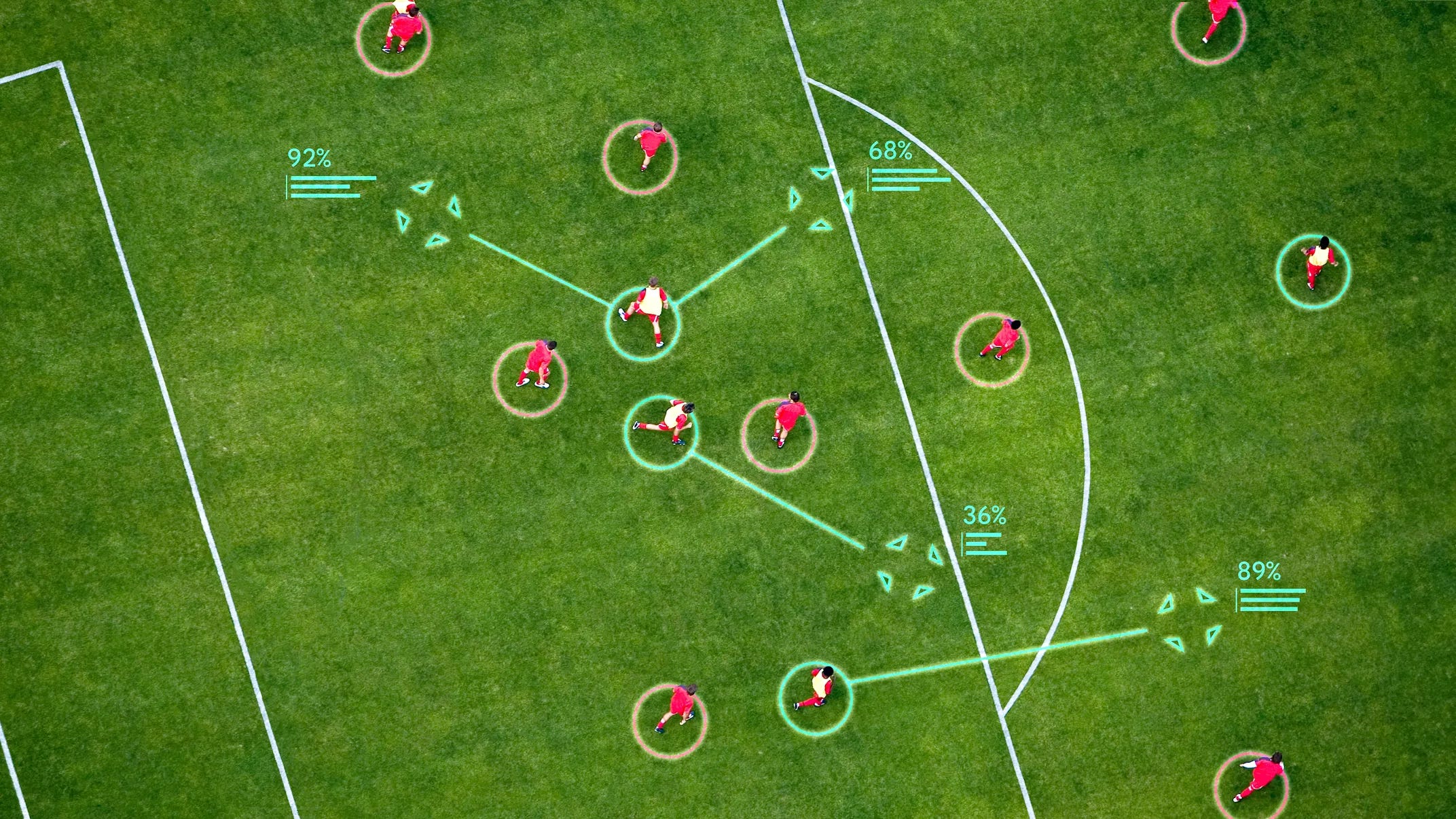
TacticAI - AI football (soccer) coach
Google DeepMind introduces TacticAI, an AI system that can advise coaches on football (soccer for us Americans) tactics. Created in collaboration with Liverpool FC in the UK, it uses predictive and generative models to analyze previous play data, specifically offering insights to football coaches on corner kicks.
It can help teams sample alternative player setups to evaluate possible outcomes and achieves state-of-the-art results.