


AI week in review 23.07.15
Google's Big Bard update, ReLora improves LLM training, Claude-2 challenges GPT-4, and is GPT-4 getting dumber?


AI Tech and Product Releases
Anthropic announced Claude-2, available via API and as public-facing chatbot, claude.ai. It can take longer inputs, up to 100K tokens, and responses, and claims improved performance, with impressive scores on various benchmarks: 71.2% on the Codex HumanEval; 88.0% on GSM8k grade-school math problems; 76.5% on the multiple choice section of the Bar exam; above 90th percentile on GRE reading. This is finally a worthy competitor to GPT-4. JasperAI and Sourcegraph’s Cody use Claude2 under the hood.
Google announced a major Bard update and launched its Bard in Europe, giving its AI chatbot Bard more usability, more languages (40 languages available), and more features. Users can modify and share responses, change the tone and response length, pin conversations, get speech output with Text-to-speech, and analyze images in prompts with Google Lens. You can also export Python code to Replit. This massive upgrade is enough to get me to actually make Bard a go-to tool.
Along with Bard upgrades, Google unveils NotebookLM, an AI-first notebook, designed to help you gain insights on your documents. It’s available via a waitlist.
AI-generated commercials have arrived: Futuri Launches SpotOn, a 100% AI-powered Production System That Instantly Generates Fully Produced Commercials and Spec Spots. Futuri, provider of AI-driven content/sales technology, makes AI production system with vast libraries of voices, languages, and even music.
Pika Labs, maker of AI-generated video has announced a new feature, image-conditioned video generation. Upload an image, and their model will animate it for a few second. AI video generation keeps getting better.
IBM Begins Releases New Watsonx.AI and Data Platform. IBM’s Watsonx.ai is a platform to train, validate, tune and deploy machine learning and generative AI models, and it works with a data platform (watsonx.data). Over 150 enterprise clients have participated in the company’s beta and tech previews.
Meta is reportedly working on an open source LLaMA v2 AI model that aims to break the dominance of OpenAI and GPT-4. This will allow Meta and users to benefit from open source development, while keeping competitors from using it via restrictions placed on commercial use.
Robots walk among us! The GR-1 general-purpose humanoid robot will carry nearly its own weight and is designed for caretaking and medical support. The Chinese company Fourier Intelligence the maker announced they will be building 100 of these robots this year.

AI Research News
Meta continues to do interesting things in AI multi-modal models, one of them it CM3leon “a more efficient, state-of-the-art generative model for text and images.” Diffusion models that generate images are amazing, but they are also slow, and there have been more efficient approaches developed. In this research, “Scaling Autoregressive Multi-Modal Models,” Meta AI researchers have created an efficient multi-modal model that has many interesting use cases beyond just text-to-image:
It is a causal masked mixed-modal (CM3) model because it can generate sequences of text and images conditioned on arbitrary sequences of other image and text content. This greatly expands the functionality of previous models that were either only text-to-image or only image-to-text.
In Stack More Layers Differently: High-Rank Training Through Low-Rank Updates, researchers have applied the magic of LoRA to pre-training of LLMs, with a method called ReLoRA. This is a parameter-efficient method that utilizes low-rank updates to train transformer language models from scratch. They show that “the efficiency of ReLoRA increases with model size, making it a promising approach for training multi-billion-parameter networks efficiently.” If applicable generally, this could greatly speed up the training of LLMs.
DragonDiffusion: Enabling Drag-style Manipulation on Diffusion Models presents “a novel image editing method, DragonDiffusion, enabling Drag-style manipulation on Diffusion models.” By dragging and moving parts of an image within a diffusion model, it can modify the intermediate representation to consider both semantic and geometric alignment. This can support editing features such as object moving, dragging, resizing, and appearance replacement, within an image. This is related to prior work we’ve noted, called Drag Your GAN.

Via the Hugging Face paper page: PolyLM: An Open Source Polyglot Large Language Model. PolyLM is an LLM trained on 30% multilingual data, increasing to 60% in the final stages. Its performance surpasses LLaMA and BLOOM on multilingual prompts.
MIT CSAIL researchers develop “FrameDiff,” a computational tool that uses generative AI to craft new protein structures, with applications in multiple areas in biotechnology and medicine.
It uses machine learning to model protein “backbones” and adjust them in 3D, crafting proteins beyond known designs. This breakthrough could accelerate drug development and enhance gene therapy by creating proteins that bind more efficiently, with potential applications in biotechnology, targeted drug delivery, and more.
Generative AI Goes 'MAD' When Trained on AI-Created Data Over Five Times. Model Autophagy Disorder, or MAD, describes a collapse of output quality when training on AI produced data. Over several iterations, the model eventually loses endpoints, and produces more and more mutated results.
Are all LLM components really needed to perform in-context learning? The paper “Rethinking the Role of Scale for In-Context Learning: An Interpretability-based Case Study at 66 Billion Scale” answers that question. It finds that “only a core group of attention heads and FFNs appeared crucial for in-context learning,” and that you can prune the AI model significantly while retaining performance, suggesting models are undertrained and model architectures can be improved.
Chiplet Cloud architecture for AI inference Can Bring The Cost Of LLMs Way Down. Researchers claim the Chiplet Cloud AI inference-specific supercomputer architecture provides 15x to 100x reduction in inference costs compared to an A100. They do this by customizing the architecture for specific LLMs.
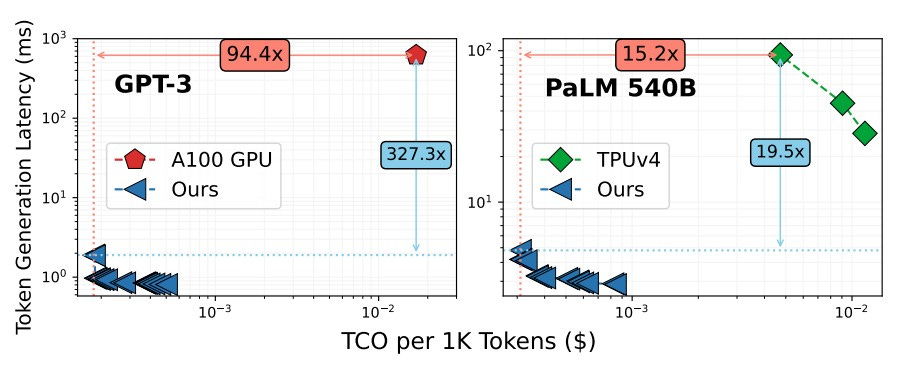
AI Business and Policy News
There have been notable complaints that OpenAI's GPT-4 Got 'Lazier' and 'Dumber.' This Might Be Why. GPT-4 is providing quicker results, but is losing its high level accuracy. OpenAI says it’s not so, and claims “No, we haven't made GPT-4 dumber.”
Elon Musk Launches New AI Company xAI, with the goal to “understand the true nature of the universe.” Previously, he stated he was working on ‘TruthGPT’ to “understand the universe.” He never lacks in ambition.
Some notable AI startup funding announcements this week:
Tangibly, a Seattle startup that uses AI to help companies protect trade secrets, raises $6.5 million in seed round funding. Tangibly manages securing intellectual properties with AI that identifies what information needs to be guarded.
EchoNous, maker of an AI-powered portable ultrasound system, raises $7M.
Nomic, the people behind the viral GPT4All, raised $17M in Series A funding.
ChatGPT maker investigated by US regulators over AI risks.
Copyright infringement issues surrounding LLMs are coming to a head: Sarah Silverman and other authors suing OpenAI and Meta for copyright infringement. The lawsuits allege OpenAI’s ChatGPT and Meta’s LLaMA were trained on their works without permission from “shadow library” websites like Bibliotik, and AI can output verbatim parts of their works.
One way to head off the IP legal challenge is to get legal rights. Shutterstock Expands Partnership with OpenAI, Signs Agreement to Provide High-Quality Training Data.
AI Opinions and Articles
The Joseph Saveri Law Firm behind the LLM litigations mentioned above made their case publicly on their LLM litigations website. Their main complaint is a valid challenge to AI: AI models are repackaging human creative content, and have done it without permission. IP legal problems could stop the AI revolution in its tracks.
“Generative artificial intelligence” is just human intelligence, repackaged and divorced from its creators.” - Joseph Saveri Law Firm
A Look Back …
This chart of LLM performance on MMLU shows how far we’ve come in just a few years with LLMs.
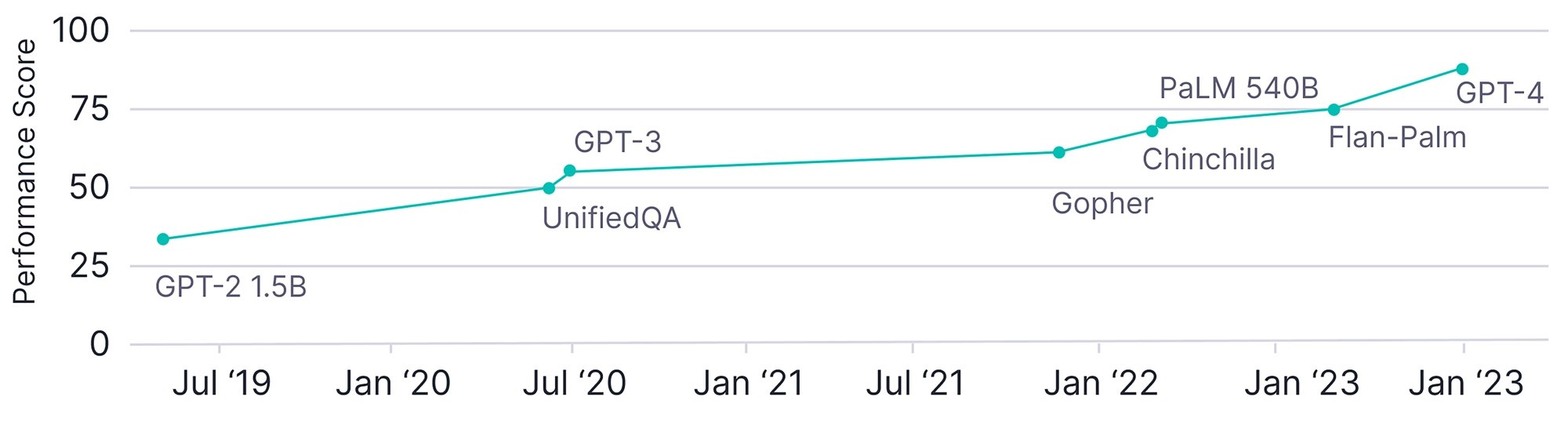
The chart comes from this high-level overview of Large Language Models from Borealis AI. The overview shares an additional chart on LLM parameters sizes since 2019 below.

Claude not available everywhere yet, alas. Was keen to try it out.