AI Week in Review 23.08.20
Adobe's Firefly is free, AI2 drops massive open dataset, Googles SGE summarizes articles, AI Art can't be copyrighted!


Top Tools
Adobe’s Express with Firefly Generative AI wins this week’s “Top Tool” mention, now that Adobe has taken its Adobe Express with Firefly web app out of beta and made it free world-wide on the desktop web app, with plans to add it to the mobile app soon.
AI Tech and Product Releases
Google’s AI-powered Search Generative Experience (SGE) is getting a major new feature update: To summarize articles you’re reading on the web. This may help Google keep their search engine market share, making the search engine more of an answer engine.
Not an official release, but The Information reported that Meta's 'Code Llama' plans to take OpenAI and Google in AI Coding. Codenamed 'Code Llama,' this state-of-the-art code generation tool harnesses the prowess of artificial intelligence and will likely be open-source.
This news story from the World Robot Conference in Beijing this week presents some robots with human-like skin, eye expression and movement. These robots are being created to be companion robots, and they are just human-like enough to fall into that uncanny valley of creepiness.
AI2 drops biggest open dataset yet for training language models to provide open data for the Olmo LLM they are developing. As they announced in their blog post:
Today, we release our first data artifact in this project — Dolma, a dataset of 3 trillion tokens from a diverse mix of web content, academic publications, code, books, and encyclopedic materials. Openly available for download on the HuggingFace Hub under AI2’s ImpACT license, Dolma is the largest open dataset to date.
AI Research News
In Follow Anything (FAn): Open-set detection, tracking, and following in real-time, researchers from MIT and Harvard present a robotic system to detect, track, and follow any object in real-time. The FAn model can detect and segment objects, track them across image frames at 6-20 frames per second, and follow them in a control loop.
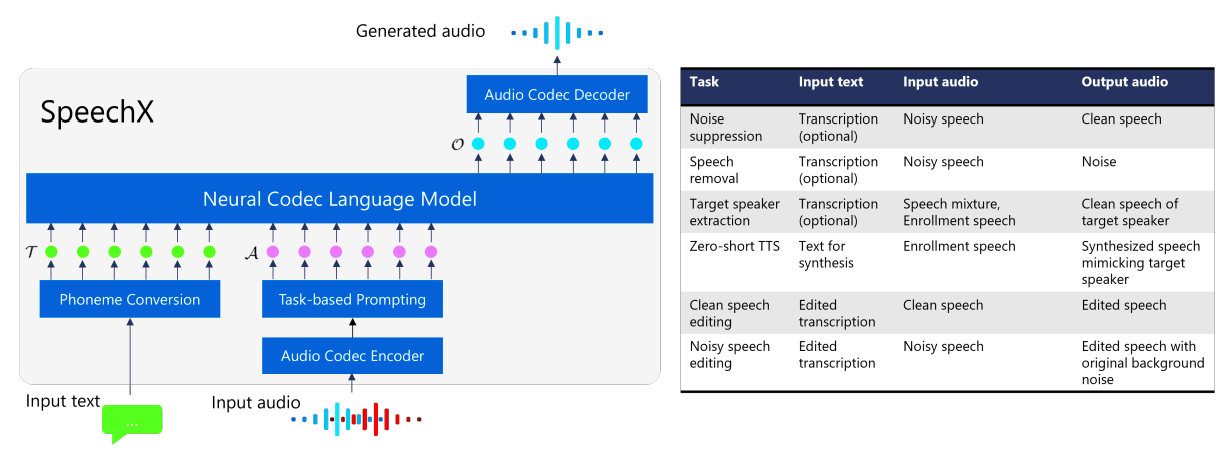
Microsoft researchers introduce SpeechX: A Neural Codec Language Model as a Versatile Speech Transformer. SpeechX, trained on 60K hours of speech audio, is a versatile speech generation model capable of zero-shot TTS and various speech transformation tasks (such as noise suppression, target speaker extraction, speech removal), dealing with both clean and noisy signals.
AI Business and Policy
OpenAI bought General Illumination to have their team work on ‘core products’ like ChatGPT.
Microsoft plans on starting a new AI service with Databricks for AI solutions for enterprise. This may be a challenge to OpenAI, but it also indicates Microsoft is taking an ‘all of the above’ approch to AI: Embedding it their software platforms, their OS, and working with OpenAI to offer chatGPT via Bing. Databricks purchase of MosaicML give them the framework to enable enterprises to “roll your own” AI models, and so this Databricks AI offering is customized AI models for specific enterprise use cases.
Generative AI and the future of work in America: “By 2030, activities that account for up to 30 percent of hours currently worked across the US economy could be automated—a trend accelerated by generative AI.”
Many jobs will be automated to such an extent that anyone in those domains will need to get AI-capable to get more productive, or get left behind. AI threatens the billable hour revenue model:
"AI makes everything that's wrong with the labor-based billing system even worse, because you're dealing with a system where the faster you work, the less you earn," Williams said. "You solve a problem quicker, so you bill your client for fewer hours and you therefore earn less money."
The flip-side of the AI opportunity is the surge in demand for AI engineers: AI model builders, AI app creators, AI model customization tuners, prompt engineers. Tech Works discusses how to fill the 27 Million AI engineer gap. AI won’t destroy jobs on net, but will displace and disrupt practically every industry, shifting job roles and job types, and this is true even in the software engineering world, where every software engineer will need to become AI-capable.
AI-generated art cannot be copyrighted, rules a US Federal Judge. DC District Court Judge Beryl A. Howell ruled that human beings are an “essential part of a valid copyright claim” and “human authorship is a bedrock requirement of copyright.” This puts all the creations of Dall-E, Midjourney and similar image generation tools in doubt. But the argument that these works were absent any guiding human hand” begs a question of whether the text prompt that initiating the AI generation is that ‘guiding hand.’
Speaking of copyrights, an Atlantic article delves into the “Books 3” dataset used for LLM model training: “Stephen King, Zadie Smith, and Michael Pollan are among thousands of writers whose copyrighted works are being used to train large language models.”
This Books3 dataset was recently take offline from torrent websites, due to DMCA takedown notices. Open source AI model advocates are not happy about this, because it will be a blow for open source AI models:
“The only way to replicate models like ChatGPT is to create datasets like Books3,” Presser said. “And every for-profit company does this secretly, without releasing the datasets to the public… without Books3, we live in a world where nobody except OpenAI and other billion-dollar companies have access to those books—meaning you can’t make your own ChatGPT. No one can. Only billion-dollar companies would have the resources to do that.”
The lawsuit against Meta claims that Meta used the Books3 repository to train its Llama models.
AI Opinions and Articles
Torsten Grabs of Snowflake makes the case for why downsizing large language models is the future of generative AI:
Smaller language models aren’t just more cost-efficient, they’re often far more accurate, because instead of training them on all publicly available data—the good and the bad—they are trained and optimized on carefully vetted data that addresses the exact use cases a business cares about.
Neural networks and deep learning was developed from an attempt to mimick how biological neurons operate. Now, researchers have uncovered how biological astrocyte-neuron networks in our brain operate like the transformer core computations:
Using mathematical modeling, they demonstrated how astrocytes’ integration of signals over time could provide the required spatial and temporal memory for self-attention. Their models also show that a biological transformer could be built using calcium signaling between astrocytes and neurons. TL;DR, this study explains how to build an organic transformer.
Is the AI boom already over? asks an author at Vox. Justifying the claim that “Generative AI tools are generating less interest than just a few months ago”, the authors cite how ChatGPT usage fell in June, GPT-4 accuracy was going down, and Bing market share hasn’t really taken off. Surely the newness of chatGPT has worn off, but the importance hasn’t. None of these data points change the fundamental shift AI is making, and those changes will percolate with ripple effects for years to come. We are still in AI’s early innings.
A Look Back …
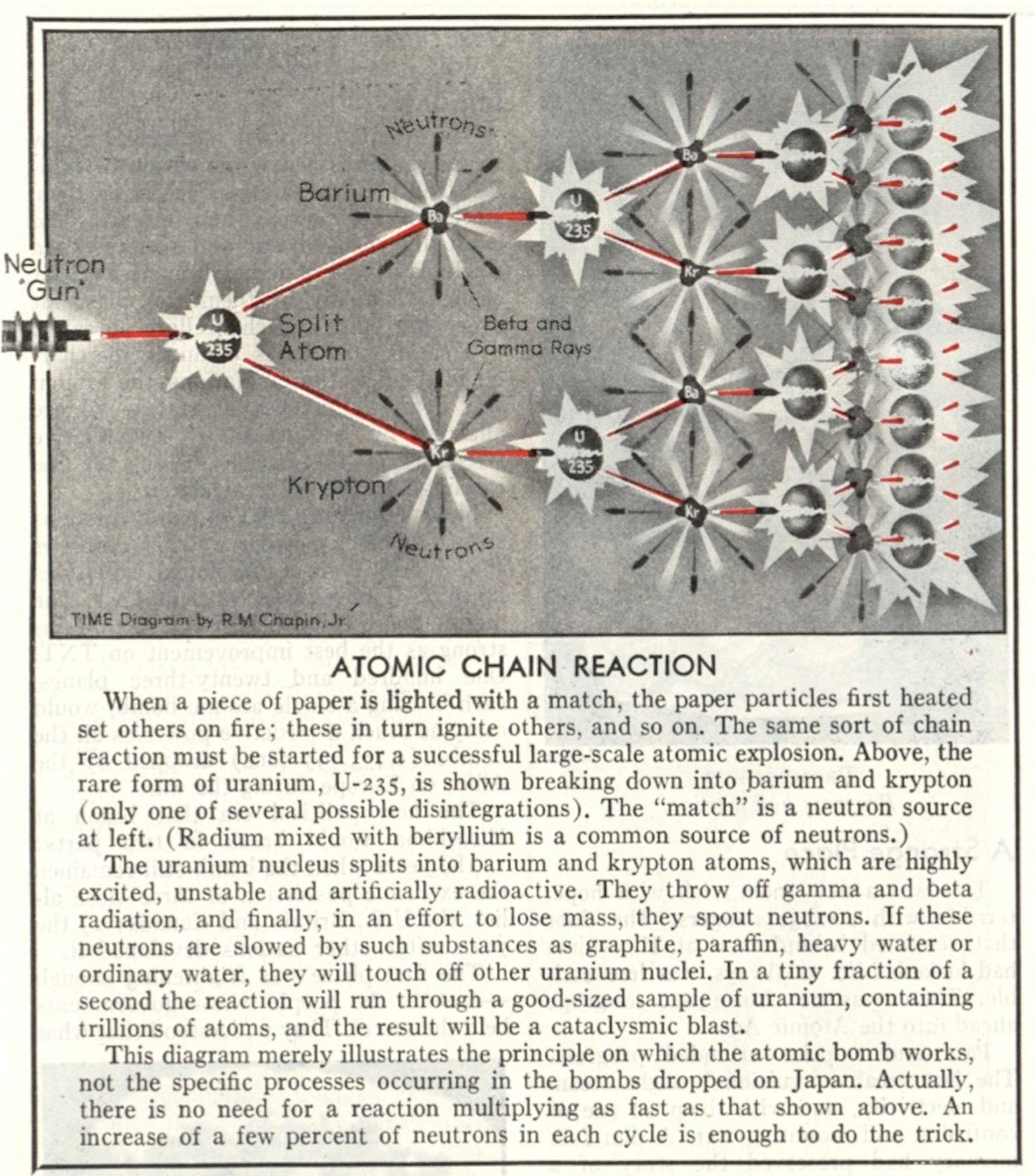
How the Atomic Bomb was explained to TIME readers on August 20, 1945, just weeks after atomic bombs were dropped on Hiroshima and Nagasaki, ending World War II: