


AI Week in Review 23.08.26
Code Llama, Midjourney Inpainting, Nvidia blowout earnings, GPT-3.5 fine-tuning


AI Tech and Product Releases
It was a Big Week for announcements:
In sound and speech, ElevenLabs released a new Voice AI model supporting multilingual capabilities across 28 languages - the Eleven Multilingual version 2.
In a leap forward for audio-speech translation, Meta AI introduced SeamlessM4T, a foundational multilingual and multitask AI model that translates and transcribes across speech and text across nearly 100 languages. They are releasing the model under CC BY-NC 4.0 and shared a paper on SeamlessM4T.
In image and video, Midjourney released their inpainting ‘vary region’ feature, where users can now edit individual regions of an image via a prompt. Some users have figured out you can use this feature to get higher quality final full image results.
Midjourney also shared their future plans on Twitter: Version 6 will come with “more controllability, more knowledge, better text understanding, more styles, more diversity, ability to generate text, better resolution.” 3D and video is being worked on.
LeonardoAI announces “One of the latest additions to our growing roster of models is the ace Anime Pastel Dream by Lykon.” One of their images won the slot for our AI cover art for this week; see above.
Microsoft announced Python in Excel, combining the power of Python and the flexibility of Excel analytics within the same workbook. Also, Microsoft could soon be adding AI to their Windows paint tool.
In large language models, OpenAI announced fine-tuning for GPT-3.5 Turbo, with fine-tuning for GPT-4 coming this fall. Developers can customize models to perform better for specific use cases and run these custom models at scale. OpenAI mentions Improved steerability, reliable output formatting, and custom tone as use cases - useful presumably for corporate applications that need controlled niche AI models.
Shared by Yann LeCun, Meta’s AI team announced CodeLlama, “a state-of-the-art large language model for coding,” in 7B, 13B and 34B sizes, and released the model on Github and for open use under the same license as Llama2. These models started from Llama2 as based models, then used 100B tokens of python code and 20B tokens of long context fine-tuning on code text.

The models are a new standard for open coding models, with strong results on pass@1 on HumanEval benchmarks: CodeLlama-34B - 48.8% ; CodeLlama-34B-Python - 53.7%. This is compared with 48.1% for GPT-3.5 and 67% for GPT-4.
If you want to try it, Perplexity AI has CodeLlama available here. Dr Cintas on Twitter had a ChatGPT vs CodeLlama dance-off. His eval Chat-GPT came out ahead.
One exciting followup is that Phind reports Beating GPT-4 on HumanEval with a Fine-Tuned CodeLlama-34B:
We have fine-tuned CodeLlama-34B and CodeLlama-34B-Python on an internal Phind dataset that achieved 67.6% and 69.5% pass@1 on HumanEval, respectively. GPT-4 achieved 67% according to their official technical report in March. To ensure result validity, we applied OpenAI's decontamination methodology to our dataset.
Phind did fine-tuning on ~80k high-quality programming problems and solutions, taking only “three hours using 32 A100-80GB GPUs, with a sequence length of 4096 tokens.”
Heard on twitter - Meta AI’s LLM plans: “We have compute to train Llama 3 and 4. The plan is for Llama-3 to be as good as GPT-4. … open source.”
IBM taps AI to translate COBOL code to Java. “Looking to present a new solution to the problem of modernizing COBOL apps, IBM today unveiled Code Assistant for IBM Z, which uses a code-generating AI model to translate COBOL code into Java.” It’s a stodgy problem, but with 800 billion lines of COBOL out there, a big one.
Another specialized coding model, Defog.AI’s SQLCoder, was open-sourced this week, as explained in this blog post. A fine-tuned version of StarCoder, 15B parameter “SQLCoder outperforms OpenAI’s gpt-3.5-turbo, and significantly outperforms all major open-source models for generic SQL schemas in Postgres.” This points in the direction of smaller specialized models outperforming their larger more general counterparts.
Alibaba has released AI Models With Visual Localization Capabilities. The models, Qwen-VL and Qwen-VL-Chat, are open source, can understand more complex visual signals, such as text within images, and respond to location-based queries. These models are on its foundational LLM Tongyi Qianwen, which has both Chinese and English language capabilities.
More speculation and news about Google’s Gemini - it is said to be multi-modal, “trained on a vast corpus of YouTube videos” and likely to be released in fourth quarter of this year.
AI Research News
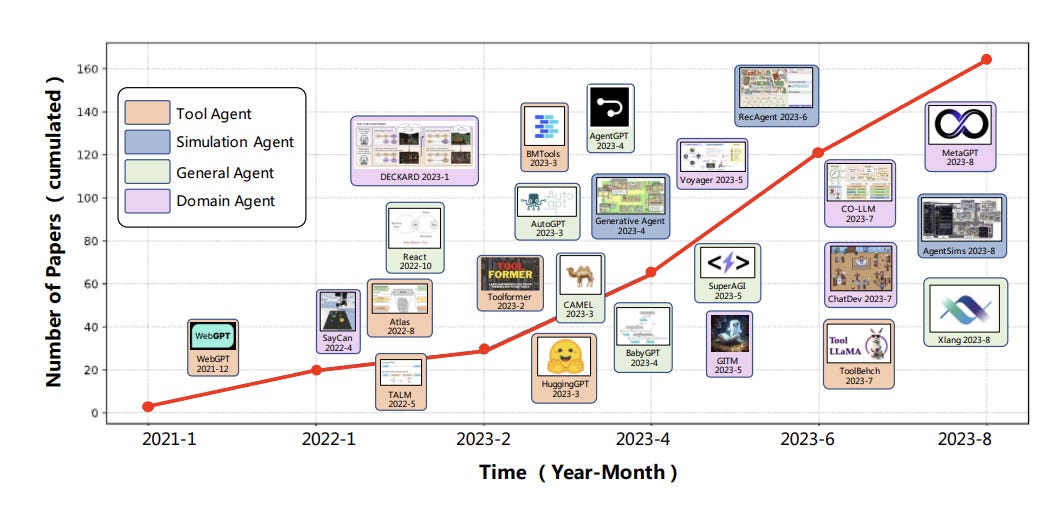
Researchers from Beijing, China present A Survey on Large Language Model based Autonomous Agents. Their chart below says a lot about the explosion of progress this year in this space - AI agents have blossomed with the latest powerful AI models like GPT-4. They a repository for the related references at this https URL.”
The paper “Consciousness in Artificial Intelligence: Insights from the Science of Consciousness” grapples with the difficult question of what it might mean to create conscious AI. They look at different theories of consciousness and attempt to pair the status of AI models to the “indicator properties” of consciousness from those theories. One remarkable conclusion is that “no current AI systems are conscious, but also suggests that there are no obvious technical barriers to building AI systems which satisfy these indicators.”
AI Business and Policy
This week’s biggest AI business news item is how Nvidia just crushed their Q2 earnings, making a stunning $6.2 billion in net income on revenue of $13.5 billion. Being the pick axe seller of the AI gold rush has been very good for Nvidia (stock symbol NVDA), and the boom will continue; they project sales of $16 billion in the next quarter.

Hugging Face raised $235 million in a Series D investment round, at a valuation of $4.5 billion. As the “Github” of AI models (500K models, 250K data sets, and 10K paying users), the valuation is eye-popping but not surprising. Salesforce, Google, Amazon, Nvidia, AMD, and Intel are among those backing the company.
Ideogram AI has launched with $16m in funding from a16z, saying “we're excited to push the limits of what's possible with Generative AI.”
Cruise told by regulators to ‘immediately’ reduce robotaxi fleet 50% following crash. In the accident, a Cruise robotaxi collided with a fire truck in an intersection, as Cruise explained in this blog post.
AI Opinions and Articles
Open and freely available AI or closed and controlled AI? That may become the dividing line in the The Heated Debate Over Who Should Control Access to AI. Time magazine digs into how Meta’s AI efforts are colliding with the regulatory impulse of some in Washington, DC:
The disagreement between Meta and the Senators is just the beginning of a debate over who gets to control access to AI, the outcome of which will have wide-reaching implications. On one side, many prominent AI companies and members of the national security community, concerned by risks posed by powerful AI systems and possibly motivated by commercial incentives, are pushing for limits on who can build and access the most powerful AI systems. On the other, is an unlikely coalition of Meta, and many progressives, libertarians, and old-school liberals, who are fighting for what they say is an open, transparent approach to AI development.
A head’s up from Owen Colegrove on the “The AI Reproducibility Crisis:”
The principle is simple, if accessible private models are silently changing in time, then previous results cannot be replicated.
Academic papers are showing differences in performance, and complex AI models, especially closed source ones, are not transparent. His solutions for AI model governance and research clarity to address this:
- Lean towards open-source foundational models for transparency.
- Clearly annotate the date of model access when relying on private providers. Push on providers to provide model / inference specifiers to stop silent changes.
- Advocate for continuous third-party benchmarking of LLM providers to monitor model changes. This is an initiative we're currently starting w/ some help from a great academic group.
A Look Back …
The Church–Turing thesis was developed in 1936 at the dawn of the computing age, and serves as a theory underlying what computing can encompass:
The Church-Turing thesis (formerly commonly known simply as Church's thesis) says that any real-world computation can be translated into an equivalent computation involving a Turing machine. In Church's original formulation (Church 1935, 1936), the thesis says that real-world calculation can be done using the lambda calculus, which is equivalent to using general recursive functions.