
AI Week In Review 24.09.14 - o1 released!
OpenAI's releases o1 - o1-mini and o1-preview - and it's SOTA on math, coding, GPQA and reasoning. Plus, Mistral's Pixtral 12B, Google's DataGemma, Gemini Live now free on Android, Llama-3.1-Omni.


Top Tools – Open AI releases o1
"We're releasing a preview of OpenAI o1—a new series of AI models designed to spend more time thinking before they respond. These models can reason through complex tasks and solve harder problems than previous models in science, coding, and math."
- OpenAI
OpenAI announces o1. After months of internal development and outside speculation, OpenAI released the fruit of Strawberry’s next-level reasoning efforts, o1, “AI models designed to spend more time thinking before they respond.” OpenAI released two initial o1models, o1-mini and o1-preview, a checkpoint of o1 model to release soon.
Benchmarks and Performance: The performance of o1 is incredible. Both o1-mini, o1-preview and (not yet released) o1 show significantly improved reasoning capabilities on math, coding, and a range of academic subjects.
On Math: On high school AIME math exams, GPT-4o solved 12%, o1 averaged 74% (11.1/15) with a single sample per problem; o1-mini’s score of 70% (about 11/15 questions) places it in approximately the top 500 US high-school students and outperformed o1-preview at 45%. The new o1 scored 83% on IMO qualifying exams compared to GPT-4's 13%. On MATH benchmark, o1 is at 94.8% vs 60% for GPT-4o.
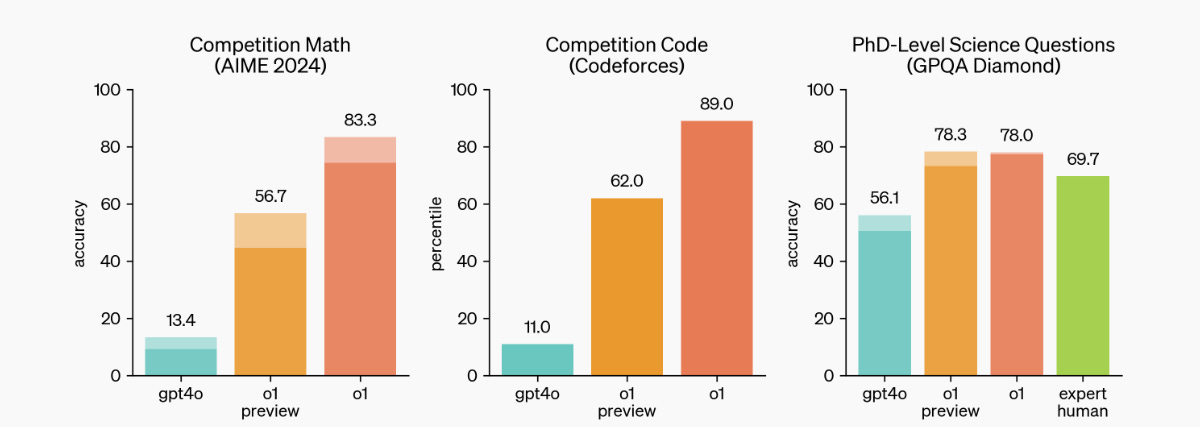
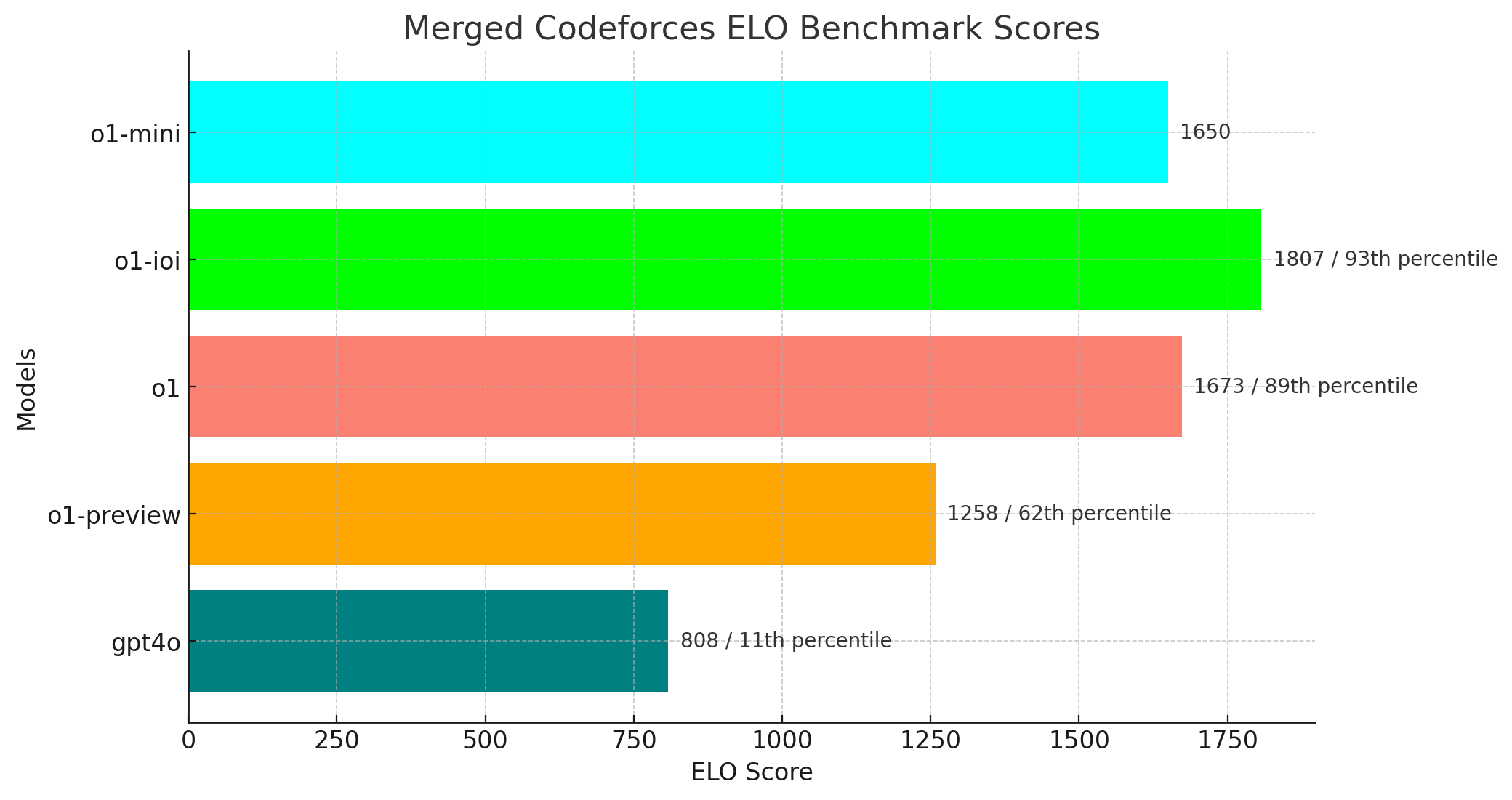
On Coding: Both o1-mini and o1-preview get over 92% on Human Eval, beating GPT-4 and saturating that benchmark. o1 achieves 89th percentile in Codeforces coding competitions, scoring 1673, and o1-mini does almost as well at 1650; both are well above GPT-4. o1-preview scores 80% on aider code editing (SOTA - Claude 3.5 Sonnet was 77%). While it’s SOTA for coding for an AI model, some are skeptical about real-world performance, as it can struggle on some problems not difficult for human programmers.
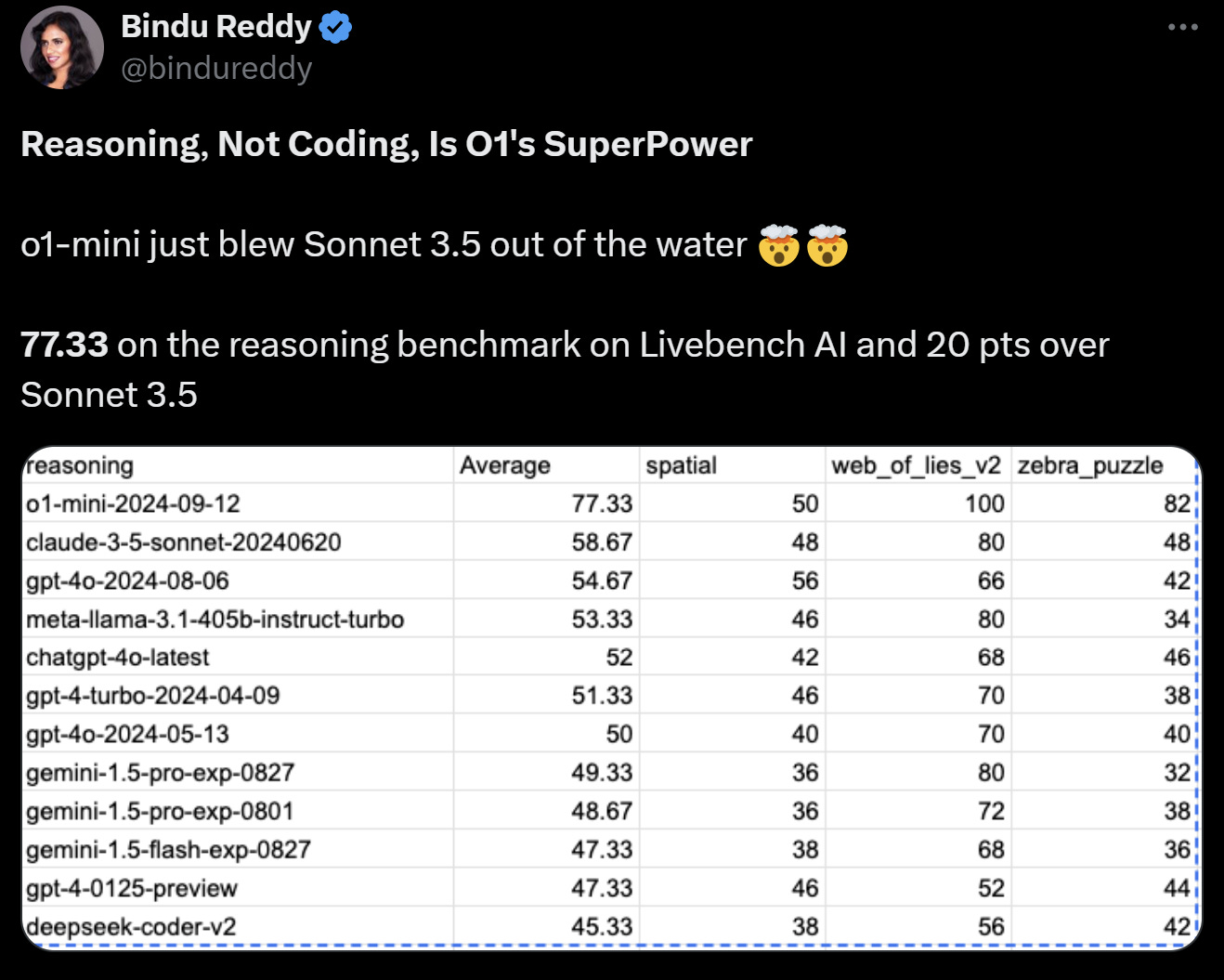
Reasoning: The o1-preview model gets 21% on ARC-AGI, very good but not SOTA nor AGI. Impressively, o1-mini decisively beat Claude Sonnet 3.5 and all other AI models on the LiveBench AI reasoning benchmark; o1-mini achieved 77% on LiveBench, well above Claude 3.5 Sonnet (58%), GPT-4o (54%) and all other AI models.
General academic performance: o1 outperforms GPT-4o on 54 of 57 MMLU subcategories, attaining 92% overall on MMLU. The models show 20-30% improvements over previous versions in areas such as mathematics, physics, logic, law, and computer science. It achieved 78.2% on MMMU, making it competitive with human experts.

Where o1 really shines is the more difficult GPQA. Even o1-mini outperformed GPT-4o, even though o1-mini is a fast, cost-effective model for reasoning without broad world knowledge.

How o1 performs reasoning: The o1 models are trained with reinforcement learning to think before producing final answers, using inference compute to generates ‘thinking’ tokens and engage in an optimized chain-of-thought process. This produces more advanced reasoning abilities and more thoughtful and accurate responses to complex queries. However, OpenAI is not sharing algorithmic details or even allowing users to observe the ‘thinking’ tokens.
Safety: Open AI shared a System Card for o1 that shows significant improvements in safety and robustness metrics, such as a 4-fold increase in resistance to jailbreaking attempts. Its persuasiveness is higher, which could become an added risk as the model gets smarter.
Access and cost: o1-preview and o1-mini are available immediately in ChatGPT for Plus and Team users, and in the API for tier 5 users. OpenAI plans to make o1-mini available to free ChatGPT users soon.
The o1-preview API costs $15 per million input tokens and $60 per million output tokens; o1-mini API is 80% cheaper at $3 per million input tokens and $12 per million output tokens. Note that o1 will use "reasoning tokens" that end users do not see but are billed as output tokens and count toward the 128K context window limit.
Features and future development: Currently, o1 lacks many features. OpenAI plans to iteratively deploy features currently in GPT-4o but lacking in o1: Function-calling and structured outputs, vision recognition, larger context. fine-tuning, etc.
Why the new naming convention and calling it o1? Since the reasoning capability is a new basic capability, they reset the numbering to show o1 is different from the GPT series of LLMs. The “o” stands for OpenAI.
How to use it: Since the o1 models are a different kind of model, the best way to prompt it may be different. Andrew Mayne has been using it and has good advice.
The two o1 models are o1-preview and o1-mini, which is much smaller than o1-preview. o1-preview is an early checkpoint. The o1-mini has performance on bar with o1-preview, it’s the better option for most use cases for now.
"Don’t think of it like a traditional chat model. Frame o1 in your mind as a really smart friend you’re going to send a DM to solve a problem. She’ll answer back with a very well thought out explanation that walks you through the steps." - Andrew Mayne's o1 prompting advice
AI Tech and Product Releases
While o1’s release dominated, there were other releases this week.
Mistral released Pixtral 12B, its first multimodal AI model, which can process both language and images. The Pixtral model is not publicly available via API but can be downloaded from Hugging Face for individual testing. Pixtral 12B stands out by supporting an unlimited number of images of any size, with a complex structure featuring 40 layers and 32 attention heads, indicating robust computational power.
Google has released DataGemma, a collection of open LLMs designed for data analysis tasks. DataGemma comes in 3 parameter sizes up to 27B parameters: DataGemma-2b, DataGemma-7b, and DataGemma-27b. They are trained on a diverse dataset of 3 trillion tokens and can perform tasks such as data manipulation, analysis, and visualization using natural language instructions.
One new feature of the DataGemma models is RIG (Retrieval-Interleaved Generation), a new term introduced by Google for DataGemma, that enhances Gemma 2 by retrieving trusted information inline (from Google’s Data commons) to check facts, reduce hallucinations and improve factuality.
Google is rolling out its conversational AI feature Gemini Live to free Android users. Users can interrupt responses with new information and receive text transcripts of their interactions. Gemini Live offers ten new voice options, and more features are promised soon.
Hugging Face adds feature to query all 200,000+ HugginFace datasets in SQL directly from the browser. This enhancement enables data exploration and analysis without the need for downloading datasets, providing a more efficient way to interact with the vast collection of datasets available on the platform.
AI Research News
Our AI research highlights for this week focus on LLMs:
LLaMA-Omni: Seamless Speech Interaction with Large Language Models. This paper came with the release of Llama-3.1-8B-Omni.
Attention Heads of Large Language Models: A Survey
Towards a Unified View of Preference Learning for LLMs
Imitating Language via Scalable Inverse Reinforcement Learning.
OneGen: Efficient One-Pass Unified Generation and Retrieval for LLMs. The OneGen paper approach to an inline factual retrieval is similar to the retrieval-interleaved generation (RIG) concept used in DataGemma mentioned above.
Learning vs Retrieval: The Role of In-Context Examples in Regression with LLMs
AI Business and Policy
Facebook and Instagram are making AI labels less prominent on edited content. Meta is updating its AI content labeling on Facebook, Instagram, and Threads. The "AI Info" tag, previously visible beneath the user's name, will now be hidden within a menu. This change, starting next week, aims to reflect the degree of AI usage in edited images and videos more accurately.
OpenAI Fundraising Set to Vault Startup’s Valuation to $150 Billion. OpenAI is currently negotiating to raise $6.5 billion in equity financing at a valuation of $150 billion. This new valuation marks a significant increase from its previous $86 billion earlier this year, positioning it among the most valuable startups globally.
The White House met with AI tech leaders this week and outlined steps to maintain US leadership in AI. They announced a new group to manage AI datacenter infrastructure, led by the National Security Council, National Economic Council, and the Deputy Chief of Staff's office, to keep the U.S. a leader in AI development, driven by fears of China.
We lost the great actor James Earl Jones this past week, but his voice of Darth Vader will live on, thanks to AI. We may see AI immortalize more actors, singers, and entertainers over time.
AI Opinions and Articles
OpenAI’s companion blog post “Learning to Reason with LLMs” shared a graphic showing AI model performance scaling with increasing inference-time compute.

On X, Dr JimFan excitedly says:
This may be the most important figure in LLM research since the OG Chinchilla scaling law in 2022. The key insight is 2 curves working in tandem. Not one.
People have been predicting a stagnation in LLM capability by extrapolating the training scaling law, yet they didn't foresee that inference scaling is what truly beats the diminishing return. – Dr Jim Fan
In other words, the o1 model use of test-time compute represents a new scaling paradigm, inference-time scaling. Scaling performance via serving means we are no longer bottlenecked by pre-training.
Andrew Batutin says:
“Inference time training is probably the most important innovation o1 has.”
This breaks the limits of next-token generation in LLMs with regards to reasoning. Also importantly, it looks like reasoning improvement doesn’t require scaling the number of parameters. o1-mini is a good reasoning engine; it’s a capability distinct from embedding knowledge in parameters.
o1-mini is the most surprising research result I've seen in the past year obviously I cannot spill the secret, but a small model getting >60% on AIME math competition is so good that it's hard to believe. - Jason Wei of openAI