


AI Year 3, pt 2: The Fourth Turning
The rise of AI reasoning models and the four-layer AI stack.


Introduction
This AI Year 3 Article Series covers the current state of AI and asks the question:
Where do things stand in AI, 2 years after ChatGPT kicked off the AI revolution?
In Part 1, we discussed the o3 model release and concluded with the thought:
The o3 model confirms that AI reasoning models are a new class of AI model.
In this second installment article, Part 2 – The Fourth Turning, we put the AI reasoning model into the context of generative AI models and AI progress overall.
The Fourth Turning
The o1 and o3 models changed everything in AI. The o1 model validated test-time compute (TTC), like GPT-2 did for pretraining. The o3 showed that it can scale far, like GPT-3 did for pretraining scaling, making o3 the GPT-3 of TTC scaling. In the process, they opened up a new class of reasoning AI models.
To put o1 and o3 models in context: It’s the fourth turning point in the evolution of frontier AI models and LLMs. Every turning point in the evolution of generative AI since the development of the transformer architecture has been about taking an innovation and scaling it. It is not merely scaling what came before, but it is also scaling in a new direction or over a new dimension of capabilities.
1. Scaling pre-training - GPT-2 & GPT-3: It started with the transformer-based architecture in the “Attention is All You Need” paper, which enabled massive parallelism in training AI model for language processing. This led to massive scaling of language models into Large Language Models (LLMs), including the pioneering GPT-3.
2. Instruction-following - Instruct-GPT, ChatGPT, GPT-4: To create a usable interface to LLMs like ChatGPT required training LLMs to follow user instructions; hence the creation of Supervised Fine-tuning (SFT). This turned GPT-3 It is underappreciated that GPT-4 is an incredible LLM not just by scaling pre-training, but by the extensive amount of reinforcement learning through human-feedback (RLHF) that fine-tuned GPT-4’s behavior to human preferences.
3. Multimodality – GPT-4o: To make truly general AI world models, we need to get outside the constraint of text alone. Adding voice capabilities has turned chatbots into friendly voice-based assistants; adding vision made assistants that function as eyes for a blind person and can navigate websites to support agentic tasks.
4. Reasoning – o1 / o3 models: Chain-of-Thought (CoT), Process reward model (PRM) and Test-time compute (TCC) combine to enable AI reasoning models.(*)
(*) Terminology note: The term LLM is becoming dated and obsolete for models that go beyond text to visual understanding and utilize inference tokens (via test-time compute) for reasoning far beyond token-at-a-time generative LLMs. The term “frontier AI models” is used for SOTA AI models, but these new AI model operate in a specific way and thus deserve a specific nomenclature - AI reasoning model. We shall see if the AI world agrees with AI reasoning model as a term or uses other terminology.
LeCun and the Cake Analogy
Meta’s chief AI scientist Yann LeCun predicted quite well the development of LLM training back in 2016, when he introduced his now-famous “cake analogy” at NIPS 2016:
“If intelligence is a cake, the bulk of the cake is unsupervised learning, the icing on the cake is supervised learning, and the cherry on the cake is reinforcement learning (RL).”
Each of the three components of the cake have been important ingredients to making advanced generative AI models. Test-time compute is like a dollop of whipped cream on top of the cake.
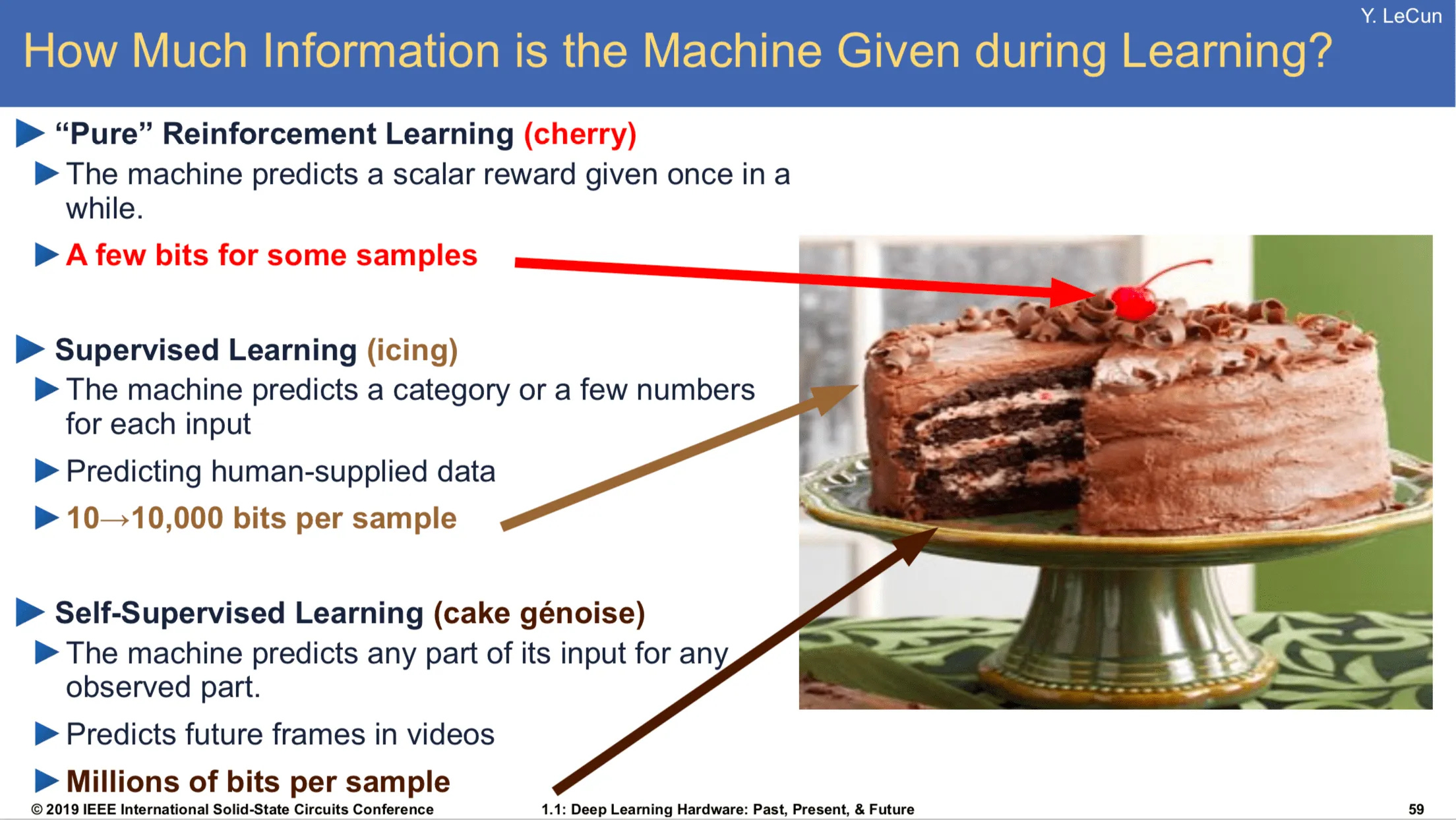
The Four Layer Cake of AI Technology
To twist the Yan LeCun analogy a little bit, it’s helpful to think use a layer-cake as an analogy for technology stacks. Complex informational technologies are built as a technology stack: Complex software is built on components and libraries, underlying protocols, and hosted on complex computing platforms. Internet technology, for example, is implemented in a standardized 7-layer protocol stack.
The Generative AI technology stack has a foundation based on the transformer architecture. Then it builds and constructs the AI itself through training in higher layers. The next layer is the pre-training and scaling that pretraining, as used to make LLMs, including multi-modal LLMs; then in post-training performing SFT for instruction-following and RLHF with specific fine-tuning in post-training for chain-of-thought (CoT), using reward modelling to support reasoning; and extending the power of reasoning via test-time compute (TTC).
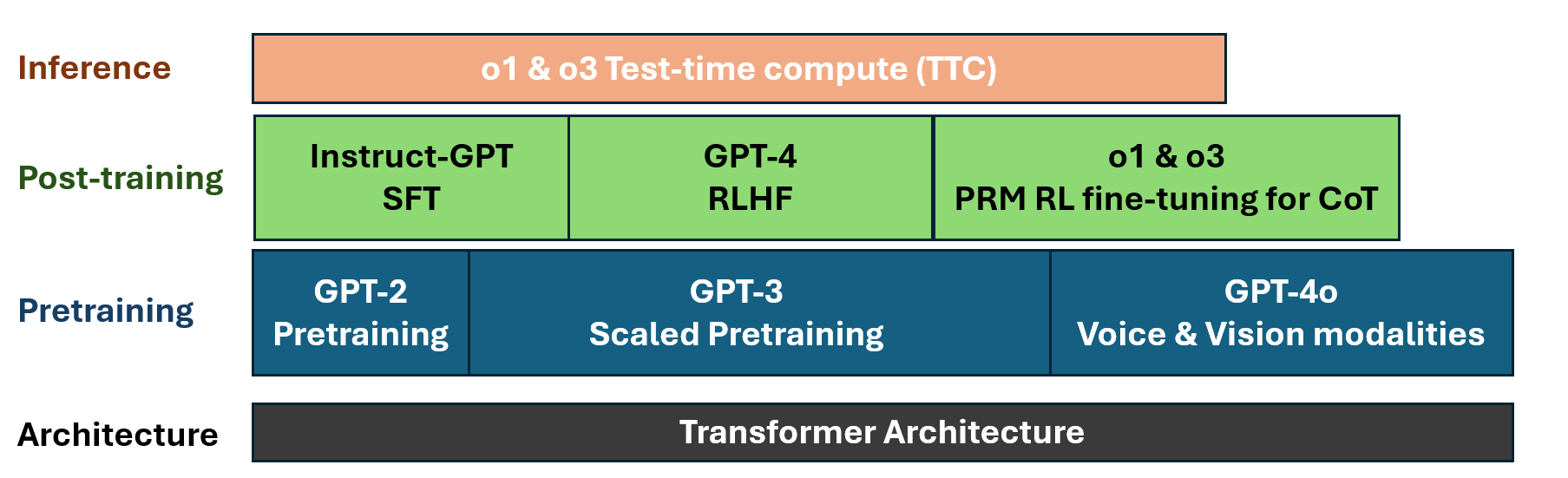
AI reasoning and the path to AGI
The o1 model release opened a new avenue for AI model improvement, and its o3 model successor and competitors like Qwen QWQ, Gemini 2.0 Flash Thinking, Experimental all represent a new class of AI models - AI reasoning models.
Does the announcement of o3 model change our expectations of when human-level AGI might be achieved? Are we accelerating into AGI? Possibly yes.
My prediction of “AGI in 2029” was based AGI requiring three more ‘turns of the crank’ (GPT-5, GPT-6, GPT-7 equivalents), and that each turn would take perhaps two years. The o3 model is not just another turn of the crank, it is another dimension of capability advance. It will make it easier to go further, as we have another dimension to push progress.
Look at it this way: At each level of the 4-layer AI cake, in architecture, pre-training, post-training, and in test-time compute, there is an opportunity to innovate, scale and optimize. It’s not just about scaling with brute force, but scaling by improving efficiency. We have another dimension and greater opportunity to scale more and innovate faster. So … acceleration?
Not so fast. Didn’t Sam Altman promise a GPT-5 that improved on GPT-4 as much as that improved on GPT-3? Where is it? The surprise gains with o3 and test-time compute begs a question of why pre-training scaling hasn’t worked to deliver a model that goes far beyond GPT-4o, yet.
If we’ve hit a wall in pre-training, then scaling pre-training could be over. Ilya Sutskever hinted at as much in his recent NeurIPS keynote, suggesting we are close to Peak Data with “There is but one internet.” Hitting a data wall could block the path to AGI, unless we find a way, around or through that wall.
We will consider the possible paths to AGI, how our priors need to change, what 2024 predictions we got right and wrong, and what we can expect in AI progress in 2025 and beyond. All to come in the next installments in the series.
PostScript
There’s a double-meaning in Figure 1. If you are reading this on New Years Day, it’s my birthday. I’m on vacation for this New Years week, and we will skip the usual AI weekly news and focus on next installments in this series, which are in the works and will be out soon. Happy New Years and thank you for being a reader of this newsletter!
Happy birthday! Great article as always