


AI’s Next Level
The path forward for AI evolution in AI interfaces, memory and reasoning.


The Big Picture - Rapid yet Incremental
It’s been a busy summer for new AI releases. With the arrival of Grok-2, we can count no less than five frontier LLMs: Claude 3.5 Sonnet, GPT-4o, Gemini 1.5 Pro, Llama 3.1 405B, and Grok-2, all of them released in the past 3 months. Qwen 2 and Yi Large from China and Mistral Large from France are near-frontier AI models supporting multiple languages.
Aside from improving on core benchmarks, these AI models are also sporting new features. Some observations on where things stand:
No AI model is far ahead; Gen AI is a competitive, fast-follower technology: In contrast to 2023, when GPT-4 was far ahead of other models, the top-tier AI models are all strong and roughly equivalent. Unless OpenAI releases a GPT-5-level AI model soon, Gen AI will remain competitive for some time.
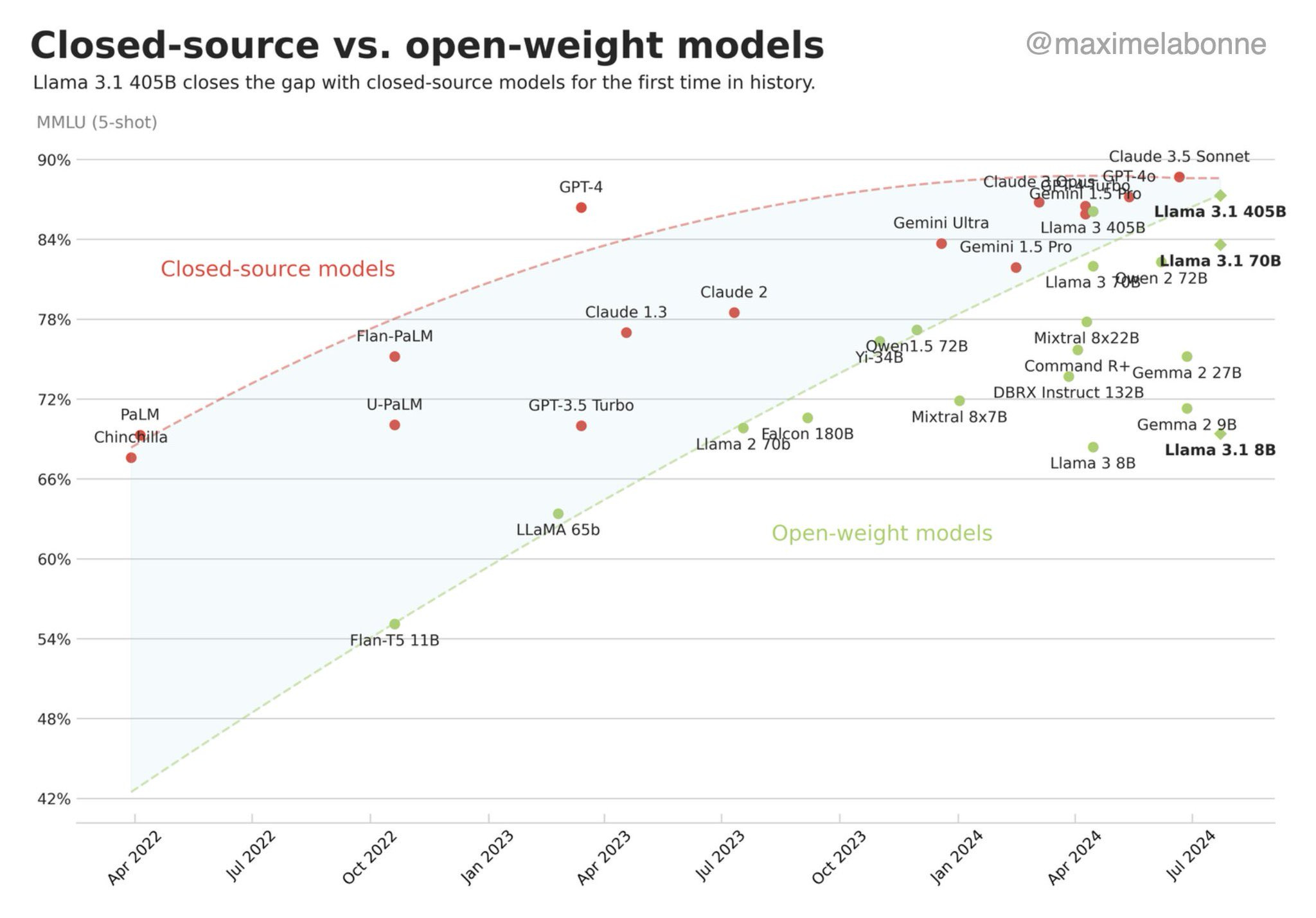
Nobody has gone far beyond GPT-4 in core LLM reasoning: How is it that no released AI model that has gone far beyond GPT-4, trained in 2022? Current frontier AI models are faster and better than GPT-4 overall, but reasoning improvements have been incremental not fundamental.
Many innovations are happening outside the core LLM: The AI application layer is improving steadily, while many AI model improvements involve incorporating capabilities previously outside the AI model. The AI system is growing beyond the LLM.
AI advances are both rapid and incremental: Innovations and features in three key aspects of the AI stack - interface, memory, and reasoning – are making AI models and applications more useful and practical. It’s not one big breakthrough, but many small advances adding up to make AI much better now than just a short time ago.
This article will cover this last point in more detail, covering improvements in interfaces, memory and reasoning that are taking AI to the next level.
Innovations in AI Model Interfaces
Features involved the interface include modalities – types of inputs, artifacts, and helpers – extending AI with tools, functions, guardrails, etc. and supporting features.
Interfaces are improving with the addition of voice input-output – both GPT-4o and Gemini now have voice mode – document digesting, and image understanding. We’ve also noted various customization interfaces and methods. We are moving beyond the chatbot.
Modalities: AI interfaces are moving beyond text to full audio-video as interface modalities. Audio is important because it is more natural – GPT-4o voice mode impressed us all with its naturalness and low latency. In the near future, we can expect multimodal AI interfaces combining text, voice, and visual inputs. In the long-term future, expect haptic feedback systems for more immersive interactions (like we see with gesture control of Apple VisionPro headset) and even further out, brain-computer interfaces for direct neural control.
Artifacts: Claude Artifacts showed the high value of separating output types and creating work products, such as running code, directly. Different types of output - work-in-progress, thinking, final output of code, written/spoken response, structured output – serve different purposes. When you ask an AI model to produce code, a data analysis chart, or an image, you want the work product produced.
Adaptivity: Adaptive user interfaces dynamically adjust AI models based on user behavior and preferences. We are moving in that direction with personalization and AI model customization for users. ChatGPT memory also provides that. The AI model should remember all your prior interactions so that it can accommodate your preferences; this is done with memory of personalization data (see below).
Helpers are functions that simplify and improve user experience in interacting with an LLM, such as prompt management: Rewriting and optimizing the prompt (magic prompt); templates for prompts and interfaces for storing and reusing prompts. Helpers also includes guardrails to ensure prompts and responses are “helpful and harmless”.
Innovations in LLM Knowledge, Memory and RAG systems
Memory in AI systems is about grounding knowledge, adapting to personalized information, and understanding context.
Memory is improving in leading AI models with features like memory collection (like ChatGPT’s memory controls).
Knowledge-grounding has been done via retrieval augmented generation (RAG), but now larger contexts and context caching can also assist with handling knowledge-grounding tasks, such as responding to queries over large documents. At the same time, RAG systems have gone from naive and simple to more complex.
To improve factual accuracy, AI systems are augmenting basic RAG with re-ranking methods, automatic fact-checking, and source verification for improved reliability. Instead of simple conveying of facts, more complex systems are Cross-domain knowledge synthesis for more comprehensive insights hese systems
Context caching, for efficient repeated use of same information base, is perhaps the biggest new feature in recent months to assist with memory-laden tasks. Both Gemini and Claude now have context caching, and both also have generous context windows, making these features practical. With larger contexts, more information can become in-context memory.
Personalized information is information about individual users, to tailor' interests and expertise. Customizing memory by storing interactions prior or inputs, such as knowing user’s style preferences or personal information to help as an assistant. Personalized AI assistants that learn and remember user habits and preferences. AI models will continue to get better at this.
Finally, accessing and understanding real-time information makes AI far more useful. Currently, AI models use web search to retrieve current information, then respond with (hopefully) a grounded answer.
Asking, “Which NFL team had the highest scoring win last Sunday?” yielded a correct response from ChatGPT, and Gemini, but Microsoft Pilot flunked it, giving a historic win from last year, not last Sunday.
It’s a reminder that most AI memory features are great when they work, but are not always reliable. In future, AI models will be fed contextual understanding based on user location, time, and sensory input from surrounding environment.

Improving LLM Reasoning
Reasoning in AI models and applications are getting improved in several ways:
First, the LLM prompt itself can induce better reasoning, with Chain-of-Thought (CoT) and Tree of Thoughts (ToT) prompts to explore multiple reasoning paths. This can improve reasoning, but only to a point.
Second, the instruction-tuning (post-training) process can train the LLM to reason better automatically. Instruction fine-tuning, done via SFT or RLAIHF, improves reasoning by incorporating CoT (chain-of-thought) into the response, then creating a reward function to reward correct responses. We have learned that a Process Reward model, one that rewards correct logical steps, in the instruction-tuning flow improves reasoning.
The third path to improved reasoning is outside the LLM, with search, iteration, and review of LLM responses.
Break complex multi-step reasoning problems into manageable sub-tasks, go step-by-step, and use a search process to search through each step.
Iterative refinement of solutions through self-critique and improvement.
MultiOn’s recently announced AgentQ uses MCTS (Monte-Carlo Tree search), self-critique, and DPO-based fine-tuning to enhance AI reasoning. This is similar to the approach for AI reasoning in “Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing.”

Iteration on reasoning takes you to the realm of agents. To support this evolution, AI models like GPT-4o are now supporting structured (JSON) outputs and function-calling, so that the AI models can be more pluggable into agent flows. Models such as Llama 3.1 are now tuned for reasoning and agentic use:
New in Llama 3.1 compared to Llama 3 is that the instruct models are fine-tuned on tool calling for agentic use cases. There are two built-in tools (search, mathematical reasoning with Wolfram Alpha) that can be expanded with custom JSON functions.
AI reasoning will be improved as AI models evolve into AI Agents. AI agents will have more structured inputs and outputs, separate thinking from writing, and will evaluate and adjust reasoning strategies and responses.
Action, Autonomy and Agentic Reasoning
A fourth pillar (or dimension) of AI capabilities is action and autonomy, representing the capabilities around interaction with the real world. Advancing in this area is dependent on both interface advances and agentic reasoning, so we can expect virtual AI agents to develop the needed features before robotic AI agents do. We are seeing glimpses of these capabilities in AI models; they will eventually filter into autonomous AI systems.
AI’s Next Levels - A Roadmap
OpenAI has their own view of what the next AI stage is: Beyond level 1 conversational chatbots, they envision level 2 as reasoning problem solvers, and level 3 as AI agents that can take action.

I would adjust this roadmap to have more precision and focus on the vectors of innovation - interfaces, memory and reasoning - mentioned above. In this more detailed roadmap, the levels might look something like this:
Level 1: Chatbot with text-only interface.
Level 2: Multi-modal interfaces with audio & text; RAG systems, personalized information, larger context window; CoT, ToT, and ReAct; fine-tuning for reasoning; and prompt chaining.
Level 3: Omni-modal and adaptive interfaces; prompt management, context caching, and personalization; LLM as OS and subroutine; Process-reward-model based fine-tuning; artifacts; complex RAG; AI agent support & structured I/O.

This suggested AI roadmap cannot be viewed as a very long-term roadmap. Level 2 has been achieved in leading AI models, and many Level 3 features have been partially implemented in released AI models or as research.
We will soon (within a year) have most or all leading AI foundation models and their supporting AI application encompass the “Level 3” feature roadmap above.
Conclusion
AI is advancing rapidly, with new advances on a week-by-week basis, but each step is incremental. Many advances and improvements are occurring outside the foundation AI model.
Expect more innovations both in AI models and the wider AI ecosystem. Also expect the “design convergence” of multiple AI model providers supporting similar features other AI models develop that prove useful and successful.
AI’s advance to its next level will be rapid, incremental, and converging, with many leading AI models more similar as they share AI’s “must-have” features.
The third path is the way:
> MultiOn’s recently announced AgentQ uses MCTS (Monte-Carlo Tree search), self-critique, and DPO-based fine-tuning to enhance AI reasoning. This is similar to the approach for AI reasoning in “Toward Self-Improvement of LLMs via Imagination, Searching, and Criticizing.”
Thank for spotting AgentQ last week, Patrick. It's disappointing that there's only two in this category, and no open-source. But I believe this third step is key. In trying to solve a task and traversing the search trees towards a solution, a model has to learn from the process-- just the way we would. Parameters have to be tweaked each time absorbing the tricky aspects of every success and failure.
It's sobering to think that true reasoning is going to need real-time training, inference won't be good enough. Won't that upend a lot of AI cloud strategies...