
Boom! GPT-4 has arrived!
LLMs go to college and pass the LSAT!

OpenAI’s GPT-4 has been announced for limited release, and a waitlist for access has been made available. Get on the waitlist here.
They have written and shared a technical report on GPT-4. As some rumors had suggested, it does accept image input as well as text, and produces text only output. Not surprising, it’s a better LLM than ever, and while it may be an incremental advance on GPT-3.5turbo in chat-GPT, it’s going to really shake things up with its “better-than-human” performance on some tasks:
We report the development of GPT-4, a large-scale, multimodal model which can accept image and text inputs and produce text outputs. While less capable than humans in many real-world scenarios, GPT-4 exhibits human-level performance on various professional and academic benchmarks, including passing a simulated bar exam with a score around the top 10% of test takers.
Their Table 1 reports on how it achieves smart-human-comparable results on the SAT, AP tests, LSAT, GRE, and others tests, achieving 90th+ percentile in several of these tests including a 710/800 on SAT.

As for the academic benchmarks used to evaluate the performance of LLMs, their Table 2 shows that GPT-4 has raised the bar and is the new state-of-the-art on a range of benchmarks.
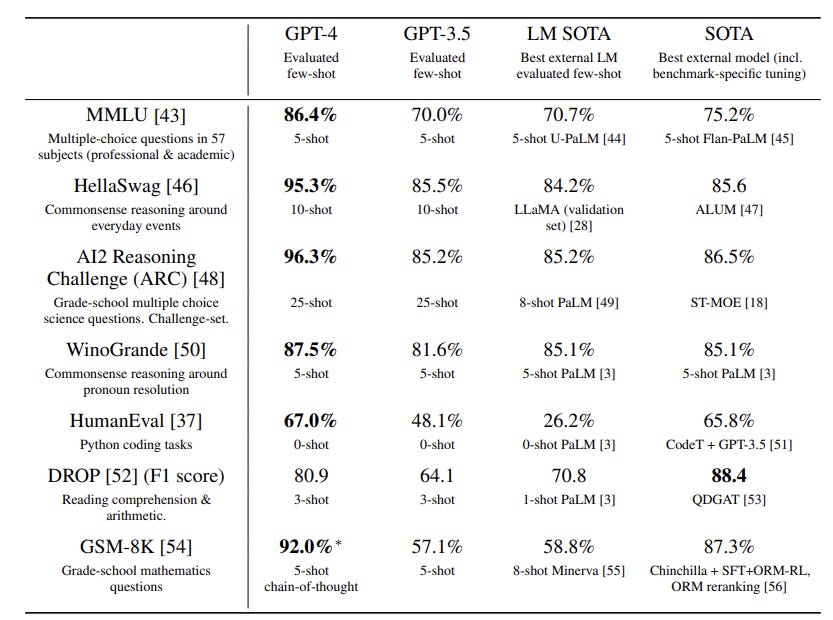
If earliest LLMs were in grade school, and GPT-3 was in High School, this is the LLM that is now a high-level college student.
Further, the tech report says “GPT-4 substantially improves over previous models in the ability to follow user intent.” This is a good step forward for ease-of-use and raises the question of how that impacts the utility of prompt engineering. Since its heritage is GPT-3 / chatGPT / bing chat, it still has some of the same pitfalls, such as hallucinations, but they are diminished. As an improved GPT-type model, prompt engineering will help keep it on track and make it yet more relatively powerful, even though that might be less important for avoiding failures. Users will have to try it out and see where it is strong and where it breaks.
The biggest disappointment in this announcement is the lack of transparency in how that is how OpenAI is now Closed-mouthed about HOW they built GPT-4. No information on model size, training etc.
Given both the competitive landscape and the safety implications of large-scale models like GPT-4, this report contains no further details about the architecture (including model size), hardware, training compute, dataset construction, training method, or similar
We’ve had two decades of amazing progress in AI research thanks to an enormous amount of openness. To see this end would diminish innovation and progress. Looking for hints, there are some hints that it was built with similar pre-training data as GPT-3, given the training cut-off was Sept 2021. That date is surprising, since I heard Bing chat was handed over last year. It would be good to know what the comparison is to Bing chat (another GPT3.5 of GPT4 derivative). It would be clearer if OpenAI were, well, more OPEN about it.
Haven’t tried it, but the API pricing will be a lot higher than the GPT-3.5turbo, so it may be that that massive price cut was just a way to clear the deck for their latest and greatest model. If you want to get to the front of the line in trying it out, consider this:
During the gradual rollout of GPT-4, we’re prioritizing API access to developers that contribute exceptional model evaluations to OpenAI Evals to learn how we can improve the model for everyone. We are processing requests for the 8K and 32K engines at different rates based on capacity, so you may receive access to them at different times. Researchers studying the societal impact of AI or AI alignment issues can also apply for subsidized access via our Researcher Access Program.