


Connecting AI to Data with LlamaIndex
Data connectors like LlamaIndex are a key part of a robust AI Technology Stack

TL;DR - LlamaIndex is a framework specialized on connecting data to LLMs in your AI application.
The AI Technology Stack
By themselves, an LLM or Foundation AI Model like ChatGPT is powerful and helpful, but it's not enough for most useful AI applications. Useful AI applications require more than just the LLM; they require connecting to context and data, providing access to additional tools or software infrastructure, allowing for iterative and guided use of AI models, and connecting to the user via appropriate interfaces.
These challenges have led to the rise of an AI technology stack around the LLMs to support various AI application use-cases. The key components of an AI technology stack include:
Vector databases that digest information into vector form and contexts, to allow for semantic search and context look-up over documents and sets of information.
Orchestration frameworks like LangChain and LlamaIndex that enable building chained LLM queries and responses into responsive AI flows.
Validation, guardrails, and monitoring around LLMs; guardrails and validation provide control and monitoring around AI model interactions.
AI models / LLMs such as GPT-4 accessible via an API for a cloud-hosted model, or alternatively running in a local environment.
Plug-ins that extend the power of LLMs by giving them access to other tools.

Figure 1. The AI Technology Stack.

Connecting Data to Your LLM
To be useful on any practical and useful application, AI models are connected to various kinds of data and can work flexibly with them. Why do we need to connect data to an LLM? Some of the issues with just using LLMs directly:
Truth-grounding: LLMs embed world knowledge and so can answer general questions, but this information is not reliable and the LLM can sometimes hallucinate. How to ensure the answer is reliable and fact-based?
Local data: How do you get an AI model to understand your own local data and information, so you can analyze and answer questions on it? What if you want to keep your data private? It’s a serious dilemma for enterprises that do not want to send proprietary data to an external API.
There are various ways of getting information into an LLM context. Paradigms for inserting knowledge include:
Data inclusion in prompts for in-context learning: This puts the text information in the prompt input for the LLM to digest directly. This works well for documents and text snippets short enough to fit into the context window. However, a large document or document set will at some point exceed the context window size. Moreover, if the document is large and the question is about a specific detail within the document, then importing a massive text context just to search for specific information in a small subset is a very expensive and inefficient; there’s a better way.
RAG - Retrieval Augmented Generation: This uses a Vector database to store the full information, take in-context information to generate a query of the database, retrieve specific information and do an AI model query on that retrieved context. This solves the problem of limited context windows and the inefficiencies of using an LLM for search over a large amount of information. The vector database is tailor-made for semantic search retrieval, where queries about specific information can be matched against embeddings in a vector DB to extract relevant contexts for a query.
Import data through LLM training or fine-tuning: As an LLM does pre-training, it gains world knowledge over the corpus of text it is trained on. To tune this for a specific application, one could fine-tune the LLM on a specific set of information. This is impractical for addressing a single query, of course, but is a method to incorporate data across a domain for domain-specific models. One example application might be a “repair information chatbot” that guided you on troubleshooting a specific product, where the fine-tuning is over the specific product information.
With various methods to connect data to your LLM, and many various types of data, stored in different file formats and database types, it would be nice to have a unified connector for the builders of AI applications, to flexibly use the right method in these different use cases.
That’s where LlamaIndex comes in. LlamaIndex is a framework specialized on connecting data to LLMs in your AI application.
How LlamaIndex Works
As part of the AI ecosystem, LlamaIndex acts as a connector that structures your data and makes it available to your LLM or AI model. It doesn’t replace data stores, but it needs to know how to get data in and out of them. The main components of LlamaIndex are:
Data connectors: Hook up data from various data sources (APIs, PDFs, docs, SQL and other databases).
Data indices: Structure your data for different use cases.
Query interface: Interface to the input prompt and LLM and return data via natural language or structured data.
More in depth information on how it works can be found in LlamaIndex founder Jerry Liu’s video presentation on LlamaIndex. We went ahead and used LlamaIndex and share some results below.

Using Llama Index
Users can try out LlamaIndex without installing it locally by using the HuggingFace sandbox available here, and using a provided Sqlite database. We are able to write LLM queries on this data and retrieve an LLM answer on that data. This quick test illustrates the strengths of LlamaIndex; it’s able to use a local database to inform queries about the data on an LLM and quickly produce results.

Running LlamaIndex locally is a more useful and interesting use case, so we installed LlamaIndex from Github, set it up with an (OpenAI LLM) API key and ran the tutorial provided by LlamaIndex’s website.
This uses a database built on an essay by Paul Graham. Connecting LlamaIndex to that document, we were able to get the LLM to accept and answer rudimentary questions about it.

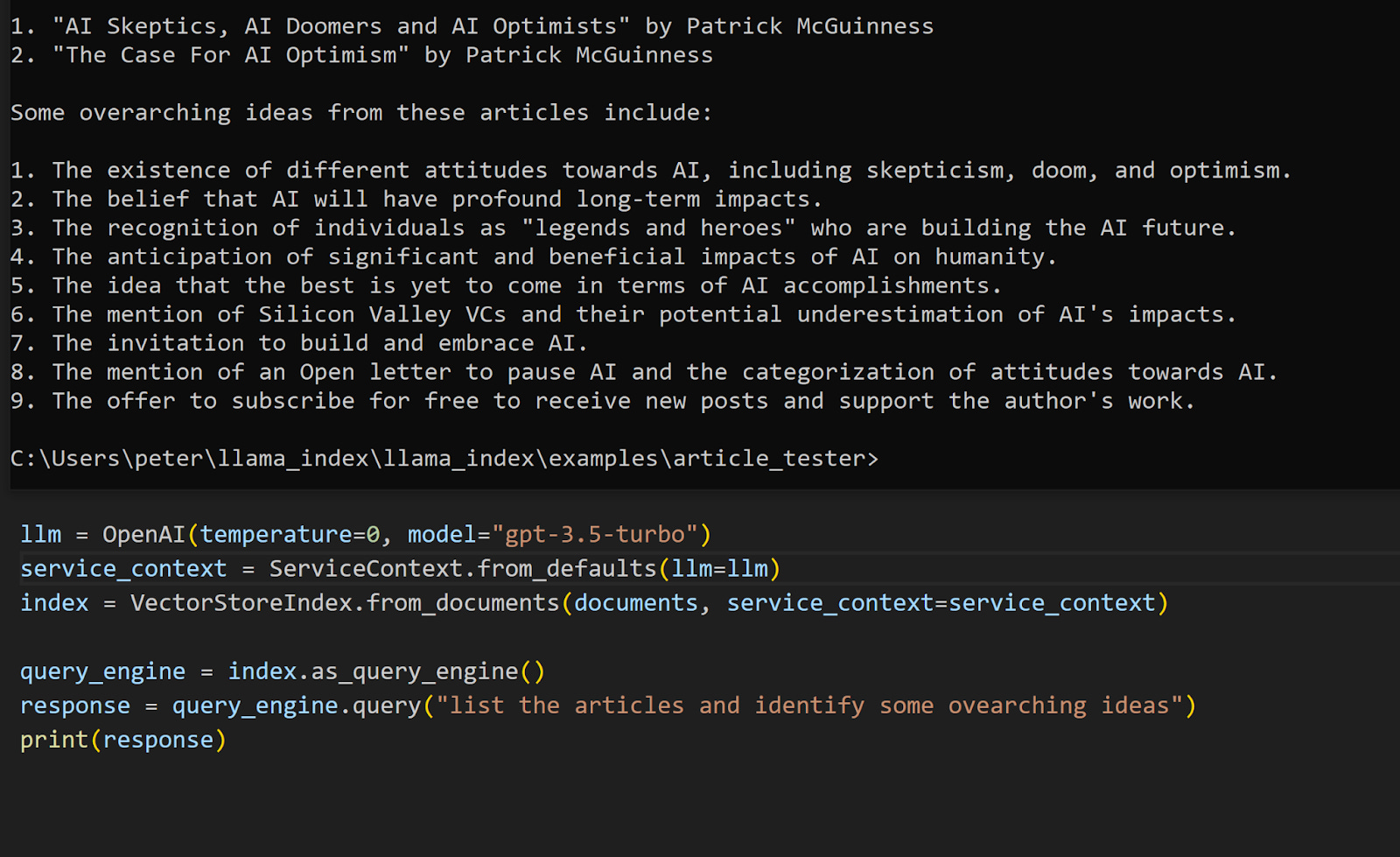
Since real-world use cases will be on private data, the next thing we did was create a database from our own data, using articles from the “AI Changes Everything” substack.
Setting this up is fairly simple in LlamaIndex. It ingests the local articles into vector form to inform the LLM of the context of our queries. Our LLM is now able to use that data to provide a response regarding the article.

Our original attempt at an article summary had incorrect or misleading information from our article, such as Yann LeCun being classified as a skeptic, and Sam Altman as an Optimist. We were using the default text-davinci-003 model originally, which was not accurate enough. Switching over to the improved gpt-3.5-turbo model gave us more accurate answers. We could use GPT-4 if we wanted even better results.
When we expanded our ingested dataset for LlamaIndex and used a more powerful LLM, we began to get more interesting results. It has a wide variety of connectors, so it can ingest a variety of text file types, including PDFs, spreadsheets and text data through some APIs, feeding them into VectorStores for retrieval. From this, it can generate appropriate responses based on any selected data set, including your own private local data.
LlamaIndex Use Cases
When you start to add more data to LlamaIndex and operate on that with a powerful LLM, it reveals its true usefulness. Accessing the vector store via LlamaIndex to establish proper data context provides clear advantages to using an LLM alone; an LLM alone requires much more effort and has limitations in context and data ingestion.
Some of the situations LlamaIndex is most helpful with:
Semantic search: Asking a detailed semantic query over a large dataset can be addressed with a flow combining a vector database and LLM. LlamaIndex can easily script such flows for semantic search and retrieval-augmented generation.
Synthesis over heterogeneous data: If you have a query over a diverse data set, it is a helpful tool for aggregating the data of different types, defining a common index of them, and enabling LLM queries across the full dataset.
These capabilities translate into many real-world applications. You can make an interface to your own local data for personal semantic search. Businesses can use it to create customer service AI apps that tap into corporate knowledge bases, and they can provide natural language interfaces to their business data. Creativity will find other uses.
Data privacy is a challenge. If you don’t mind letting some of your private data ending up in the context window of an external API, you can use OpenAI’s models or other external AI models. If you do care about data privacy, you can either run an LLM locally (where you are limited to smaller LLMs) or use a cloud-hosted private LLM.
Conclusion
As a way to connect data to language models, LlamaIndex addresses a key challenge in building useful AI applications around powerful AI models. There are other frameworks, such as LangChain, but LlamaIndex hits a sweet spot in terms of data management in the AI technology stack, and so is likely to co-exist with these alternatives, and assist in building powerful AI applications.