
Data Is All You Need
Phi-3 7B, Hugging Face's FineWeb 15 T dataset, and the new scaling laws


TL;DR - Another SOTA best-for-its-size LLM, Phi-3, has been released in 3.8B, 7B, and 14B sizes. HuggingFace released FineWeb, a 15T token dataset. These releases and the recent Llama 3 release are highlighting the importance of data, both quantity and quality.
Llama 3 Is Kind of a Big Deal
Meta’s release of Llama 3 has been ground-breaking and welcome on a number of levels.
Meta’s original Llama release a year ago unleashed an open source LLM movement. They built effective fine-tune LLMs on top of Llama, starting with Alpaca; they set up locally running AI models; they created AI agents as well. Now, Llama 3 8B and 70B supercharges these efforts with high-quality LLMs.
For example, I’ve got Llama 3 8B running locally on ollama; it’s a fast and easy way to set up a local AI model. If you want speed, LPU chip-maker Groq’s self-hosted inference service at Groq.com will run Llama 3 at hundreds of tokens per second.
In the past, only GPT-4 was able to be the under-the-hood LLM for an effective AI agent. Now the AI builders are pairing Llama 3 with CrewAI to create effective agent experiences.
Here Come’s Phi-3 … Even Better!
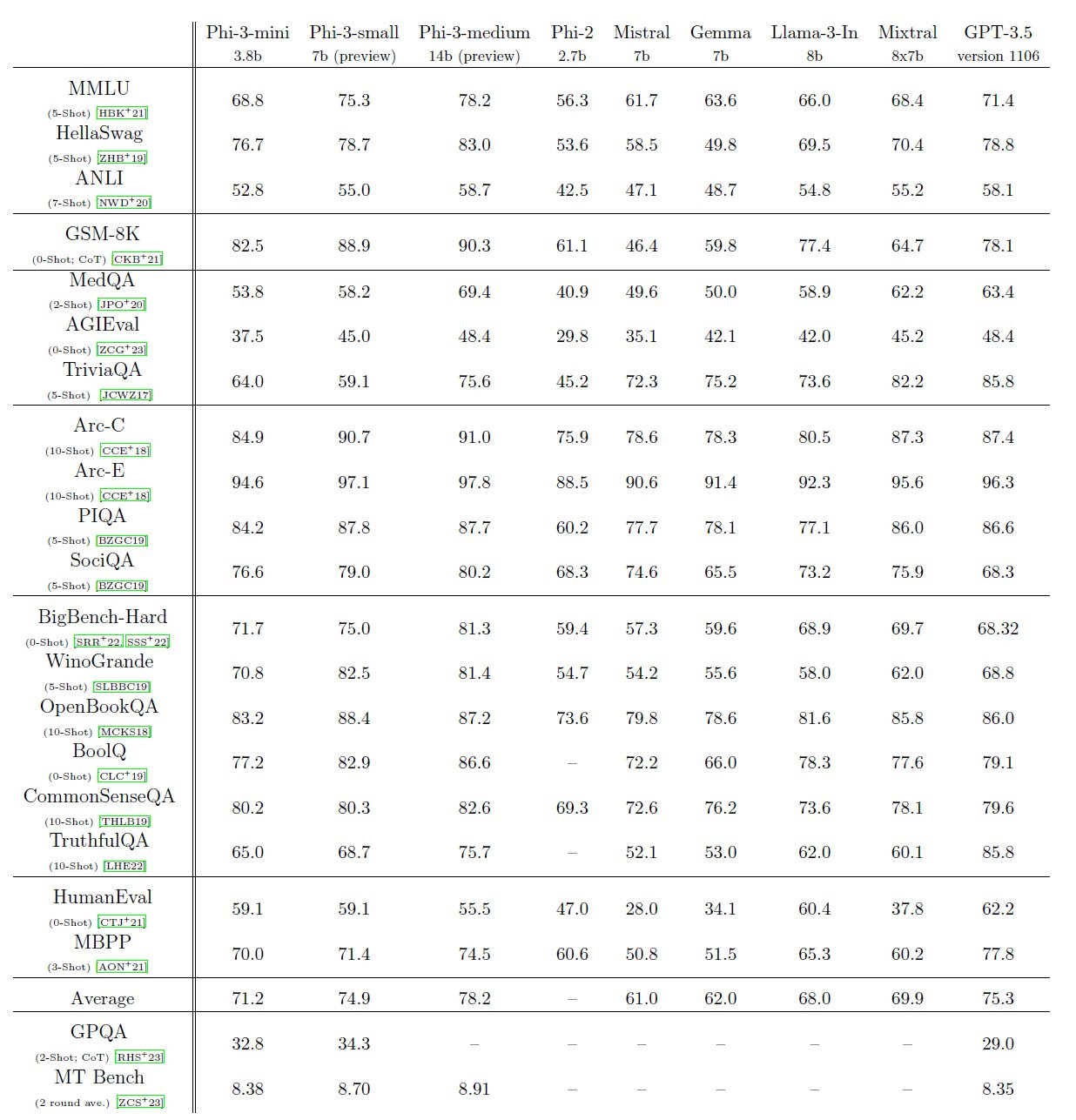
In breaking news, Miscrosoft has released Phi-3, in 3 sizes, phi-3-mini (3.8B), phi-3-small (7B) and phi-3-medium (14B), and it gets fantastic benchmark scores.
Phi-3-mini (3.8B) is trained on 3.3 T tokens, it gets 69% on MMLU and 8.38 on MT-bench benchmarks, rivalling models like Mixtral 8x7B and GPT-3.5.
Phi-3-small (7B), trained on 4.8T tokens, beats Llama-3 7B with an MMLU of 75.3 and 8.7 on MT-bench.
Phi-3-medium (14B), trained for 4.8T tokens, achieves 78% on MMLU, and 8.7 and 8.9 on MT-bench. This is SOTA for its size and takes it closer to much larger models in performance.
The full benchmark numbers are below. The Technical Report on Phi-3 says:
The innovation lies entirely in our dataset for training, a scaled-up version of the one used for phi-2, composed of heavily filtered web data and synthetic data. The model is also further aligned for robustness, safety, and chat format.
Microsoft will be releasing the LLM model weights for Phi-3 models by the time you get to read this, and it too will be a great set of LLMs for local use and fine-tune customizations.
LLM Inference is a Commodity
Meta Llama 3’s edge in high-performance-for-size came from LLM training that was done on a massive amount of data: 15 trillion tokens.
Phi-3’s edge in high-performance-for-size came from LLM training that was done on higher quality data: 3 trillion tokens.
By being high-quality for their size, Llama 3 and Phi-3 cut the cost of inference.
The recipe for a good GPT-4-level LLM is now known: Fifteen trillions of tokens/words of data; 7M GPU hours of H100 compute; and the machine-learning team with expertise to train an LLM. Phi-3 shows an additional path: Do dataset optimization to improve the training LLM quality for a given amount of training compute.
Our long-standing prediction that LLM inference will become a commodity is being proven out, because almost a dozen companies now can train competitive frontier LLMs. Recent AI models at this tier include Alibaba’s Qwen 1.5, Reka Core, Mistral 8x22B, Databrick’s DBRX, Microsoft Phi-3, in addition to Claude, Gemini, Llama3, and GPT-4.
HuggingFace FineWeb
“15 trillion tokens of the finest data the web has to offer.” - Hugging Face
If you were worried that the Big Tech giants will have an unassailable advantage due to their access to massive datasets, fear not: HuggingFace just released FineWeb, 15 trillion tokens of high quality web data.
The FineWeb dataset consists of more than 15T tokens of cleaned and deduplicated English web data from CommonCrawl. This is a huge increase over some other open datasets, with the exception of 30T token RedPajama V2.

FineWeb began as an effort to fully replicate RefinedWeb, but evolved into optimizing the dataset for LLM training. The main difference between Red Pajama V2 and FineWeb is that extensive effort to make FineWeb work for LLM training out-of-the-box.
As HuggingFace CSO Thomas Wolf said on X:
The majority of the work we did on Fineweb was to train the 200+ ablation models to select the best set of filters for out-of-the-box top performances on our high-signal evals.
As a result, they were able to refine the data to push this dataset to perform better for LLM training compared to prior datasets:
We filtered and deduplicated all CommonCrawl between 2013 and 2024. Models trained on FineWeb outperform RefinedWeb, C4, DolmaV1.6, The Pile and SlimPajama!
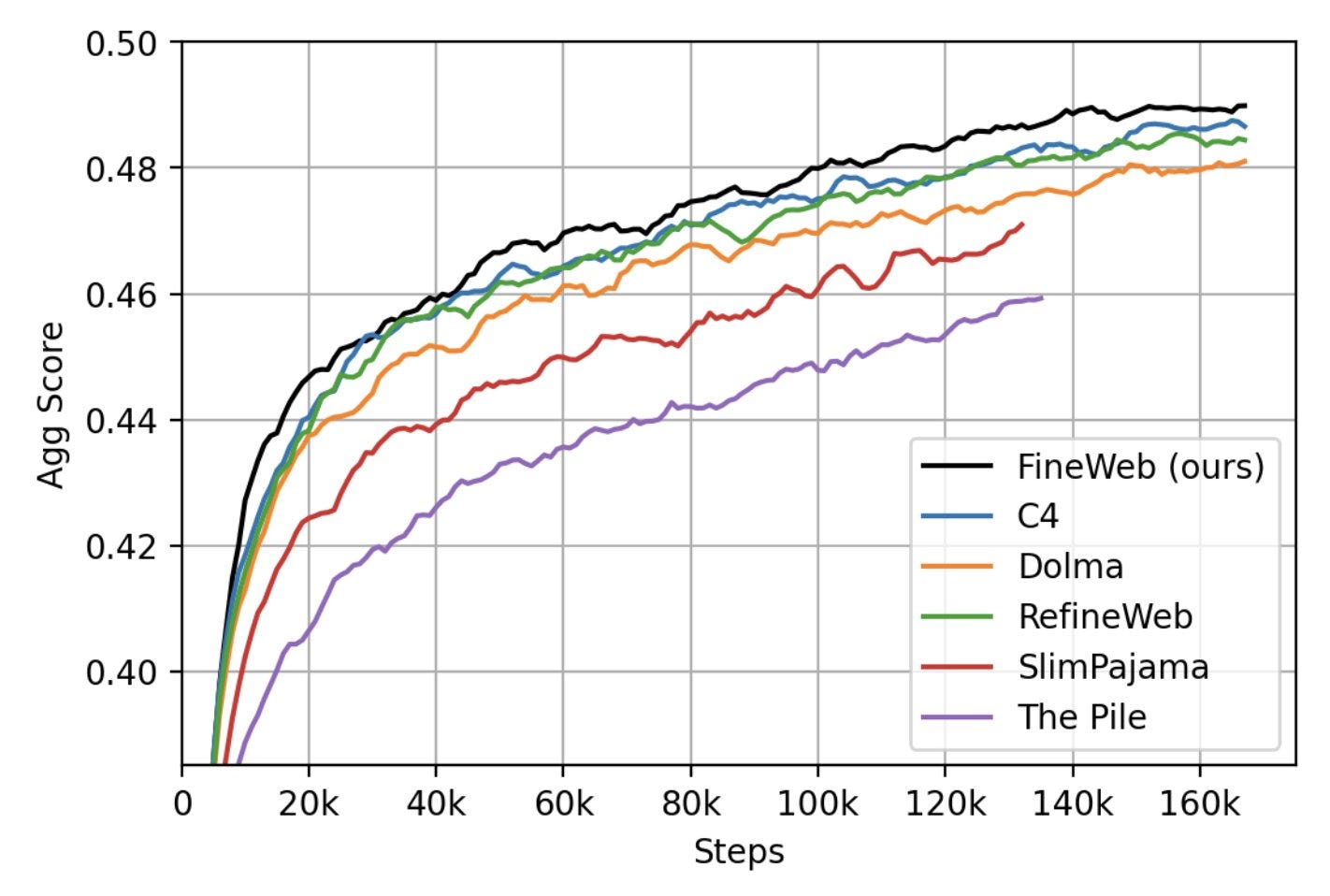
The dataset is completely open-source, including “all recipes, data, ablations models, hyper-parameters” and they plan to maintain and improve Fineweb.
New AI Scaling Lessons
The original observation that led to the rise of LLMs, that was promoted and confirmed by OpenAI with their training of GPT-1, GPT-2, GPT-3 and GPT-4, was that “Scale is all you need.”
More specifically, scaling up training data, parameter size and compute used for training, you can train a higher-performing LLM performance, that can even achieve emergent new behaviors in understanding and reasoning.
Scaling follows a power-law, which yields log-linear gains as you scale compute, date, or parameters. This power law implies that addition of compute and data will yield diminishing returns as you scale it up.

But ‘diminishing returns’ does not mean no returns. Meta found that scaling dataset and compute for Llama 3 even to the point of 2000 tokens per parameter improved LLM quality to a measurable degree. They also used a large 10M dataset for fine-tuning.
Llama 3’s lesson: Training high-quality LLMs requires massive scaling of data.
Why is it a good bet other LLMs will follow this pattern? Scaling training data and compute 10x is worthwhile to gain even just a linear increase in LLM quality, if it creates a fantastic model that beats other LLMs and you run inference trillions of times on it at high efficiency.
LLM training will have a voracious appetite for data. So much so that data could become a constraining factor on scaling LLMs.
Llama 3 set a new baseline of 15 trillion tokens for any LLM sized 8B parameters or larger. The HuggingFace FineWeb dataset announcement is welcome news because it meets that 15 trillion token baseline and will keep the open source AI model ecosystem competitive.
Data Quality Matters
We’ve known from the small-but-effective Phi models that better refined data can produce higher quality LLMs. The FineWeb dataset release and Phi-3 release have confirmed it - data quality matters.
The Phi-3 release technical report explains:
In our previous works on the phi models it was shown that a combination of LLM-based filtering of web data, and LLM-created synthetic data, enable performance in smaller language models that were typically seen only in much larger models. . For example our previous model trained on this data recipe, phi-2 (2.7B parameters), matched the performance of models 25 times larger trained on regular data.
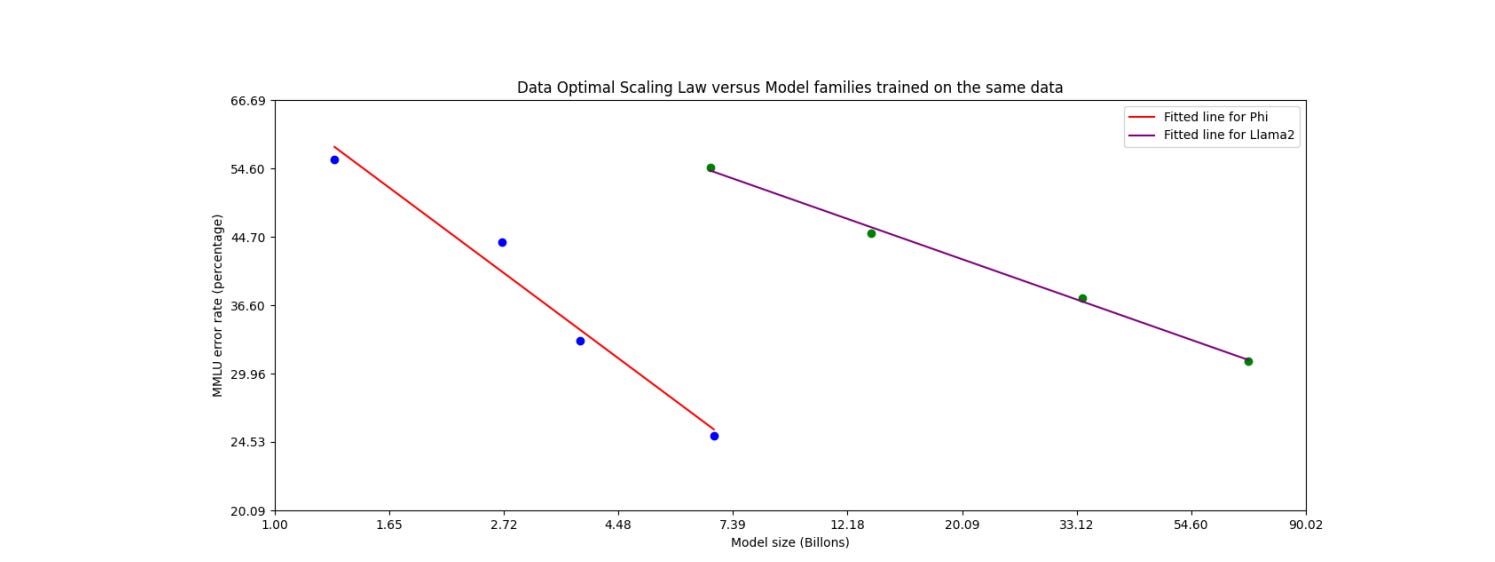
Higher quality data is a win/win because less data also means less compute. The efficiency of the whole training process improves. The chart below shows that
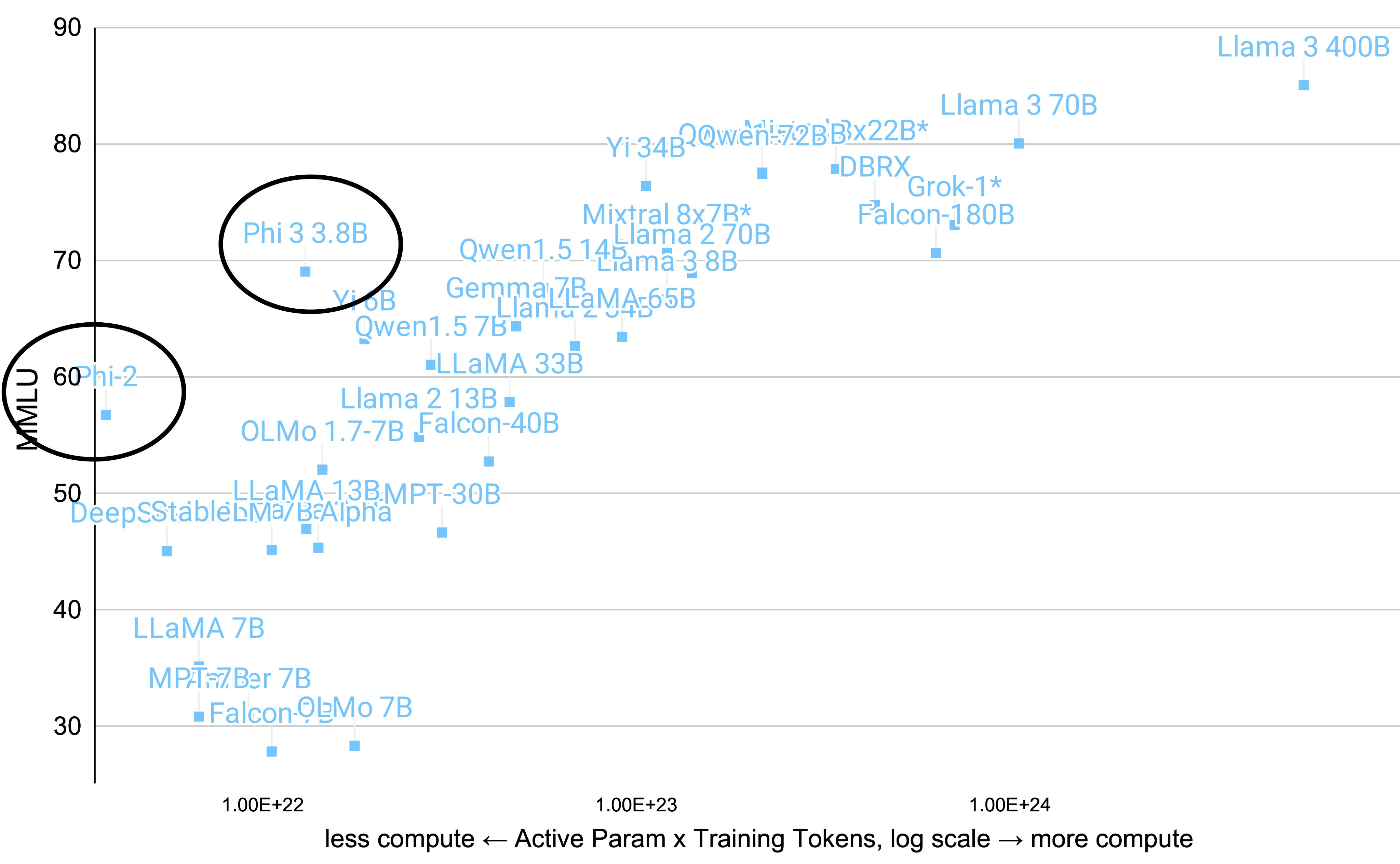
LLM Efficiency Through Better Algorithms
LLMs aren’t just improving due to scaling compute, data and parameters. LLM training is improving algorithmically. The paper “Algorithmic progress in language models” presents a comprehensive analysis of algorithmic progress in language models. They found that a rather significant improvement due to algorithmic innovations:
the level of compute needed to achieve a given level of performance has halved roughly every 8 months, with a 95% confidence interval of 5 to 14 months. This represents extremely rapid progress, outpacing algorithmic progress in many other fields of computing and the 2-year doubling time of Moore’s Law that characterizes improvements in computing hardware.

Just one example innovation popping up this week: Applying QDoRA on Llama 3.
Improved algorithms, more and better data, and more compute together can combine to produce more performance for a given size of LLM. This combined scaling trend delivered a billion-fold improvement in AI model performance in ten years.
The most fundamental constraint of all these factors is the need to scale data (both quantity and quality) sufficiently to keep feeding LLMs. Data is all you need.