
Gemini 1.5 Pro & Flash Revealed
Massive context multi-modal AI and the rise of digital companions


A Deep Dive on Gemini 1.5
The recent GPT-4o and Gemini 1.5 AI model updates raise natural questions of how these AI models were trained, what their real internals are, to better understand their capabilities as AI models.
We know precious little about OpenAI’s GPT-4o internals; we have no architecture revelations or training details. While Gemini 1.5 from Google is likewise a proprietary model with many details hidden, they did release a technical report, Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context.
There are many gems in this technical report that give us clues about Gemini 1.5 architecture, performance and more.
Gemini 1.5 Pro architecture: Gemini 1.5 Pro is a sparse mixture-of-expert (MoE) Transformer-based model that builds on Gemini 1.0. Gemini’s pre-training dataset includes image, audio, and video content. It was trained efficiently but managed to outperform Gemini 1.0 Ultra:
More strikingly, 1.5 Pro, despite using significantly less training compute, surpasses 1.0 Ultra, a state-of-the-art model, on text capabilities like math, science and reasoning, code, multilinguality and instruction following.
Gemini 1.5 Flash is a dense transformer decoder model with the same 2M+ context and multimodal capabilities as Gemini 1.5 Pro. It does parallel computation of attention and feedforward components and is online distilled from the much larger Gemini 1.5 Pro model.
Flash is for Speed
Gemini 1.5 Flash is built for speed, and they justify their claims with a study showing Gemini 1.5 Flash not only about 3x faster than Gemini 1.5 Pro, 4x faster than GPT-4 Turbo, but even significantly faster than Claude 3 Haiku, the zippiest Claude 3 model.

The report also mentions they are working on a Flash-8B model, and even faster and smaller version of Flash that also has multimodal capabilities and a 1 million context window. Flash-8B achieves approximately 80-90% of the performance exhibited by Flash on established benchmarks, with an MMLU score similar to Llama 3 8B.
Context & Multi-Modality
“This context length enables Gemini 1.5 Pro models to comfortably process almost five days of audio recordings (i.e., 107 hours), more than ten times the entirety of the 1440 page book (or 587,287 words) "War and Peace", the entire Flax (Heek et al., 2023) codebase (41,070 lines of code), or 10.5 hours of video at 1 frame-per-second.” - Gemini 1.5 Report
Google’s two biggest points of pride for Gemini 1.5 are that it’s fully multi-modal and it has a huge context. A fully multi-modal AI model can take inputs as images, video, audio or text and these inputs can be interleaved.
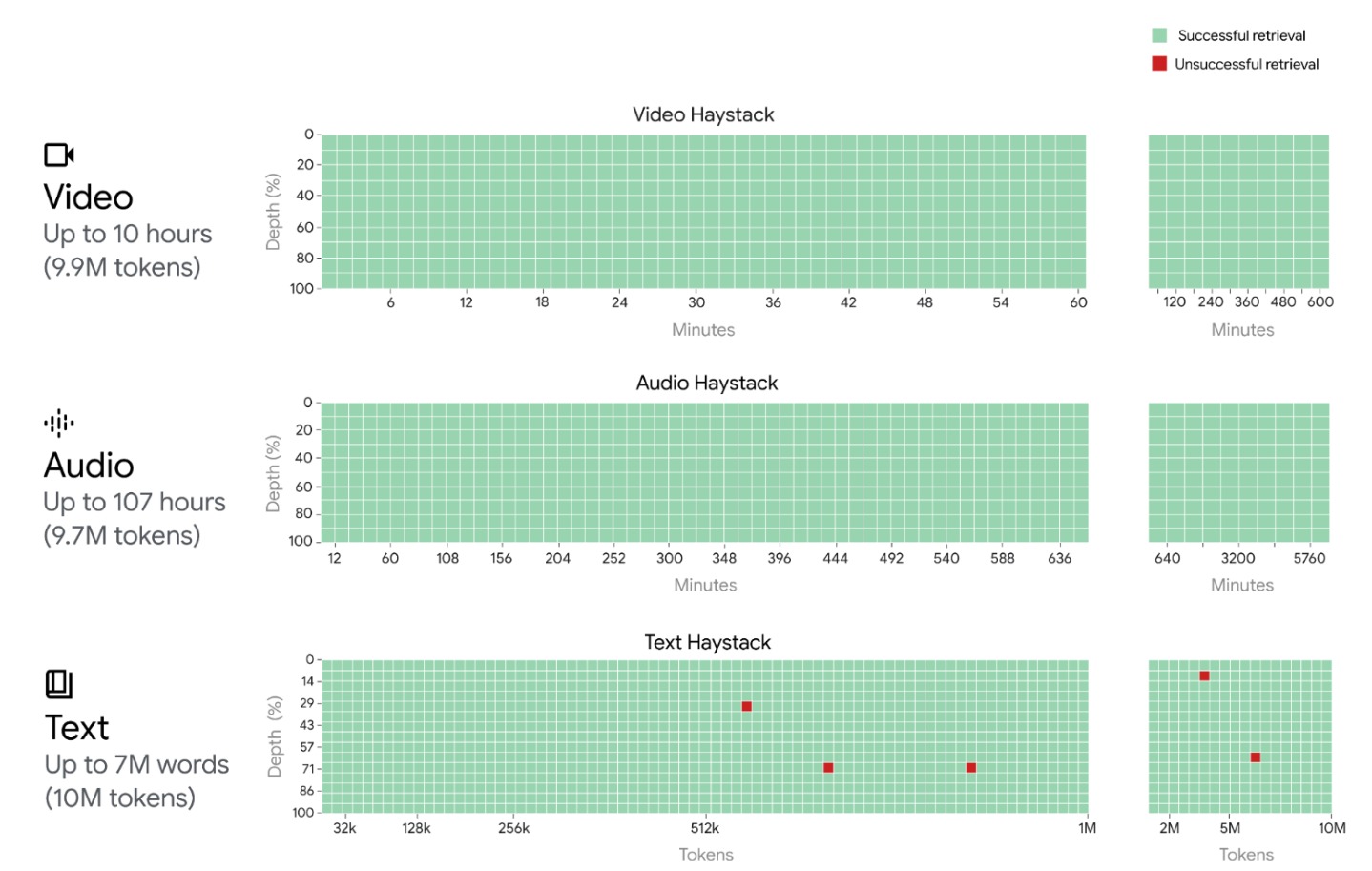
Gemini 1.5 Pro and Flash now come with a 1 million token context window, and Google is pre-viewing 2 million tokens of context available for Pro. They also assessed Gemini 1.5 Pro in experiments extending the context to 10 million tokens in experiments, finding that it can achieve excellent “needle-in-the-haystack” recall even there:
Scaling to millions of tokens, we find a continued improvement in predictive performance, near perfect recall (>99%) on synthetic retrieval tasks (Figure 1 and , and a host of surprising new capabilities like in-context learning from entire long documents and multimodal content.
With a large multi-modal context more challenging AI use-cases are possible, and large-scale in-context learning can displace uses of fine-tuning and RAG (retrieval-augmented generation). Some examples:
Medical diagnosis: A patient’s condition is described in a multi-modal set of data - video and images of the condition, plus medical notes, and perhaps audio of checkup. Medical diagnostic guidelines are put into the context.
Video editing: Extracting information from huge amounts of video can automate editing - extract scenes, screenplays, timestamps, desired snippets by using a semantic video search. This in turn could be turned into editing instruction or generative output. For example “Redo this scene dialog, but make it reflect the exact dialog that was in the source novel.”
Translation: Put a dictionary, grammar book, and language samples for a low-resource language into the context; use the model to translate to and from that language.

While RAG and fine-tuning are more efficient in repeated use than loading a huge context, Google also introduced context caching, which allows you to reuse a context with having to pay for those tokens again; reusing larger contexts became much more cost-efficient.
You can load technical documentation, a large codebase, or corporate guidelines into a large context and reuse that context whenever there is a question around that information. Datasets could be preloaded into contexts, ready to be queried in-context. In-context learning on massive contexts with context caching is the new fine-tuning.
From Context To Memory
Cached context is memory. Our memory is simply recall of something previously learned and stored, or a previous experience.
Several months ago, ChatGPT added memory to their system, so that ChatGPT can remember things you discuss to make future chats more helpful. You can control ChatGPT’s memory, telling it what it can remember or deleting memories you want it to forget.
You can implement such an AI chat system memory with RAG, and perhaps OpenAI is doing that under the hood. However, to really take advantage of such capabilities, you would want a longer context to maintain a significant amount of readily available memory.
This is where Gemini 1.5 shines. With its 1 million context window, you could load in your background, life experience, writings, interactions with others (emails), etc. and have an AI Assistant that knows you deeply and remembers every interaction with you. This highly personalized AI Assistant can be implemented simply by maintaining a cached context of your desired personalization.
Performance and Reasoning
The technical report shared extensive and in-depth evaluations of Gemini 1.5 Pro and Gemini 1.5 Flash, showing them both to be strong AI models on a broad set of benchmarks.
Gemini 1.5 Pro as of May is improved over Gemini 1.5 Pro from February, bumping up HumanEval to 84 from 71, and MATH from 58 to 67.

While Gemini 1.5 Pro is very impressive, the real surprise though is how good Gemini 1.5 Flash is. Despite being smaller, faster and cheaper than Gemini 1.5 Pro, Gemini 1.5 Flash beats Gemini 1.0 Ultra on many benchmarks - Google’s best model just 5 months ago.

On core benchmarks of math, science, reasoning, and coding (see below), Gemini 1.5 Pro is clearly the best AI model Google has produced, while 1.5 Flash is overall competitive with 1.0 Ultra.

Gemini 1.5 Pro and Flash both score very highly on Berkeley Function Calling benchmarks, making them suitable in AI agent systems or AI applications that use function-calling.
They performed a number of detailed evaluations of Gemini 1.5 performance on long context tasks, including: Translating a new language from one book; transcribing speech in a new language in context; evaluating long-document QA by querying details from the novel “Les Miserables”.
For long-context audio speech recognition, they showed that Gemini 1.5 can transcribe 15 minutes at a time and outperforms Whisper and other alternative speech recognition models, that required breaking the audio up into 30 second chunks, with a word error rate of 5.5% for Gemini 1.5 Pro (versus over 7% for Whisper and Gemini 1.0 Ultra).
They also tested Gemini 1.5 on In-Context Planning, which involves being given a specific problem with a limited number of examples, and producing a solution plan in one go, without checking each step to confirm if it’s correct. In other words, how much reasoning can it do in a single step, without falling back on iteration, ‘reflection’ or other techniques?
On in-context planning benchmarks, they show Gemini 1.5 Pro beating Gemini 1.5 Flash and GPT-4 Turbo.
Conclusion - Gemini 1.5 and the Generational Leap
we conclude that the Gemini 1.5 series present a generational leap in performance in comparison to the Gemini 1.0 series.
Gemini’s fully native multi-modal capabilities to seamlessly integrate text, images, video, and audio represent a significant leap forward. With Gemini 1.5 combining that with an immense context window of 1 million tokens (potentially 10 million in the future), it unlocks a vast array of new applications.
While long context windows don't entirely replace RAG for searching vast databases, they may displace RAG and fine-tuning over smaller datasets, especially when combined with context caching.
Gemini 1.5 Pro surpasses the performance of Gemini 1.0 Ultra, on various benchmarks. However, Gemini 1.5 Flash is more impressive, by achieving reasoning capabilities competitive with Gemini 1.0 Ultra, while being much faster and cheaper.
Why didn’t Google talk about a 1.5 Ultra? There may be hitting a ceiling in performance that they hit, but it may be they are pursuing a smaller model strategy because it is more cost-efficient on training and inference.
Slower token speed negatively impacts user experience, making larger models less desirable than faster, cheaper, smaller AI models. Furthermore, training smaller AI models like Flash, Flash 8B, and Gemma is cheaper and quicker; smaller AI models can evolve and improve more quickly.
Coda - From Prompts To Conversations To Digital Companions
GPT-4o and Project Astra are moving AI interactions from prompts to conversations. The prompt is still the “unit of knowledge work” and the underlying input to AI models, but the AI interface can build prompts beyond a bare user input. This turns the AI user experience into a more natural conversation.
The primary element to make that work is low-latency audio interface. To make AI conversations as close to human as possible, it needs to be what a natural conversation sounds like: An audio interaction with quick natural response, allowing interruptions.
A second element is emotional understanding and expression. We say a preview of those skills in an AI in the GPT-4o demo - picking up on cues, knowing who the speaker is in a multi-person conversation, detecting emotions, and expressing both empathy and emotions in human-like ways.
A third element is awareness. Project Astra’s demo, while less about the emotions and more about the visual and audio awareness, able to understand visual surroundings in real-time.
Now add in the fourth element of context and memory that we discussed earlier. The memory makes it remember things about you, and turn it into a highly personalized AI assistant.
Combine these four elements - low-latency audio interface, visual and audio awareness, emotional understanding and expression, and memory - and you have the making of a very capable digital companion.
While Gemini 1.5 Pro doesn’t exhibit all the features that OpenAI showed off with the “Her”-like GPT-4o demo, Gemini 1.5 has the needed capabilities, as a native multi-modal massive context model with high-level reasoning. Project Astra is built on Gemini.
Massive context-multimodal Gemini 1.5 Flash is cheap, fast, and reasons well, making it an excellent AI model for powering an AI digital companion.