
Google Releases PaLM 2 and Upgrades Bard
Bard is now upgraded to run on PaLM 2, challenging GPT-4


Yesterday, Google announced the launch of PaLM 2, its newest large language model (LLM), at its I/O developer conference. TechCrunch reports:
PaLM 2 will power Google’s updated Bard chat tool, the company’s competitor to OpenAI’s ChatGPT, and function as the foundation model for most of the new AI features the company is announcing today. PaLM 2 is now available to developers through Google’s PaLM API, Firebase and on Colab.”
Some additional key points and features of PaLM 2:
PaLM 2 features improved support for writing and debugging code in over 20 programming languages.
PaLM 2 was trained on a corpus that features over 100 languages, making it, in Google’s words, “excel at multilingual tasks.”
“What we found in our work is that it’s not really the sort of size of model — that the larger is not always better. … parameter count is not really a useful way of thinking about the capabilities of models and capabilities are really to be judged by people using the models …” - DeepMind VP Zoubin Ghahramani
“Google says the new model is better at common sense reasoning, mathematics and logic. … the company trained the model on a large amount of math and science texts, as well as mathematical expressions.”
PaLM 2 is not one model, but a suite of models that come in different sizes: Gecko, small enough to fit on your phone; Otter; Bison; and Unicorn. They also announced fine-tuned versions of PaLM 2: Sec PaLM, fine-tuned on security issues; Med-PaLM 2 for use in the medical domain, which managed to pass medical license exams; and a fine-tuned coding assistant based on the small PaLM 2.
A PaLM 2 Technical Report was released along with the announcement. Like OpenAI’s GPT-4 Technical Report, it lacks details on the internal architecture of the PaLM 2 model, but it does share benchmarks on PaLM 2’s performance as well as reporting on the “responsible AI” aspects of the AI model.
Google I/O Announcements
Before I get into PaLM 2 Technical Report further, here are some other AI-related announcements coming out of Google I/O:
Google is making Bard generally available to everyone, and they have added support for a number of new features. Since Bard now fully runs on PaLM 2, it is smarter on reasoning and math, and supports better code generation and debugging on over 20 programming languages. They added Korean and Japanese, and will open it up to 40 languages soon. They will add image input and visual output to Bard in coming months.
Google announced that “Tools are coming to Bard,” similar to chatGPT plug-ins. You can export Bard’s generated code into colab, and in the future you’ll be able take generated code into Replit as well, similar to OpenAI’s code interpreter plug-in.
PaLM2 has a PaLM API for developers, integrated with a number of third party tools including LangChain, chromaDB, Baseplate, Hubble and Weaviate, as well as Google developer tools including colab and Firebase.
The also announced the newly merged Google Deep Mind team are working on their next-generation multi-modal foundation AI model, Gemini. Gemini will be available at various sizes and capabilities.
Google rebrands AI tools for Docs and Gmail as Duet AI. These generative AI support tools for Google docs, sheets, forms and gmail, but they are still in development.
Google Search gets AI-powered “snapshots”.
Google Photos enhanced with AI-powered Magic Editor. Plus, that are putting watermarking and metadata to identify generated images.
Android 14 is getting AI-powered customization options.
Diving into PaLM 2 Technical Report
Google’s PaLM 2 Technical Report, similar to the GPT-4 technical report, is a technical marketing report, not an academic paper or architectural document. It’s light on internal specifics and heavy on the ‘here’s what it can do’ benchmarks.
The abstract notes the PaLM 2 model architecture only as “a Transformer-based model trained using a mixture of objectives similar to UL2 (Tay et al., 2023).” In the model card they note: “We have small, medium, and large variants that use stacked layers based on the Transformer architecture, with varying parameters depending on model size.” No further details are given.
One page is devoted to describing the training dataset, but here too there are few specifics: “The PaLM 2 pre-training corpus is composed of a diverse set of sources: web documents, books, code, mathematics, and conversational data. The pre-training corpus is significantly larger than the corpus used to train PaLM.” The model is trained for now only on text; it’s a pure text-only LLM for now. They note a higher percentage of non-English data than previous large language models, touting its multilingual strength.
They also state that “PaLM 2 was trained to increase the context length of the model significantly beyond that of PaLM.” Thus, they are more flexible regarding context length, although they don’t give specific context length.
They confirmed DeepMind’s Chinchilla paper result on how the number of optimal parameter size scales with the compute budget, and they applied it to PaLM 2 scaling of parameters.

In addition, their abstract mentions “exhibiting faster and more efficient inference compared to PaLM,” which indicates a more parameter-efficient model suite. Yet we aren’t told the compute budget used nor the total corpus size, so while PaLM 2 large likely has fewer total parameters than 540B parameter PaLM, we can only speculate on this closed model.
In their conclusion, they tease further some implications on model parameter size and quality:
We also found that improving the architecture and a more varied model objective was important in performance gains. Finally, we find that the data mixture is a critical component of the final model. At this scale, even though translation pairs were a minor part of the mixture, it allowed the model to be on par with production translation services. We thus find that it is more beneficial to invest more compute in training a smaller model compared to modifying a model’s architecture to be more inference-efficient. In effect, we find that it is generally more efficient to train a smaller model with more tokens, for a fixed inference and training budget.
What Google has figured out is that foundation AI model inference costs are the biggest cost in running these large AI models. To be efficient on inference costs means to have the highest AI model quality for the least number of model parameters. Bigger isn’t always better.
PaLM 2 Benchmarks - how good is it?
The top three things Google has been touting in the PaLM 2 release from a technical perspective has been its performance on reasoning tasks, its coding ability and its multi-lingual abilities. Google shared benchmarks on these and other aspects of PaLM 2.
Their evaluations on reasoning and difficult related tasks shows that PaLM 2 greatly outperforms PaLM and achieves results that are competitive with GPT-4 and often state-of-the-art (SOTA).

On math-related reasoning and problem-solving tasks, PaLM2 again showed itself to be on par with GPT-4 and close or at SOTA on these tasks.
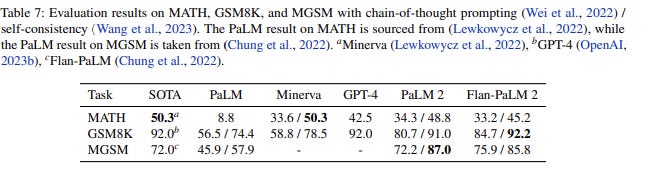
PaLM 2 achieves huge gains versus PaLM on BIG-Bench Hard, a set of difficult reasoning and multi-step chain-of-thought tasks where LLMs are behind humans.

Regarding code generation and support, they show that their own small model PaLM 2-S fine-tuned for coding outperforms PaLM-540B-Coder significantly. However, this is comparing only with its own prior work, not best-in-class alternatives like GPT-4. It still significantly under-performs GPT-4 on HumanEval. Still, its SOTA for non-OpenAI coding models and shows how a smaller model can do quite well.

On multi-language support, they stated “An explicit design choice of PaLM 2 is an improved translation capability,” and they showed results highlighting improvements in language translation and generation with PaLM 2 over PaLM. For example “PaLM 2-L achieves dramatic improvements over PaLM’s NLG ability that range from 59.4% on XSum to 100.8% on WikiLingua.”
There wasn’t much discussion of instruction fine-tuning, beyond their mention of fine-tuned models such as PaLM 2-S for coding, so it’s unclear how much or what was done to PaLM model in that realm.
The Responsible AI section covered their efforts and techniques for reducing toxicity, but it really didn’t say much.
Is this Google's answer to GPT-4? Yes, Google has upped their game and are now a fast-follower competitor. It will take more external evaluation to see how PaLM 2 stacks up against GPT-4, but just the fact that PaLM 2 vastly improves over PaLM, achieves SOTA on many tasks, and now powers Bard is enough to give Bard a second look.
Google also announced that their next generation AI model, called Gemini, is under development, so the AI race continues.
Postscript - Google still has work to do
They also had an announcement about search, so I’d thought I’d check on if Google search looked different. I was underwhelmed when I compared it to Bing.
This is Microsoft Bing - sharp, smart, informational at the top, news and links below:
Here’s Google, deciding to post videos up top and then below being merely a search engine. It frankly looks dated and didn’t show features the keynote described. Google still has work to do.
