
Google's Gemini Launched
Native-multi-modal Gemini comes in Nano, Pro and Ultra, claims SOTA crown


There were reports that the long-awaited Google Gemini model might be delayed until next year, but in a virtual briefing and a series of blog posts and videos by the Google DeepMind team, Google introduced Gemini 1.0 on December 5th.
Gemini comes in a suite of three AI model sizes and is natively multi-modal: Audio, text, images / photos, and videos, were all part of the AI model training data and can be used as inputs to Gemini models. The AI models in Gemini are:
Gemini Ultra: Gemini Ultra is the flagship AI model meant for highly complex tasks.
Gemini Pro: Gemini Pro is the mid-range version of the model, and will be the model powering Bard.
Gemini Nano: Gemini Nano is the smallest and most efficient model, designed to run on edge devices such as Google’s Pixel 8 Pro. Gemini Nano comes in two model sizes, Nano-1 (1.8B parameters) and Nano-2 (3.25B parameters), for low- and high-memory devices respectively.
“These are the first models of the Gemini era and the first realization of the vision we had when we formed Google DeepMind earlier this year.” - Google and Alphabet CEO Sundar Pichai
In a series of videos, Google Deep Mind touted some of the many capabilities of Gemini:
A demo of multimodal reasoning capabilities, responding with text and images and a custom AI-generated UI on the fly for a given prompt.
A demo of processing and understand raw audio to combine audio understanding and reasoning, translate.
A demo on unlocking insights in scientific literature, Gemini searched through 200,000 papers “over a lunch break” to summarize and glean insights from them.
A demo of Gemini’s coding ability now in AlphaCode2.
Showing multi-modal Gemini guessing movies from pictures, a kind of pictionary test.
Gemini’s Rollout and What’s Available Now
TechCrunch notes in “Google’s Gemini isn’t the generative AI model we expected” a few caveats. Not all of these models are available right now, but Google announced they will roll out in various forms over the coming weeks and months.
How can end users get a hold of Gemini? Go to Bard, which has gotten a Gemini update now. The English version of Bard in most countries is now powered by a fine-tuned version of Gemini Pro under the hood, as of today (Dec 6, 2023). Bard itself answered my question on this topic:

Google’s Vertex API service will get Gemini on December 13, meaning AI app developers could start building on it soon. But this is still Pro, not Ultra. TechCrunch notes:
Gemini Pro will also launch December 13 for enterprise customers using Vertex AI, Google’s fully managed machine learning platform, and then head to Google’s Generative AI Studio developer suite. (Some eagle-eyed users have already spotted Gemini model versions appearing in Vertex AI’s model garden.)
Those version mentioned were: gemini-pro, gemini-pro-vision, gemini-ultra, and gemini-ultra-vision.
So when will we actually see the Ultra version? It’s not ready yet. Google is “currently completing extensive trust and safety checks” and will release it early next year. They will launch Bard Advanced to give access to Gemini Ultra.
In an extended rollout, Gemini models will be embedded across the Google panoply of products, including the Search Generative Experience, Duet, YouTube, and on Google’s Pixel devices.
Gemini Ultra Beats GPT-4
Gemini’s announcement has interesting timing: A year and a week since ChatGPT took the world by storm. Gemini easily bests what ChatGPT can do and is a natively-multimodal, capping off the tremendous progress of AI in 2023.
Gemini Ultra is now Google’s best AI model, but is it the world’s best model? How does Gemini stack up against GPT-4 Vision?
With the caveat the they haven’t actually released Gemini Ultra to the world to validate and confirm these numbers, here’s what Google is claiming for benchmarks:
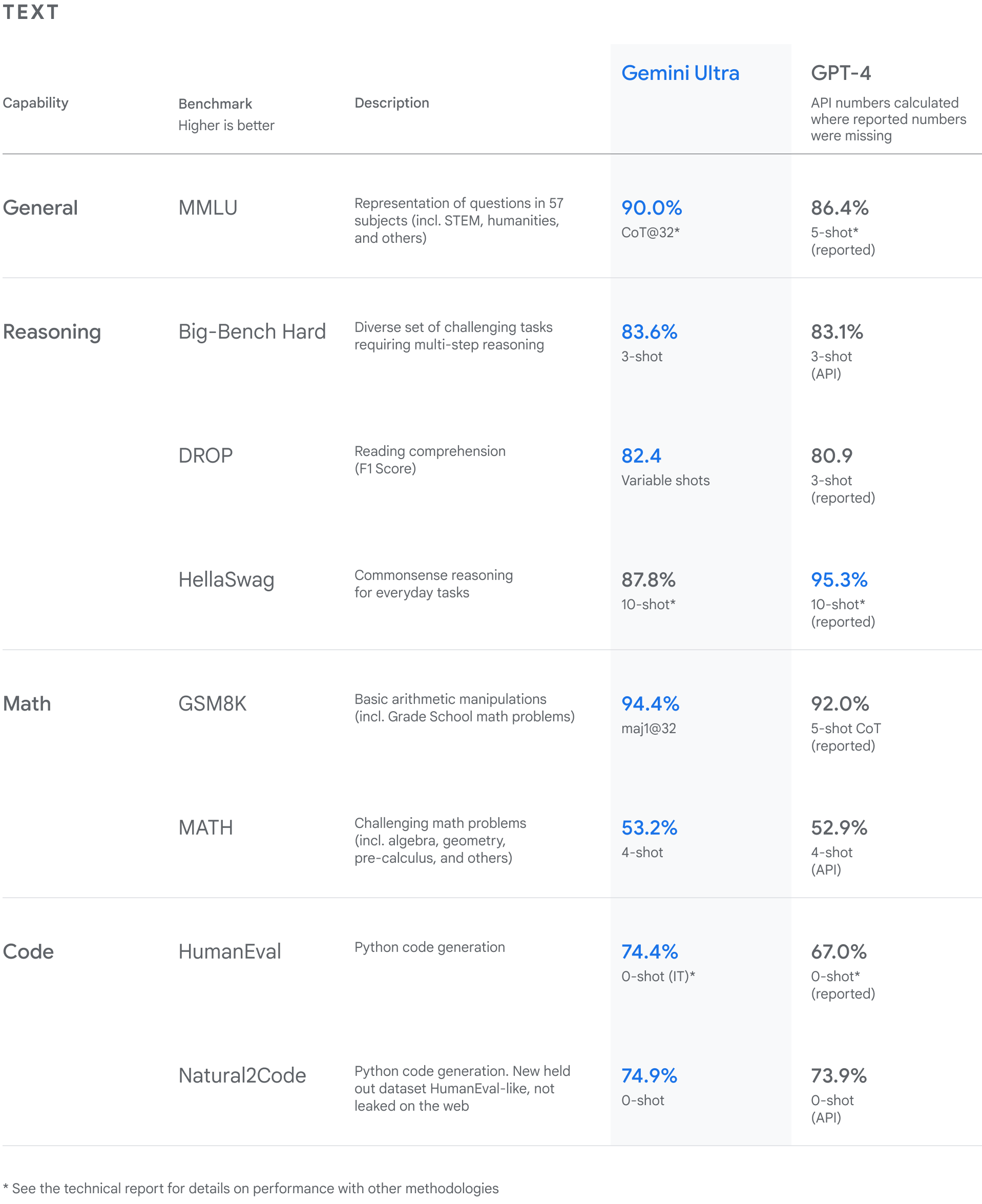
One key benchmark result that Google DeepMind touts for Gemini Ultra is a 90% score on MMLU (Massive Multitask Language Understanding), besting GPT-4V score of 86.4%. They declare: “Gemini is the first model to outperform human experts on MMLU.”
Demis Hassabis further noted “It’s [Gemini] so good at so many things. Each of the 50 different subject areas we tested on, it’s as good as the best human subjects.” That is remarkable progress for AI.
The GSM8K results and other reasoning tasks give a slight edge to Gemini over GPT-4V.
The above list of standard benchmarks doesn’t cover Gemini’s real strength as a ‘ground up’ multi-modal model, but multi-modal benchmarks do. Gemini Ultra achieves a new “state-of-the-art” score of 59.4% on a newer benchmark, MMMU, for multimodal reasoning, ahead of GPT-4 with Vision.
The chart below shows the benchmark results for the suite of Gemini models. Not only does Gemini Ultra beat GPT-4V across the board, but Gemini Pro is quite competitive in this arena as well, and since that is the version powering Bard, we can experience this capability now.

Another area of strength for Gemini is coding. As reported in The Verge and cited in the Gemini Technical Report, Google’s AlphaCode 2 is an important advance over their AlphaCode in coding prowess:
“The AlphaCode team built AlphaCode 2 (Leblond et al, 2023), a new Gemini-powered agent, that combines Gemini’s reasoning capabilities with search and tool-use to excel at solving competitive programming problems. AlphaCode 2 ranks within the top 15% of entrants on the Codeforces competitive programming platform, a large improvement over its state-of-the-art predecessor in the top 50%.
AlphaCode 2 got its own Technical Report, showing it used Gemini Pro as a starting point for futher fine-tuning. Mentioning AlphaCode2 as an agent begs a question of what other powerful AI Agents could be built with the power of Gemini Ultra under the hood.
Technology Review points out that “It outmatches GPT-4 in almost all ways—but only by a little,” And asks, “Was the buzz worth it?”
The answer is yes. With caveats that this is Google’s own validation and we’d need to check for contamination issues, Gemini Ultra indeed appears to be the new world’s best AI model, beating out GPT-4 Turbo for the title.
Even if this is by inches, Gemini performs SOTA across a broad range of tasks. We need competition not monopoly in AI models, and Gemini as a strong competitor ensures newer and better models will arrive in 2024.
Google Gemini Technical Report
Google Deep Mind released a technical report accompanying the announcement, called “Gemini: A Family of Highly Capable Multimodal Models.”
At its heart, Gemini is a transformer architecture AI model that can take in text, audio, video and images, and output interleaved images and text. They mention that Gemini drew inspiration from Flamingo, CoCa, and PaLI, “with the important distinction that the models are multi-modal from the beginning.”

They note that by ingesting audio signals, at 16kHz from Universal Speech Model (USM) features, they can capture audio nuances. For example, they demo assisting with pronouncing words in Chinese as well as natively translating French audio into an English summary.
They also note that “Video understanding is accomplished by encoding the video as a sequence of frames in the large context window. Video frames or images can be interleaved naturally with text or audio as part of the model input.”
The power of multi-modality weaves through a number of their powerful use cases they demonstrated. For example, the first example they show is checking and correcting a student physics problem answer by natively reading from an image.

One can imagine how combining reading of handwriting, listening to audio, understanding images and reasoning on them all could make for boundless applications.
How Gemini was trained
Gemini is unfortunately a closed proprietary model, so the Technical Report didn’t release critical information like parameter size and dataset content. But they did give some clues and hints.
Infrastructure: Gemini Ultra was trained on a large fleet of TPUv4 accelerators, deployed in “SuperPods” of 4096 chips each, across multiple datacenters. This was a scale up from PaLM 2. Gemini Pro, smaller than Ultra, completed pretraining in a matter of weeks, leveraging a fraction of the Ultra’s resources.
Dataset: The Gemini dataset was multimodal and multilingual, including web, books, code, images, videos and audio. They followed Chinchilla scaling for the large models, and Nano utilized distillation techniques and were trained on more tokens per parameter.
This was built on the shoulders of giants. The list of contributors is huge, the list of prior work this was built on longer. The biggest disappointment with these releases by Google and OpenAI is the lack of openness in the technical features of how they were made. Yet many will be interested enough to figure this out that open source versions will follow.
Regarding AI safety, they declared that “Gemini has the most comprehensive safety evaluations of any Google AI model to date, including for bias and toxicity.” As with other technical details, the AI Safety section is a bit vague, and since the red teaming of Gemini Ultra is still ongoing, perhaps more to say about that later.
Summary
Google’s Gemini 1.0 is the most important AI model release since GPT-4 in March, but we’ll have to wait to try out Gemini Ultra. For now, try Gemini Pro via bard.google.com.
The best demo reel was a video of a user interacting with Gemini, showing its audio-visual understanding through a video. I don’t like to anthropomorphize AI, but this video convinced me that Yan LeCun’s “cat or dog level AI” is wrong analogy, and perhaps a child-level AI analogy fits.
This AI is like a child-level AI. Gemini, like it’s counterpart GPT-4V is like a child prodigy, short on social skills and common sense, but amazingly talented and knowledgeable at the same time.
The release of Gemini 1.0 is the end of the beginning of the AI era. CEO Sundar Pichai sees Gemini 1.0 as the first of more yet to come. I’m looking forward to what awaits.
“AI is a profound platform shift, bigger than web or mobile. … I believe the transition we are seeing right now with AI will be the most profound in our lifetimes, far bigger than the shift to mobile or to the web before it. AI has the potential to create opportunities — from the everyday to the extraordinary — for people everywhere. It will bring new waves of innovation and economic progress and drive knowledge, learning, creativity and productivity on a scale we haven’t seen before.” - Sundar Pichai
Postscript. CoPilot makes the best (or second best) AI Free
I am a current ChatGPT+ subscriber. It’s well worth it, if you want the best(*) AI model at your fingertips. But Microsoft has made access to GPT-4 Turbo free via their Copilot interface. Formerly Bing chat, you can now access it at copilot.microsoft.com, to get a free interface to GPT-4 with vision, with Dalle-3 image generation thrown in.
(*) GPT-4 Turbo is still the best available free AI model until Gemini Ultra is made available, e.g., on Bard. Or maybe OpenAI will release another update to stay ahead?