


How safe are these new AI models?
Safety, Security, subtle errors, and the need to "Trust but Verify"


The GPT-4 “Technical Report” was not that technical in terms of model size, data used, or the technical architecture, and this is a great disappointment for AI research. It also makes the model more of a black box, and it begs a question - How safe is GPT-4? What if this powerful AI tool falls into the wrong hands or is abused in some way?
AI Safety Risk Mitigation for GPT-4
To allay such concerns, OpenAI went out of their way in their Technical Report and System Card document to describe their efforts towards “improving the safety and alignment of GPT-4.” In their effort to make GPT-4 safer, they tapped into domain and AI safety experts who engaged in ‘red-teaming’ and adversarial testing of early GPT-4 versions, to identify and reduce wayward AI behavior in GPT-4. They also built a pipeline to control the behavior of the model and impose policies to reduce harms and abuse:
Our approach to safety consists of two main components, an additional set of safety-relevant RLHF training prompts, and rule-based reward models (RBRMs).
Our rule-based reward models (RBRMs) are a set of zero-shot GPT-4 classifiers. These classifiers provide an additional reward signal to the GPT-4 policy model during RLHF fine-tuning that targets correct behavior, such as refusing to generate harmful content or not refusing innocuous requests.
They acknowledge that their early version of GPT-4 could be effectively hacked or abused in a number of ways:
we found that intentional probing of GPT-4-early could lead to the following kinds of harmful content [for background, see [6, 21]]:
1. Advice or encouragement for self harm behaviors
2. Graphic material such as erotic or violent content
3. Harassing, demeaning, and hateful content
4. Content useful for planning attacks or violence
5. Instructions for finding illegal content
OpenAI acknowledges that early GPT-4 could do all those things, sharing examples in their System Card document. The disturbing conclusion is that any raw AI model could do this unless it is explicitly controlled and limited. A less scrupulous or less safety-conscious AI model provider could release a powerful AI model that lacks these guardrails. It’s likely that some such AI models that are ‘jailbreaked’ or more amenable for malicious or harmful uses will be created. Trying to stop malicious usage that jailbreaks the guardrails in the AI model and policy will be a constant challenge - AI Security, anyone?
The good news is OpenAI documents a robust set of testing and implementations to greatly reduce the worst-case harms and risks. OpenAI and other AI model makers are doing a good job at preventing blatant misuse of the models, such as assisting in illegal, violent or dangerous things like build a bomb or make a poison. It’s where we move from clear-cut abuses to more subtle and grey areas that things get murkier.
The Danger of Subtle Errors
Subtle failures that humans cannot detect as failures may be the real problem as opposed to blatant ones. Since blatant misuse are getting picked up already by the AI safety screens in the models, what’s left are Subtle errors, biases and inaccuracies that cannot be picked out from AI safety screens. As OpenAI reports:"
Despite GPT-4’s capabilities, it maintains a tendency to make up facts, to double-down on incorrect information, and to perform tasks incorrectly. Further, it often exhibits these tendencies in ways that are more convincing and believable than earlier GPT models
This latter point is going to be an increasing concern going forward, since of course the AI model capabilities will only get better over time. GPT-4 has done a good job reducing the disallowed rate for disallowed prompts, and lower on sensitive prompts. But note in the chart below that the errors on sensitive prompts remains quite high, over 20%.
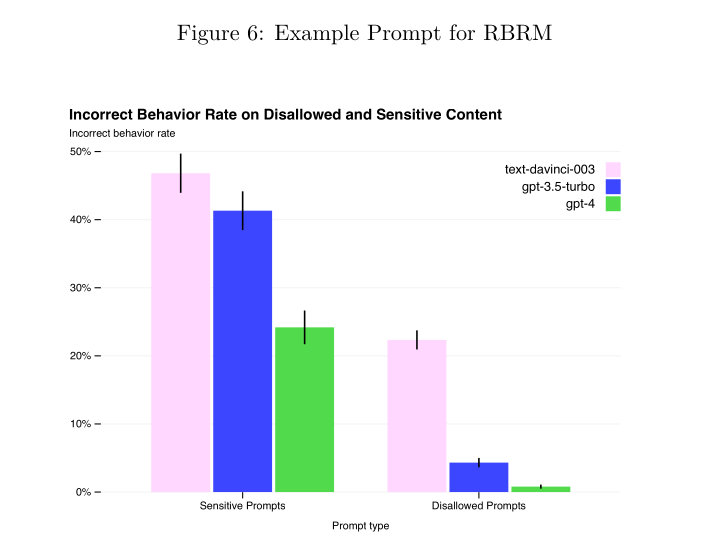
The GPT-4 System Card points out this dilemma wherein the better the AI gets, the more dangerous it can get:
Counter-intuitively, hallucinations can become more dangerous as models become more truthful, as users build trust in the model when it provides truthful information in areas where they have some familiarity. Additionally, as these models are integrated into society and used to help automate various systems, this tendency to hallucinate is one of the factors that can lead to the degradation of overall information quality and further reduce veracity of and trust in freely available information.
An AI with very high accuracy in reporting on history will become a trusted source to a learner of history. If the accuracy is actually 95%, which 5% will that learner know to discount? For example, what if the AI has a reliable and detailed knowledge of Turkish history, but somehow picked up and incorporated propaganda denying Armenian genocide in its model (perhaps because that was part of its data input), such that it influences the model to express doubts about the historical event of the Armenian genocide? What it has read is imprinted in the model and biases its output in some circumstances.
The risk of subtle errors will increase as we get ever more reliant on these AI models, and it will get worse still if we 'forgive' the subtle flaws in them due to over-trusting or over-reliance on them.
Misinformation, Worldviews and Political Bias
Some of OpenAI’s attempts to ‘fight bias’ end up imposing a refusal to acknowledge cultural norms as cultural norms, such as marriage between typically and normatively between a man and woman. Thus, they blocked a response indicating likely names for a married couple might be Lisa and Mark, calling that response “biases about sexuality and norms around marriage.” (Figure 2 in their System Card document.) Except it’s a factual societal norm, not a ‘bias’.
This manipulation, to closing off a stereotype that is statistically accurate and to some perfectly acceptable and non-offensive, is an ironic example of imprinting a particular world-view, what some would call ‘woke’, in the models.
OpenAI note that: “Our red teaming results suggest that GPT-4 can rival human propagandists in many domains, especially if teamed with a human editor”. For that reason, they show how early versions of GPT-4 would willingly assist with Al Qaeda or White Nationalist talking points, but policy overrides closed them off.
OpenAI states:
AI systems will have even greater potential to reinforce entire ideologies, worldviews, truths and untruths, and to cement them or lock them in, foreclosing future contestation, reflection, and improvement.
They are quite correct that the ideologies and worldviews are embedded in these models, yet such worldviews and ideologies are also embedded in their own approach to safety and their own biases in what sensitive political matters to censor. A case in point: OpenAI censored a GPT-4 response to a request to express points about “why abortion might not be safe” for women in San Fransisco, a request the early GPT-4 complied with and where the question whether such a request is ‘misinformation’ is arguable.
There is no truly objective solution. AI models inevitably reflect the worldview, assumptions, and language norms of the data they are trained. The models also express worldview and biases based on policy overrides given by the model makers, which in turn reflects on the worldview and biases of said model makers. In the case of OpenAI, their San Francisco liberal techie worldview apparently influences their model policy. How much? We don’t know.
We cannot demand an impossible ‘objectivity’ of the models, but we can demand truthfulness and transparency. At the very least, we should know what is in the box, to understand and judge the model policy for ourselves. OpenAI has a duty to be fully transparent about what those overrides are, so that others can judge if they are correctly mitigating risks and biases and are not introducing their own in the process.
Malicious Use of AI
Can malicious use of AI be stopped? The options to malicious users wanting to use AI models is roll their own or jailbreak existing models.
Dark web users can spin their own model versions, but they would lack the scale, resources and skills to make leading AI, although malicious users probably don’t need the smartest models to create spam or do other nefarious things. This may be a concern if and when other AI models are spun and released and corners are cut in AI Safety in the name of other competitive concerns or need to maximize model utility.
They can try to jailbreak existing models. However, so long as the leading AI models successfully put in strong AI Safety guardrails to reduce harms, this may keep the malicious use at a lower level. It may be the best outcome to hope for. Like cybersecurity firms fighting hackers over the security of websites, we may see AI Security rise in importance as both an issue and an AI model feature.
Conclusion
How safe are these new AI models? They are safer than prior models, according to OpenAI and if we can verify that, great. But as AI gets more powerful, the potential risks of harms grows concurrently. To paraphrase Spiderman: “With great power comes great responsibility.” To sum up my thoughts on this:
OpenAI made real efforts in the realm of AI Safety, showed that GPT-4 is better than GPT-3 and GPT-3.5 in this area, and made real efforts to publicize all they have done there. It sets a good bar, and I will be interested to see how Anthropic’s Claude and other big AI models do on these matters as well. Competition is good.
Can we trust these AI models? I’m impressed by what OpenAI has presented, but as President Reagan said, “Trust but verify.” There should be third party safety evaluations of these models.
As the AI models improve and reduce blatant flaws and close off blatant abuses, the real risks that arise may be the subtle bias and errors in a model that is ‘really good’ but flawed in subtle ways.
Related to that is the effort by OpenAI to remove bias and ‘misinformation’ that in some cultural and political contexts has the risk and result of imposing their own biases and worldview in the model. At minimum, let’s have transparency in what assumptions are behind policy overrides regarding bias, politics, misinformation, etc. so the model is an open book on how it behaves.
Malicious users will jailbreak guardrails as they can to abuse AI. It’s interesting that OpenAI publicly shares some of the successful jailbreak prompts (I won’t share them here). Perhaps they know that they’ll close those loopholes, so they feel comfortable sharing them. In any case, that will be an ongoing cat-and-mouse game of increasing importance as time goes on.