
Independent AI Testing and Trust in AI
Red-Teaming AI is all we need. Plus thoughts on the AI Quadrant of Skeptics, Doomers, Optimists, and Min-Positivists and the Buterin Jihad.


Yesterday, I bricked my phone. Nay, I burnt my phone. In the process of doing a small burn of brush, and due to putting my phone in a front pocket where it fell out, I managed to drop my phone into a fire and not notice it was in there until it was burnt to a crisp.
As I recover, I am left pondering the question, "What can possibly go wrong?" and think about technology risk. My own faulty process (phone in pocket) weak verification system (failure to check it dropping), and dangerous environment (fire) led to a failure.
"What can possibly go wrong?" is a worthy question to ask of AI. It has been driving discussion on AI risks, and we’ve had plenty of debate, regulatory proposals and more.
I have prior noted that “AI Safety as a technical concern and engineering discipline.” We need to think systems. As James Clear says, “You don’t rise to your ambition, you fall to your systems.” A case in point is Boeing, currently taking heat due to gaps in their manufacturing systems leading to product safety lapses.
Independent Testing of AI Models
Earlier this week, Anthropic AI published “Third-party testing as a key ingredient of AI policy.” This document is helpful because it clearly lays some ideas for the systems and policies we need to assure AI safety.
They advocate for a “robust third-party testing regime” to “identify and prevent the potential risks of AI systems.” They argue that “more powerful systems in the future will demand deeper oversight” and that “robust third-party testing will complement sector-specific regulation.”
The case for testing AI is obvious. We test all manner of products to assure their safety, and we test software to assure it doesn’t have critical bugs. The more contentious issue is who tests, how should they test, and what should be tested? It gets further contentious to bring in questions of mandates or regulations forcing a particular testing regime.
While Anthropic is open-minded about how testing details are worked out, they see third-party testing as vital to both assure AI safety and to “give people and institutions more trust in AI systems.” A company’s internal tests will not be fully trusted; we need external validation. They cite examples of other industries with industry-wide safety standards and testing regimes: food, medicine, automobiles, and aerospace.
They see AI testing as a two-stage process: First a fast, automated internal testing process, perhaps with third-party oversights; then, secondary external tests that are “a well scoped, small set of tasks” that may include “specific, legally mandated tests.”
Ultimately, we expect that third-party testing will be accomplished by a diverse ecosystem of different organizations, similar to how product safety is achieved in other parts of the economy today. Because broadly commercialized, general purpose AI is a relatively new technology, we don’t think the structure of this ecosystem is clear today and it will become clearer through all the actors above running different testing experiments. We need to start working on this testing regime today, because it will take a long time to build. - Anthropic
They aren’t set in stone on one specific solution, “but designing this regime and figuring out exactly what standards AI systems should be assessed against is something we’ll need to iterate on in the coming years.” This seems appropriate. Testing should be done, but what and how to test will evolve with experience.
Minimum Viable Regulations?
I agree that common AI safety testing frameworks that private and public third parties could use will enhance AI safety and the trust in AI. The biggest challenge right now, though, is the unknown. Locking into an incorrect set of mandates or regulation scheme could be counterproductive.
Anthropic advocates for more Government funding for AI testing, and in particular to charge them with developing tests for assessing national security-relevant capabilities and risks of AI. They go further, and discuss possible regulations and mandates, specifically on testing.
We also note that regulations tend to be accretive - once passed, regulations are hard to remove. Therefore, we advocate for what we see as the ‘minimal viable policy’ for creating a good AI ecosystem, and we will be open to feedback.
My feedback is simple. The minimal viable policy for AI is what we have now: Freedom; we have the freedom to build and use AI. I am wary of any Government regulations and mandates that presume to know the risks to mitigate. There is a high likelihood regulations will do more harm than good by stifling US innovation. It may yield technology advantage to competitors like China to our detriment.
The AI Quadrant: Skeptics, Doomers, Optimists, and Min-Positivists
I understand where my pro-open AI models and anti-overregulation mindset comes from. As my recent bone-headed accident reminds me, I am a risk-taking person and sometimes that attitude is costly. I am not one to excessively doom on risks, AI or otherwise.
Risk takers often fail, but risk-averse people fail to gather the upside. However, each one of us having the agency to decide our own risk tolerance and our own fate is one thing. Determining the appropriate risk tolerance for all of humanity regarding the world’s most fundamental technology shift is another.
You can parse out the AI risk debate and the AI regulation debate it spawns by looking at the perspective of two questions:
How beneficial is AI? What are benefits of AI versus the risks of AI?
How powerful is AI? How good is it now and fast is it developing to AGI?
Answering these questions can help categorize perspectives on AI into four groups, thusly:

AI Doomers believe AI is becoming very powerful and will become an existential risk to humanity. A prominent AI doomer is Eliezer Yudkowsky, who says “The likely result of humanity facing down an opposed superhuman intelligence is a total loss.”
Techno-Optimists believe AI is becoming very powerful and AI is a force for great good that will benefit humanity. Techno-optimists like venture capitalist Marc Andreessen, author of the “Techno-optimist Manifesto,” believe “we are poised for an intelligence takeoff that will expand our capabilities to unimagined heights” and “Artificial Intelligence can save lives.”
AI Skeptics see the flaws and failures of AI, pointing out how AI hurts us when it fails. Professor and fellow substack author Gary Marcus takes an AI skeptic view when he highlights LLM-based science fails, GPT-4 having “some core problems” like hallucinations, its use in cybercrime and disinformation, and why AGI is not near.
AI Min Positivists see limits to AI technology, while also see AI’s impact as mostly beneficial. Yann LeCun, for example, has publicly expressed doubts about LLMs ability to do human-level reasoning, while also dismissing existential AI doom narratives as unrealistic.
There is a fifth perspective: Humility. Humility recognizes that we don’t fully know, that the future is uncertain, and we should let data lead us. With that perspective, we can be agnostic about predictions: AGI might be in a matter of months, or it might take decades. AI may have risks, but they are not inevitable or inherent.
Thought-leaders on the AI Power-Risk Quadrant
Similar to our above chart, there’s a quadrant chart shared by Vitalik Buterin here, that was originally done in 2022 by Rob Bensinger. (Likely based on earlier version done by Michael Trazzi.) These show where various AI thought leaders stand on the progress and perils of AI.
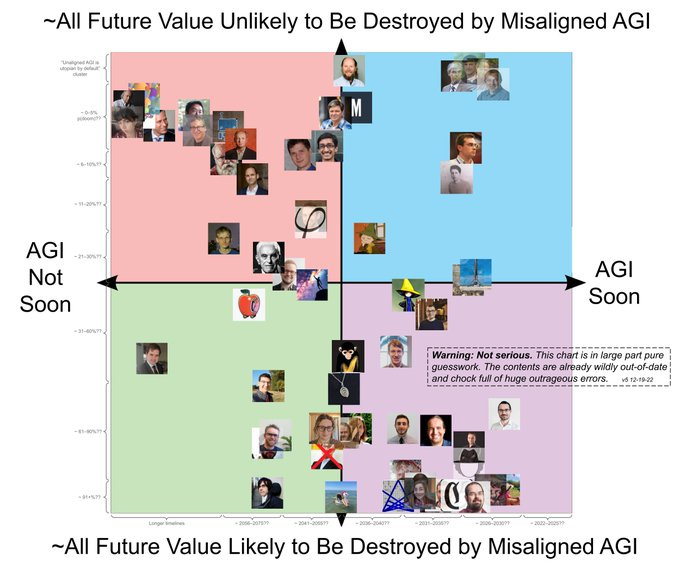
The prior version done by Michael Trazzi is shown below, with a smaller a different set of individuals. The placement of various AI thought-leaders is self-described as guesswork, based on public comments that could be open to interpretation, and may amount to libel to some. For example, Sam Altman, who has open spoken of risks of AI, and went to Congress to openly call for AI regulation, is not a true tech accelerationist.

Buterin’s AI Opinion - “Vigilance”
Unfriendly-AI risk continues to be probably the biggest thing that could seriously derail humanity's ascent to the stars over the next 1-2 centuries. Highly recommend more eyes on this problem. - Vitalik Buterin
Vitalik Buterin was placed as an AI doomer in the above chart by Trazzi. Buterin has a lengthy perspective entitled “My techno-optimism” shared on a blog and on X on technology progress and AI safety. His “nuanced” view is that technology progress is mostly good, but “not just magnitude but also direction matters” in the mix of technology progress:
The world over-indexes on some directions of tech development, and under-indexes on others. We need active human intention to choose the directions that we want, as the formula of "maximize profit" will not arrive at them automatically.
He points out the great benefit of technology generally, so he doesn’t want to slow technology progress. But he also sees AI as a new, special and different technology - “the new apex species on the planet” - that requires special vigilance:
AI is fundamentally different from other tech, and it is worth being uniquely careful.
Why dwell on the opinion of Buterin? He’s the inventor of Ethereum, and that crypto-billionaire put his money where his mouth is when it comes to AI safety. In 2021, he gave a massive $660 million donation (in crypto-coins) to the Future of Life Institute (FLI), a group dedicated towards “Steering transformative technology towards benefitting life.”
Buterin’s extraordinary gift recently became a media story about “the little-known AI group that got $660 million.”
FLI has used the money to fund other organizations who make it their business to fret over AI risks. FLI sponsored the famous “Pause Letter” calling for an AI model moratorium. FLI and their board members have also been advocating for AI regulations. Some examples:
Its president and co-founder Max Tegmark testified at a Senate forum on AI last fall, and was a major player at the United Kingdom’s November summit on AI safety. The United Nations appointed Jaan Tallinn, billionaire Skype co-founder and FLI board member, to serve on its new AI Advisory Body in October. FLI lobbyists helped ensure that the European Union’s AI Act included new rules on foundational AI models, and they continue to crisscross Capitol Hill as they work to convince Congress of AI’s cataclysmic potential.
It’s not a Butlerian Jihad (the fictional Dune series’ overthrow of thinking machines), it’s a Buterin Jihad. It’s a valid concern if AI regulation globally is heavily influenced due to one crypto-billionaire’s massive donation. What if he’s wrong?
“I worry a lot about how much influence these people [FLI] have with respect to lobbying government and regulators and people who really don’t understand the technologies very well,” - Melanie Mitchell, AI researcher at the Santa Fe Institute and skeptic of FLI’s claim that advanced AI is an existential threat.
Trust and The Politics of AI
Regardless of facts of AI and how it plays out, many perspectives on AI progress and risks are based on priors. Those who think “Capitalists are evil, but Government will protect us,” tend to favor AI regulations. Those who contrarily think, “Government is evil, but freedom will save us,” tend to favor open AI freedom and oppose regulations.
The AI regulatory debate ends up similar to other regulation debates: A question of freedom and trust in free markets versus safety and trust in Government. It boils down to the question: Who do you trust?
If you don’t trust anyone in power making AI decisions, then you have absorbed the wisdom that “power corrupts.” As Anton puts it on X:
AI risk is less likely to be a paperclip scenario. The real risk arises when there are only a single or handful of entities capable of utilizing and leveraging generally capable AI. Consolidated AI power is the real near term risk.
We take our chances with open AI models not because they are safe, but because ‘consolidated AI power’ is a greater risk. But why take chances at all? How else can we de-risk AI?
That takes us back to Anthropic’s promotion of third-party AI testing. I may be something of an AI optimist willing to take risks (sometimes to my detriment), but I want my AI tested because I want to know what it can and cannot do. I want to trust that my AI works as I expect.
We want an AI that we can trust.
AI needs to be trusted, and to be trusted, AI needs to be tested, independently. Let’s continue to test AI, try it out, and fix flaws. The Anthropic framework is a good starting point, but other companies, Government and academia can go much further.
Let’s also embrace the virtue of humility: Let’s not presume to know all the answers, but let’s keep asking the questions.
AI’s future is bright, but nothing is certain. When it comes to AI, test everything. Let the data, not priors, lead us to conclusions. Trust only what we have verified. Don’t get burned.