Llama 2: A New SOTA in open LLMs
Fine-Tuned Llama 2 chat model is released and it's state-of-the-art


Llama 2 has Arrived
If this was a movie sequel, it might be called “Llama 2: The rise of the open LLMs,” because we now have a new best-in-class open source LLM, just four months after the release of Llama 1 (originally called LLaMA). Meta AI research had teased doing an open source model recently, but it is genuinely surprising how quickly they have turned this around and released it.
Meta’s release announcement for Llama 2 included a detailed technical paper titled “Llama 2: Open Foundation and Fine-Tuned Chat Models.”
The LLMs they are releasing were pre-trained on around 2 trillion tokens and fine-tuned using RLHF. The LLMs come in 3 sizes: 7B, 13B, and 70B parameters each. They pre-trained a 34B parameter model as well, but it didn’t pass AI safety checks and so it wasn’t released along with the other three models. All models were trained on about 2 trillion tokens of data, with a context window size of 4k.
The fine-tuned versions of the LLMs, named Llama 2-Chat, were optimized for dialogue use cases. They claim robust performance:
Our models outperform open-source chat models on most benchmarks we tested, and based on our human evaluations for helpfulness and safety, may be a suitable substitute for closed-source models.
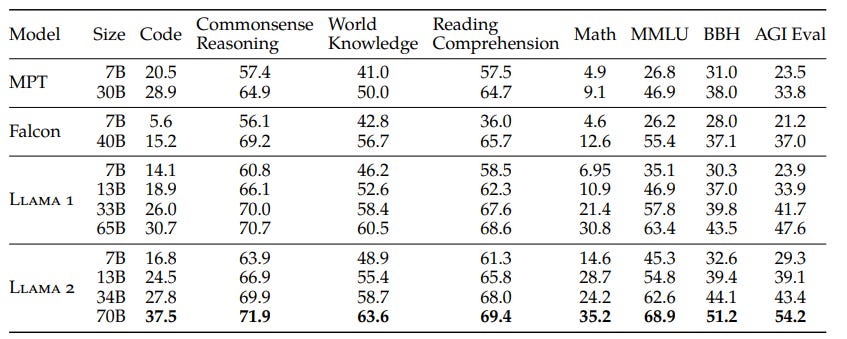
They back these claims up with fairly robust performance numbers on benchmarks. Compared to open-source models - MPT-30B, Falcon-40B, and original Llama1-65B - Llama-70B is a distinct improvement. Compared with the best overall models - GPT-3.5, GPT-4, PaLM-2. Llama2-70B is competitive with GPT-3.5 (ChatGPT), but behind the others on coding tasks (HumanEval).

An open-source LLM achieving the level of capability that OpenAI released to the world last November is important on a number of levels. First, it sets the pace of progress; it’s faster than expected. At this rate, we could expect an open-source GPT-4 equivalent by the end of this year.
Second, Llama2 is an open AI model, like the original Llama, and Meta decided to make their LLM commercially-available as an open model. This means it can be a platform for further open source innovation and fine-tuned specialized AI models, including commercially. Startups have the green light to use this to build AI applications.
How to Access it
There are already multiple ways to try it out. The Llama2-70B model is available via API on Replicate. Meta-llama2 on HuggingFace has hosted the various Llama2 models.
You can also download quantized weights of LLama2 models from Hugging face and run it on your computer locally using cpp, as noted by @AlphaSignalAI on Twitter.
How Llama 2 Was Made
The Llama 2 paper contained many details on their methods in the fine-tuning part of the training process, but little detail on pre-training particulars. Similar to OpenAI’s GPT-4 Technical Report, a lot of the focus of the Llama2 document is on AI Safety concerns.
Some of the pre-training details:
Two trillion token dataset: They up-sampled “the most factual sources” and they took steps to clean data for privacy. They did not use any Meta data in training, and excluded sites with a high volumes of personal information. They did show that most of the text data is in English. Nevertheless, they did not give details on what was specifically in their training corpus, and we’d have rely on Llama 1 paper for understanding details.
Pretraining: Llama 2 pre-training required 3.3M GPU hours on A100-80GB. They followed the settings and model architecture from Llama 1, with two changes: They increased the context length and also used group-query attention (GQA). they used Meta super-cluster.

Training optimality: It’s been noted that the pre-training loss curves did not flatten out; they could have (and perhaps will) continue to train it to improve the model quality. Chinchilla optimal (training compute optimality) is wrong goal, but rather maximizing quality for a given model size is the right goal for optimality. Will we keep going up in the amount of data per size of the model? The trend is that both data volume will go up and the data quality will improve relative to number of parameters in the model.
Fine-tuning Llama 2
Their work in fine-tuning Llama 2-Chat is explained more thoroughly in their paper “in order to enable the community to build on our work and contribute to the responsible development of LLMs.” This “responsible development” of AI is at risk of being closed off to the AI research community by proprietary models:
“These closed product LLMs are heavily fine-tuned to align with human preferences, which greatly enhances their usability and safety. This step can require significant costs in compute and human annotation, and is often not transparent or easily reproducible, limiting progress within the community to advance AI alignment research.”
Meta AI research opened up the RLHF (Reinforcement Learning with Human Feedback) process, and shared some of their approach.
The fine-tuning dataset was quite large and extensive. They developed two reward models to guide the RL: A Safety reward model, and a Helpfulness reward model. Combining these two helped them create a model geared towards safety without losing too much in the way of being helpful.

They used over 2.9 million human-annotated interactions, half of them developed by Meta and the rest from prior work of other AI model development teams, to feed the RLHF model. The companies Surge and ScaleAI are reportedly involved in the human annotations for RLHF.

This chart shows the progression of the models on both safety and usefulness, using GPT-4 and their own internal scoring system to evaluate the answers.

Benchmarks: How Good Is Llama 2?
As we showed earlier, Llama2-70B manages to be competitive on some benchmarks with GPT-3, and as shown below, performs well on human evaluations relative to ChatGPT.

When it comes to other benchmarks, it shows itself to be the SOTA open source model across the board, but reveals some weaknesses. MMLU score is 68.9, well above MPT and Falcon, but just shy of GPT-3.5. On coding-related tasks it seems weaker, with a score of 37.5 on a metric that combines HumanEval and MBPP. This might bode poorly for its reasoning ability, or might just be a reflection of data mix differences with other models.
Where Open Source AI is going
Meta took some risk with this release. As an open source AI model, its likely to be fine-tuned thousands of times, and despite best efforts for AI Safety, it’s possible a malicious user will use it to bad ends. Perhaps that is why their release included a defense of Meta’s open source AI model development, to pitch to the world that this is the right thing to do.
Is it ‘true’ open source? Not really, they didn’t open up their training source code nor their training dataset. On the other hand, they are fully transparent and open in terms of the internal weights and the fine-tuning process. It’s “Open License” and Open RAILs, so you an use it commercially and build a fine-tuned model on it as well, but strings are attached:
Commercial use allowed, which breaks the logjam for using Llama 1 derivatives, but not if you have hundreds of millions of active users. Sorry, SnapChat.
Legal language forbids distilling or re-using the model to another ‘competing LLM’. But who defines ‘competing LLM’? Do they disallow any use for other purposes?
What happens next? The community will quickly try it out and determine its true capabilities. We can soon expect many Llama 2 fine-tuned derivatives, with AI hobbyists and startups doubling down now that they can use it commercially. Combining it with tools and plug-ins, and building AI agents on it could follow.
I also hope Meta continues pre-training the larger models with a few trillion more tokens, to get to an improved Llama 3 soon. These are far from done.
There are so many important AI developments going on in 2023, but I would put this in the top 10. Innovation around open source is a big factor in innovation in the AI ecosystem, and this release opens up AI applications to use the new SOTA open source AI model Llama 2 as a platform.
Postscript
The safety harness on Llama 2-chat might be on a bit too tight, unless smiley faces in code are the next nuclear bomb. From Shannon Sands on twitter: