


Llama 4 Released – Meta Goes MoE
Meta releases two Llama 4 natively multi-modal mixture-of-experts AI models called Scout and Maverick, which score great on benchmarks but get mixed reactions in real-world use.


Introduction - Llama 4 Released
This weekend, Meta introduced their first Llama 4 AI models, Llama 4 Scout and Llama 4 Maverick, calling this release a new era of natively multimodal AI innovation.
Llama 4 Scout is a mixture-of-experts (MoE) model with 17B active parameters and 16 experts for 109B total parameters.
Llama 4 Maverick is likewise a mixture-of-experts (MoE) model with 17B active parameters but is fine-grained with 128 experts for a total of 400B parameters. It’s an incredibly intelligent AI model for such a small number of active parameters, scoring 1417 ELO on the Chat Arena and scoring best-in-class on multimodal benchmarks.
One game-changing feature is that these models have an industry-leading context window of 10M tokens.
These two models are the smaller siblings to the largest Llama 4 model, Llama 4 Behemoth, a massive AI model with 288B active parameters, 16 experts and 2T total parameters. Meta says this Llama 4 Behemoth is still training, but already “outperforms GPT-4.5, Claude Sonnet 3.7, and Gemini 2.0 Pro on several STEM benchmarks.”
They are not reasoning models, which gives them a disadvantage on some benchmarks compared to some other AI models, but it gives Meta the opportunity to share further releases based on these models that are.
Benchmarks – Maverick Shines
Llama 4 Scout is a respectable model that on benchmarks outperforms Gemma 3, Gemini 2.0 Flash-Lite and Mistral 3.1 across a broad range of widely accepted benchmarks, scoring a very respectable 57.2 on GPQA diamond, 74.3 on MMLU Pro, and 32.8 on LiveCodeBench.
Llama 4 Maverick is the model that really shines, given that it uses only 17B active parameters, yet has managed to outperform GPT-4o and Gemini 2.0 Flash across a broad range of widely accepted benchmarks. Particularly impressive is 69.8 on GPQA Diamond. It also manages to score an ELO of 1417 on LMArena, taking second place to only Gemini 2.5 Pro.
Meta claims that Maverick possesses:
best-in-class image grounding with the ability to align user prompts with relevant visual concepts and anchor model responses to regions in the image.

Vibe Checks – Not Great
The vibe checks are a mixed bag at best, with negative reactions to Llama 4 regarding coding and style, raising questions of whether Llama 4’s great benchmark results translate into real-world usefulness:
Llama 4 has gotten negative reviews on real-world coding tasks. One showed a failure in the ball in hexagon coding task, but others found a similar prompt worked.
Digital Spaceport reviewed Llama 4 Scout and found it to be solid on solving word problems and has a more matter-of-fact feel compared to Llama 3 but noted limitations in OCR and image recognition.
Fahd Mirza calls the release a flop because Llama 4 reportedly doesn’t stand out in real-world benchmarks, and their use of distillation from the Behemoth AI model to train their smaller AI models.
The model has been tuned to give emoji-laden answers to common-place queries, annoying one X user.
It’s odd that an AI model that responds with emoji-laden answers is doing so well on Chatbot Arena. Is the system prompt tuned for GenZ consumers? Unclear, but it begs a question of why the ‘vibe check’ isn’t matching the solid benchmarks for Llama 4.
Andriy Burkov notes another caveat:
The declared 10M context is virtual because no model was trained on prompts longer than 256k tokens. This means that if you send more than 256k tokens to it, you will get low-quality output most of the time.
His comment is a bit misleading, as Meta’s own NIH tests showed it held up. Reid Hoffman claims “the massive context window is a game-changer.” Still, real-world tests will tease out if the 10 million context works in real uses cases or not. RAG isn’t dead yet.

Technical Details of MoE
The use of mixture-of-experts enables much more efficient use of AI model parameters. Just as your visual, language and audio processing use distinct parts of your brain, it if more efficient to use different nodes in an AI deep learning network to process different modes or topics. As Meta puts it:
In MoE models, a single token activates only a fraction of the total parameters. MoE architectures are more compute efficient for training and inference and, given a fixed training FLOPs budget, delivers higher quality compared to a dense model.

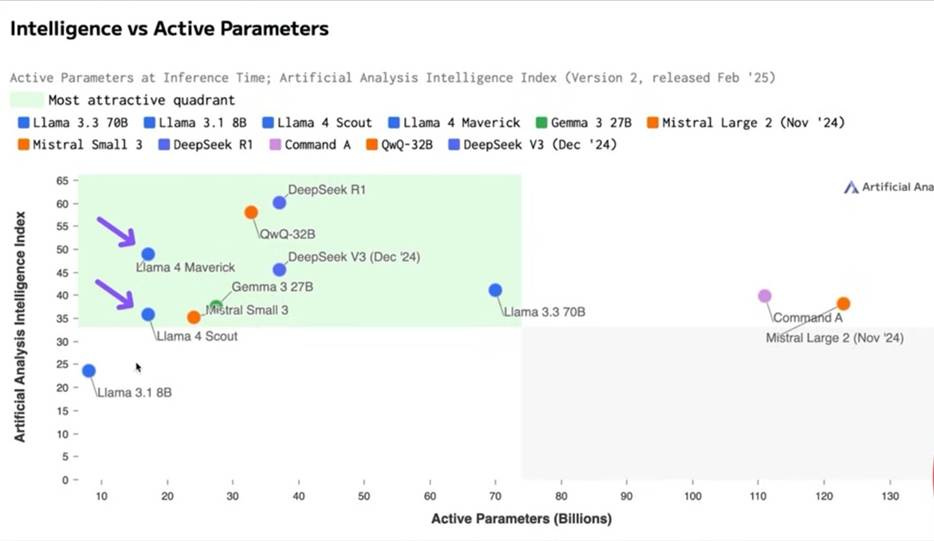
Llama 4 Maverick shows the great efficiency of MoE, with only 17B active parameters in a 400B model, which is similar to, but smaller than, DeepSeek V3. Llama 4 Maverick outperforms Llama 3.3 70B and Mistral Large 2 with fewer parameters.
Meta and Open Source
“Open Source AI Is the Path Forward” is what Mark Zuckerberg declared last July, and he has delivered on that promise with Meta Llama releases. It’s incredible to think we have had 4 iterations of Llama so far, and further incredible to consider how far they’ve come.
There are complaints that Meta isn’t true open source and that their models have idiosyncratic and not-fully-open licensing. While it’s a fair point, the reality is that millions, including myself, have gotten our hands on local AI models thanks to the Llama series. Open weights and a relaxed license have been good enough for us.
Because of this, I’m most disappointed I can’t run these new Llama 4 AI models locally. Mixture-of-experts may be the most efficient way to serve up an AI model through an API, but I can’t fit a 109B model, let alone a 400B model, on my RTX 4090.
Those with Mac Pro M4 Ultra have better luck. They can run the Llama 4 Scout model if they have at least 128GB of unified memory.
For others, you can find Llama 4 on many API platforms already as well as run it in the Meta.ai chatbot.
Conclusion – More to Come
Llama 4 is a great AI model release, but as our vibe checks showed, there are criticisms and concerns. As with GPT-4.5, the negative reaction is partly an ‘underwhelming’ reaction because Llama 4 Scout and Llama 4 Maverick, even with 10M context and multi-modality, are not reasoning models. They are behind the latest AI reasoning models.
However, this is just the start for the Llama 4 family of models. Hopefully, we will soon see AI reasoning models built on these Llama 4 releases, which would compete with DeepSeek R1 and o3-mini.
I would also like a smaller AI model for local use. Maybe Meta will develop a distilled 17B dense AI reasoning model.
There is no moat in AI models, not even for the open-source AI models. Meta will need to keep cooking their AI models to stay in the AI model race.
Followup: The stories around Meta's Llama 4 release are making things worse for Llama 4 and Meta. The discrepancy between great benchmarks and lousy real-world testing can happen if benchmarks are 'hacked' by putting benchmark test data into training data, 'training for the test', and that is being alleged. One Little Coder has a quick video explainer on the allegations here - https://www.youtube.com/watch?v=5B-DQ2OM3AY. Gary Marcus explains it further here: https://garymarcus.substack.com/p/deep-learning-deep-scandal
My bottom line is that since I cannot run LLama 4 locally, and since its not a great coding model nor a great reasoning AI model, I wont have use for these Llama 4 models. I don't need another chatbot model. Many others will pass on these as well. These allegations just add to the disappointment. I hope Meta recovers by releasing great followup AI models. They seem to have run into the same limits OpenAI did wrt big model training (like GPT4.5), and the solution is more and better post-training for reasoning, e.g. release a reasoning model like DeepSeek R1 based on Maverick.