
LLaMA, Alpaca and the Unreasonable Effectiveness of Fine-Tuning
AI gets better and cheaper, faster than ever


Alpaca is a recent and very quick follow-on to the LLaMA paper result that came out of the Facebook, er Meta, AI Research group just last month. They showed a remarkably quick and easy way to scale up the quality of a smaller model that indicates how we have a path to cheaply build high-quality small models via supervised fine-tuning on bigger high-quality models. This neat trick could upend everything in AI, giving us massively cheaper ways to build great models.
LLaMA - Efficient and Open
The LLaMA research contribution was to show that all open-source data and best-in-class approaches to training and fine-tuning could yield a very efficient and capable model with smaller parameter sizes. In particular:
Increase the input data and the model improves: “we find that the performance of a 7B [parameter] model continues to improve even after 1T tokens”
Use efficient training methods and increase the training effort: LLaMA-65B was trained on 2048 A100s that ran for 21 days and used 1 million GPU-hours. LLaMa-13B used 135,000 GPU hours. They showed continued increases in performance throughout training and as more tokens were processed. See Figure 2 from their paper.

Their bottom-line:
In particular, LLaMA-13B outperforms GPT-3 (175B) on most benchmarks, and LLaMA-65B is competitive with the best models, Chinchilla-70B and PaLM-540B.
It is quite remarkable that, even though scaling of models in terms of parameters gives you vast improvements, that LLaMA was able to out-perform GPT-3 with a model one tenth the size. It tells us that GPT-3 was seriously under-trained for its parameter size, confirming the conclusion from the Chinchilla model result: More data and more training yields better results even with relatively fewer parameters than used in prior LLM efforts.
Even though Open-AI didn’t release technical details, you can surmise from the AI research of others that they didn’t need more parameters, just more training and data, to improve on GPT-3. So GPT-4 used the same base parameters as GPT-3, probably continued the training from an already trained GPT-3, which is why the training data cutoff for GPT-4 is a curiously long time ago, Sept 2021; the main effort was made on additional training and fine-tuning, including RLHF (reinforcement learning with Human Feedback); GPT-4 was an evolution from GPT-3.5 which was an evolution from GPT-3. Seriously, OpenAI didn’t need to hold back on this information.
We now have four ‘best-in-class’ LLMs (Large Language Models) to compare: GPT-4, Chinchilla, PaLM / PaLM-e, and LLaMA. But we ALSO have the interesting result that, while not quite as good, you can still get
Enter Alpaca - “A Strong, Replicable Instruction-Following Model”
Right on the heels of the LLaMA paper came an announcement from Stanford HAI of an instruction-following model called Alpaca, an open-source equivalent of chatGPT released for the purposes of academic research. The stunning thing about Alpaca is how cheap and small it is, yet how effective it is. Their headline abstract says it all:
We introduce Alpaca 7B, a model fine-tuned from the LLaMA 7B model on 52K instruction-following demonstrations. On our preliminary evaluation of single-turn instruction following, Alpaca behaves qualitatively similarly to OpenAI’s text-davinci-003, while being surprisingly small and easy/cheap to reproduce (<600$).
How did they manage to do such a cheap and easy supervised fine-tuning? They got davinci-003 to train it!
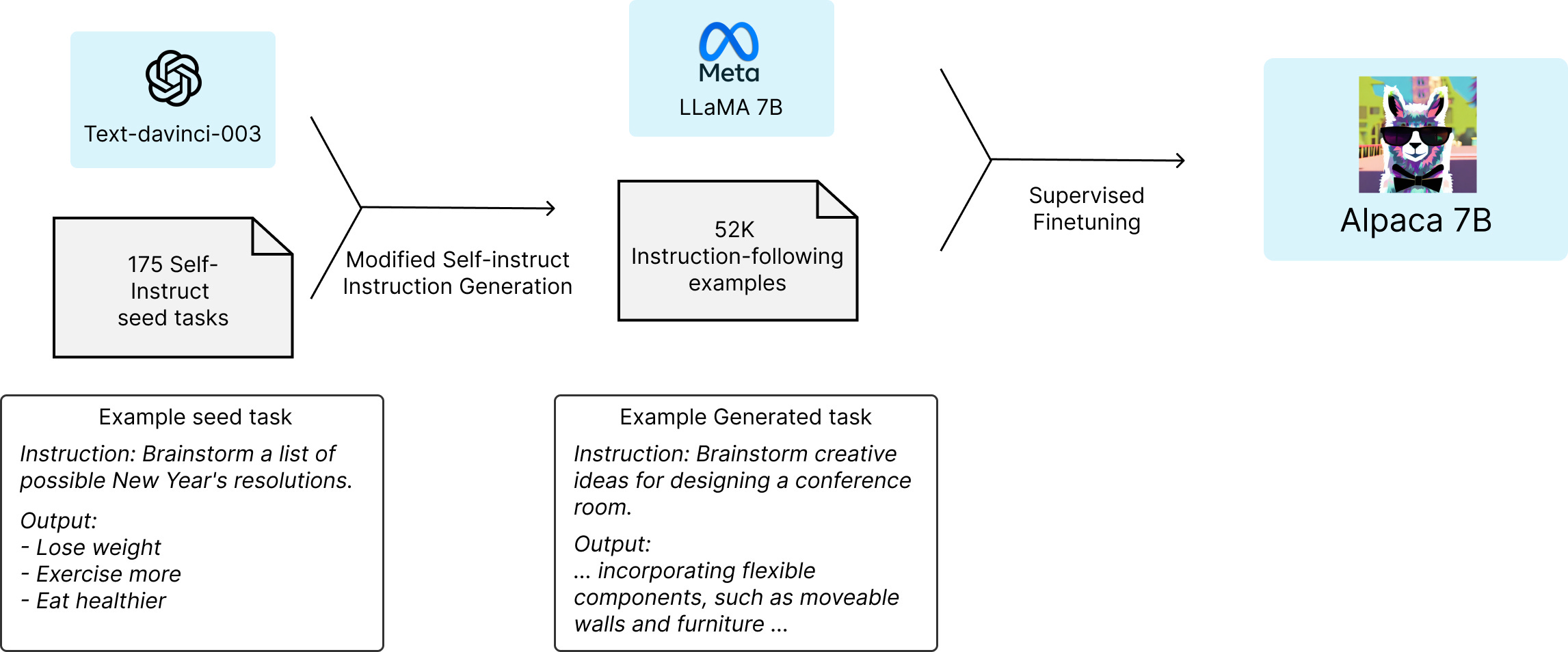
Now davinci-003 aka GPT-3 isn’t the best-in-class model anymore, but it still is a 175B parameter model, and a host of AI applications are in use today leveraging its power.
This result tells us that supervised fine-tuning is an effective short-cut to quickly improve model performance. What happens if and when this method of self-instruct instruction generation leverages not GPT-3 but the best-in-class Chinchilla, GPT-4, PaLM. LLaMA 65B? What’s the limit? Since Alpaca is open source and designed for research, I hope and expect researchers to test the limits of this.
Self-supervised fine-tuning of a smaller model from a larger model could be considered a form of model compression, where the weights and learning in the larger model are transferred to a smaller one. The end result yields a more efficient model, with lower cost of inference due to fewer parameters while maintaining result quality.
Expect to see a flood of repeated use of this technique to quickly advance AI model quality.
AI Pricing Considerations
It seems a lifetime ago when I announced the era of cheap AI was upon us. Oh wait, that was two days ago. This Alpaca result confirms that the plummeting cost of AI models isn’t just about the pricing decisions of OpenAI.
The cost of compute and the low marginal cost of LLM inference is the driving factor. The RLHF efforts of one model become the much cheaper inputs for SFT (Supervised Fine-Tuning) for the next model. AI itself lowers the cost of insights and drives a cycle of low-cost training.
Eliezer Yudkowsky points out on Twitter how groundbreaking this could be for the economics of Foundational models.

He says:
If you allow any sufficiently wide-ranging access to your AI model, even by paid API, you're giving away your business crown jewels to competitors that can then nearly-clone your model without all the hard work you did to build up your own fine-tuning dataset. …
I'm not sure I can convey how much this is a brand new idiom of AI as a technology.
That’s right. It’s the equivalent of the A student having other students copy his or her exam answers. It’s a short-cut, and if 52K prompts is only $600, what if you scale it up 1000x, with 52 million prompts, and fine-tune a model for $600K? Doable for a startup or even a research lab. How far will this go? As far as researchers and companies can take it.
While he mentions that model companies might try to ‘protect’ the IP of their LLM, it begs a question of how much they can protect when they themselves basically have scraped the entire internet and digested whole libraries of copyrighted information to produce the model in the first place. Even if they do create some proprietary way to lock their models down, that would likely make them less useful and amenable to use as an AI platform within a larger ecosystem. Catch-22.
Further, any model that tries to close themselves off from copying won’t prevent the process from being used, and it seems to be unreasonably effective and economical. There will be ways to sanitize. Full models won’t be that expensive to replicate: A LLaMA-65B equivalent model has the incremental compute cost of 1 million A100 GPU hours, plus the cost of massive 4 trillion word data collection. A huge effort, but far from a moonshot.
So let’s think step by step here. (Sorry, that prompt is a play on the paper on zero-shot reasoning that showed the unreasonable effectiveness of a particular prompt for LLMs.)
We will see a rapid advance of models and we will see a sort of AI-capability design convergence, as models copy each others capabilities to improve (either directly or indirectly).
In the AI space, we are seeing that fast-followers have effective and cheap strategies for staying close to leaders. (In business terms, leaders are leading innovators while fast-followers are those that emulate and keep up with the leader in short order.)
It may be hard for leaders to differentiate on quality from the ‘fast-followers’ and thus hard to extract pricing premium on a sustainable basis.
Thus, the pricing for best-in-class foundational model AI inference will go to marginal cost of computing the inference and API call. It will become a bit like the Intel / AMD CPU market: There is some premium for IP, but it remains a very competitive market pricing-wise.
The one consideration where this thinking may go wrong is that ecosystems can create a kind of lock-in effect, and the amount of data a leader generates through the use of their tool might give them a sustainable advantage if it helps them continually improve their model quality to keep ahead. In that scenario, there is a constant march of improvement by the leader(s) that makes it hard for others to keep up with.
Eliezer concludes:
“The AI companies that make profits will be ones that either have a competitive moat not based on the capabilities of their model, OR those which don't expose the underlying inputs and outputs of their model to customers, OR can successfully sue any competitor that engages in shoggoth mask cloning.”
I tend to agree.
The competitive moat that Microsoft / OpenAI ecosystem (or a Google / DeepMind / Anthropic ecosystem) can build is based on cheap compute, easy-to-use UI/UX, serving an effective, general, high-quality AI model (LLM) endpoint. The AI model endpoints for general use will be driven by the marginal cost of inference, with some premium for the unique and superior qualities of that model. The amount of that premium is to be determined, but these factors above suggest it will be capped.
So, the bottom-line on pricing: Foundation model AI inference served up as API endpoints will be cheap.
PS. AI Explained on YouTube breathlessly calls Alpaca “The Model that changes Everything” for the same reasons I think it’s important. He shares an ARK power-point slide on the lower cost of AI training and how that upends that.

It seems like data is the limit for training, as there's only so much training data out there on the internet, does this imply we can sail straight past this issue using AI-generated training data?