
Mistral AI drops Mixture of Expert AI Model
New Open AI Models - Mixtral 8x7B MOE, StripedHyena 7B based on new architecture


Mistral Goes MOE - Mixture of Experts
Mistral AI is an upstart AI company based in Paris, France, founded by Arthur Mensch, Guillaume Lample, and Timothée Lacroix, three AI researchers previously from Meta AI and Google DeepMind. Mistral AI got a lot of attention in June for raising $113 million pre-product with a bold plan challenge larger AI players with open-source LLMs.
Then a few months later in September, they dropped their first release: Mistral 7B. They won over the open source community with a 7 billion parameter LLM that was best-in-class for its size, open source, free to use locally, and quite capable as a base model for even better fine-tunes.
Now, Mistral AI has done it again. They dropped a torrent link to a 87GB file, containing the model weights to a model called “mixtral-8x7b-32kseqlen.” The model information in the torrent file confirms: The LLM is an 8x mixture-of-experts model of 7B each expert, with a 32K sequence length.

Since there is only a torrent file and it hasn’t been tried yet, the open source AI community on X has more questions than answers:
How was the model trained? A clue of how it was trained as a mixture-of-experts model comes from MistralAI’s Github repo that forked Megablocks, which is a library for training mixture-of-experts (MoE) LLMs.
“Entirely new model or is that 8 Mistral 7b squashed together and trained a bit more?” There has already been work on “Frankenstein models” that suggest a benefit in reducing training costs to start with 7B pretrained models. We’ll need to wait for Mistral AI to share details to confirm if they re-used trained 7B models as a start-point.
How good is it? Too soon to say. We’ll have to see people try it out and collect benchmarks to determine. One cold water comment was that an MOE model of 8x7B was likely as performant as a 14B dense model, based on prior work on MOE models.
Overall, mixture-of-experts AI models are more efficient and have a smaller memory footprint at inference, so we can run higher-performing AI models locally. This latter feature, and the possibility to get a GPT-4V level AI model to run on a local machine, is exciting the open source community.
Striped Hyena
Another important AI model for the open source community was released today (December 8) by Together: StripedHyena-7B, an open source model that moves beyond Transformers.
Together’s AI model release includes StripedHyena-Hessian-7B (SH 7B), a base model, & StripedHyena-Nous-7B (SH-N 7B), a chat model. They say “Both use a hybrid architecture based on our latest on scaling laws of efficient architectures,” and they specifically mention:
StripedHyena builds on the many lessons learned in the past year on designing efficient sequence modeling architectures: H3, Hyena, HyenaDNA, and Monarch Mixer.
Researchers at Together and HazyResearch at Stanford University, led by Professor Chris Ré (a co-founder of Together), have looked for ways to get around the quadratic complexity of the transformer architecture. Traditional concepts like convolutions and FFTs are able to model sequence data with sub-quadratic complexity.
Hyena, presented in “Hyena Hierarchy: Towards Larger Convolutional Language Models,” uses convolutions to replace the attention mechanism in transformer architecture. The Hyena architecture interleaves parametrized long convolutions with data-controlled gating. The result is a sub-quadratic drop-in replacement for attention.
The knock on these other sub-quadratic architectures has been that they may be more parameter efficient, but they are not as performant as transformers.
What if there were a model that were sub-quadratic along both sequence length and model dimension, and could match Transformers in quality?
Striped Attention used in StripedHyena is a mix of attention and the Hyena architecture:
StripedHyena is designed using our latest research on scaling laws of efficient architectures. In particular, StripedHyena is a hybrid of attention and gated convolutions arranged in Hyena operators. Via a compute-optimal scaling protocol, we identify several ways to improve.
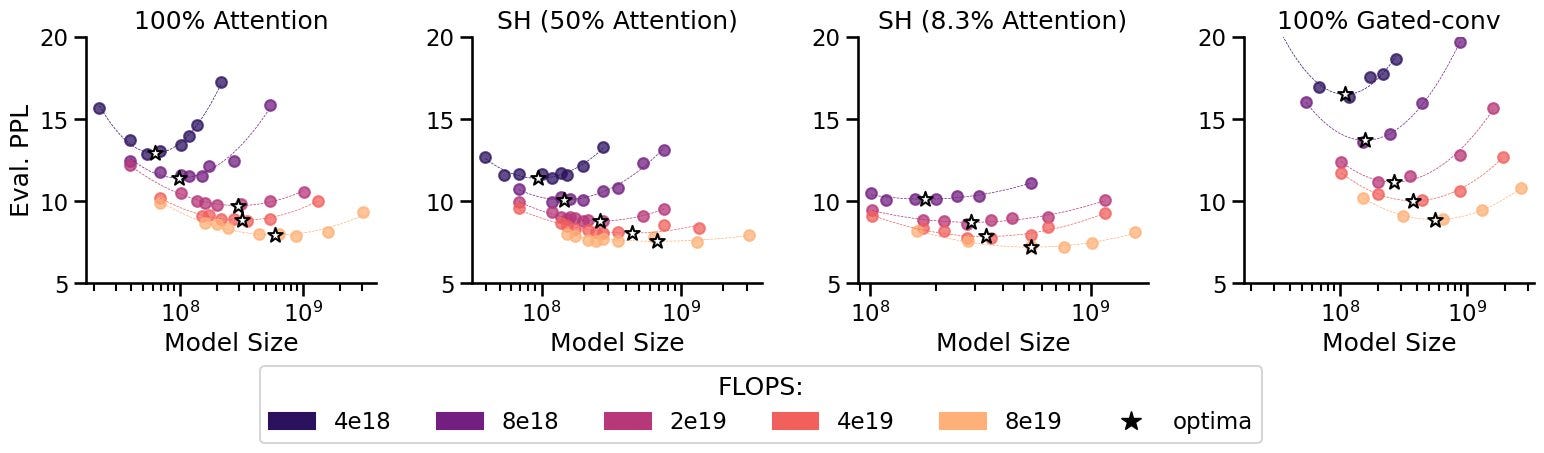
One of their conclusions from these studies and the building of StripedHyena could be a game-changer for LLM architectures:
we noticed a consistent trend: given a compute budget, architectures built out of mixtures of different key layers always outperform homogenous architectures.
Have they found the right formula? They are showing good results on benchmarks for the StripedHyena 7B AI model, comparable to best-in-class Mistral7B.
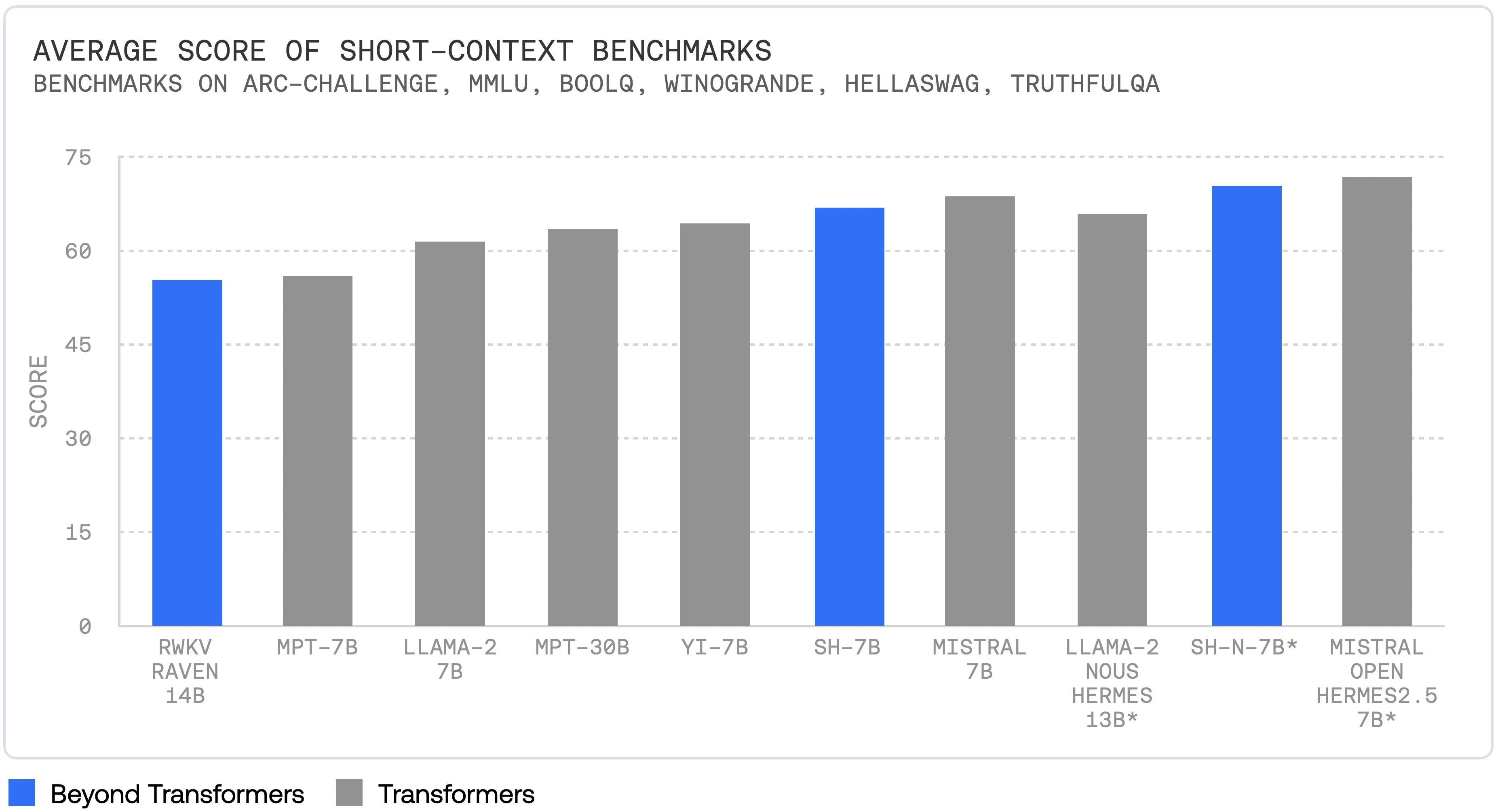
If these heterogeneous mixed architectures really can to do more with less, the unitary transformer architecture could be displaced. This model release may end up being the most important release of the week yet.
Is Gemini a Mixture of Experts?
Google Brain and their lead researchers such as Jeff Dean have been looking at sparse AI models for a number of years. Jeff Dean introduced Pathways in late 2021 in a blog post, and made an interesting comment:
Pathways could enable multimodal models that encompass vision, auditory, and language understanding simultaneously. So whether the model is processing the word “leopard,” the sound of someone saying “leopard,” or a video of a leopard running, the same response is activated internally: the concept of a leopard. The result is a model that’s more insightful and less prone to mistakes and biases.
That sounds exactly like what Google touted in Gemini 1.0 this week. He also said this:
Today's models are dense and inefficient. Pathways will make them sparse and efficient.
In 2022, a group of AI researchers from Google Brain presented on mixture-of-experts AI models with the paper “ST-MoE: Designing Stable and Transferable Sparse Expert Models.” Two of the co-authors of that paper, Liam Fedus and Barret Zoph, spoke on the topic of mixture-of-experts AI models on the “Towards Data Science” podcast. Interestingly, they both move on to OpenAI.
In the podcast interview they mention, “Sparsity adds another way to scale models, beyond compute and number of parameters.”
There are many reasons for Google to consider mixture-of-experts and sparse AI models:
The mixture-of-experts models are far more efficient at inference time, and a large provider of AI models like Google would want to optimize for inference
Multi-modality is a natural fit for sparse models and mixture of experts, as each modality could be analyzed via an expert focused on that modality and domain.
Google has been looking at these architectures for years.
Conclusion
The future of AI models are multi-modal, sparse, and diverse.
Multi-modal: We will move from LLMs (Large Language Models) to LMMs (Large Multi-Modal Models). Both SOTA AI models, GPT-4V and Gemini Ultra, are multi-modal, and audio, video, image and text input and output will be the baseline for future flagship AI models.
Sparse: With Mistral-8x7B, we have open-source mixture-of-experts AI models. We learned in June that GPT-4 was a mixture-of-experts model, and it is likely that Google Gemini is the same.
Diverse: Google released a suite of three AI models - Ultra, Pro and Nano. And today, we got Mistral AI’s 8x7B and Together’s StripedHyena 7B in 2 versions. StripedHyena is a new and potentially better architecture. We will continue to see variety and change in AI model architectures as they get more efficient.
End users may not care exactly what is under the hood, but the results do matter. More efficient AI models mean cheaper AI model endpoints and greater AI capabilities on our desktop, laptop and smartphone.