
Mixtral 8x7B and Mixture of Experts in LLMs
Mixtral 8x7B and the promise, pitfalls and enhancements on MoE for AI models


Mixtral of Experts 8x7B
Mistral AI on Monday shared a blog post announcing their 8x7B “Mixtral of Experts” model:
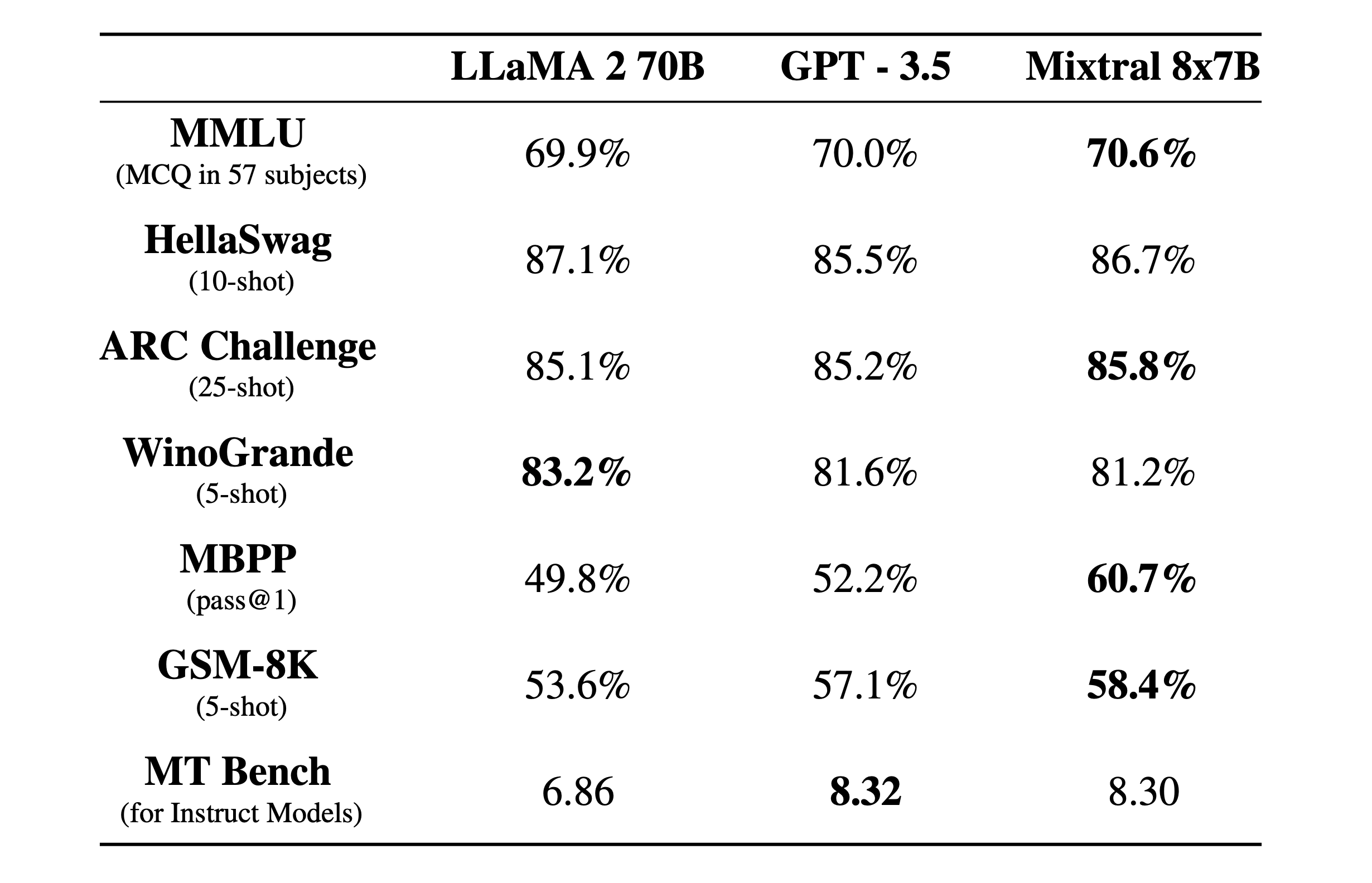
Today, the team is proud to release Mixtral 8x7B, a high-quality sparse mixture of experts model (SMoE) with open weights. Licensed under Apache 2.0. Mixtral outperforms Llama 2 70B on most benchmarks with 6x faster inference. It is the strongest open-weight model with a permissive license and the best model overall regarding cost/performance trade-offs. In particular, it matches or outperforms GPT3.5 on most standard benchmarks.
As with their first AI model, Mistral 7B, Mistral AI continues to impress with very high-quality AI Models for their size. Mixtral 8x7B LLM outperforms LLaMA 2 70B and edges out GPT-3.5 on many benchmarks:
Mistral AI achieved this with a high-quality sparse mixture of experts model (SMoE) that they describe thusly:
It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters. At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.
The routing of token through only parts of the network means that at inference time, only a fraction of the network needs to be activated and analyzed. “Concretely, Mixtral has 46.7B total parameters but only uses 12.9B parameters per token.” Fewer tokens to process at inference gives the model more efficiency and speed-up at inference time.
GPT-4 is reportedly a mixture of experts model of 16 experts, 2 chosen per token; Gemini models likely use MoE as well. Mistral’s 8x7B model confirms the value of mixture-of-experts. We’ll dive into how mixture of experts works and what this means for LLMs further.
Mixture of Experts - Background
Like many basic ideas in Artificial Intelligence, Mixture of Experts is far from a new idea. In 1994, Jordan and Jacobs authored the first significant paper applying the concept of mixture of experts to artificial intelligence, titled “Hierarchical Mixtures of Experts and the EM Algorithm.”
This paper outlined a method for combining the outputs of multiple models or "experts" under the guidance of a gating network that decides which expert to trust under different circumstances. It’s a way of decomposing a complex task into simpler tasks, or alternatively partitioning a broad array of tasks into subsets of tasks, each solved by a distinct ‘expert’, then combining that to build a full model. This is similar to ensemble models.
As deep learning came to the fore, researchers applied this concept to deep learning architectures. In 2014, the paper “Learning Factored Representations in a Deep Mixture of Experts,” co-authored by Ilya Sutskever, applied multiple sets of gating and experts within a deep neural network.
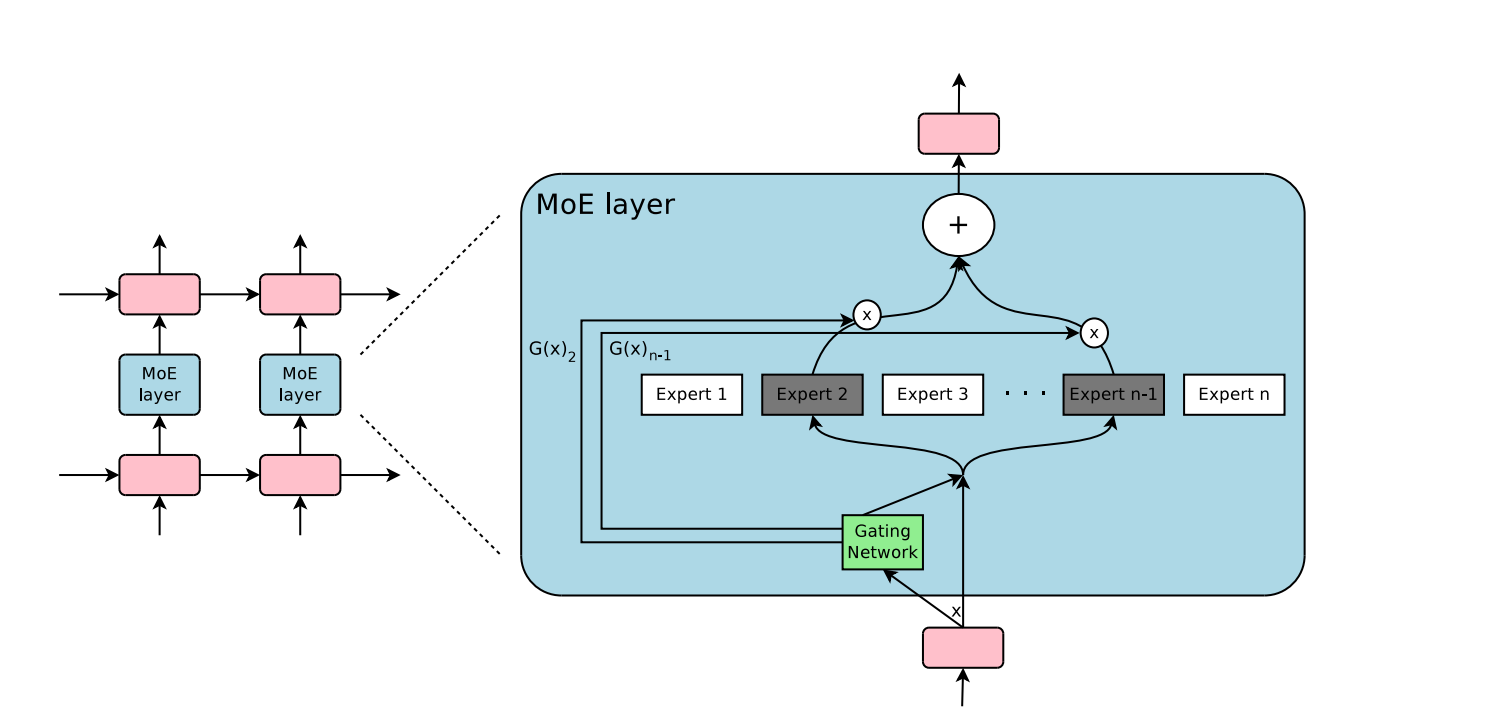
Noam Shazeer, Jeff Dean, and others at Google Brain have been pioneers in applying mixture-of-experts to large language models. In 2017, the paper "Outrageously large neural networks: The sparsely-gated mixture-of-experts layer" introduced the Sparsely-Gated Mixture-of-Experts (MoE) layer. This structure uses a gating network at each layer to select a sparse combination of experts (typically two) to apply to each input at each layer.
A key observation was this:
The capacity of a neural network to absorb information is limited by its number of parameters. Conditional computation, where parts of the network are active on a per-example basis, has been proposed in theory as a way of dramatically increasing model capacity without a proportional increase in computation.
Thus, selecting from ‘experts’ in the models help language models scale and be more capable while keeping inference costs bounded.
This basic approach of a gated expert layer has been applied in multiple research efforts to transformers and LLMs. Work by William Fedus, Barret Zoph and Noam Shazeer published in 2022 made further improvements to mixture-of-experts for LLMs in the paper “Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity.”
In it, they codified the mixture-of-experts concept in transformers as the “Switch Transformer”, where the feed-forward network (FFN) portion of the transformer layer is replaced by independent FFN layers, one for each ‘expert’. They presented improved training techniques for MoE models, and scaled these models to a trillion parameters.

Mixture-of-Experts Challenges and Solutions
While mixture-of-experts has promise for LLMs, there have been challenges in training large MoE models. These models are harder to train, can be unstable and imbalanced in their use of experts, and are prone to overfitting.
Training and gating: First, selecting an expert through a gating router is discrete and not naturally differentiable, but the gating network must be modelled as differentiable for training. In Shazeer 2017, this meant selecting at least two experts and modelling the use of experts as a softmax probability. Mistral’s MoE model chooses two experts (out of 8), as do many other MoE models.
Switch Transformers, mentioned above, is able to reduce the expert number to one while preserving differentiability, which they stated simplified and made the process more efficient.
Another approach to resolve this is redefining the selection as a probability, as found in the paper “From Sparse to Soft Mixtures of Experts,” where they propose a fully-differentiable sparse Transformer called Soft MOE, that addresses these challenges by passing different weighted combinations of all input tokens to each expert. This is applied to vision transformer models (ViTs), but not yet applied to decoder-based LLMs.
Expert imbalance: During training, if a subset of experts become better than others, the MoE model could favor those experts to such an extent all tokens are routed only some experts, excluding other experts and thereby hurting the model overall. The solution is to include a loss function factor for balanced use of experts, discouraging imbalances.
Another solution is to introduce noise in the model, to make the behavior more robust and avoid overfitting, but that has a downside of slowing down training overall, so researchers have looked for alternative answers.
A high branching factor makes the network harder to train and can lead to imbalance. One solution to help make training easier (from Shazeer 2017) is the use of hierarchical gating: “If the number of experts is very large, we can reduce the branching factor by using a two-level hierarchical MoE.”
A recent paper “Fast Feedforward Networks” takes this to the extreme of proposing a binary tree “Fast Feedforward Network” to replace the Feedforward layer. They showed this had better trainability than MoE and was up to 6x faster.

The paper “COMET: Learning Cardinality Constrained Mixture of Experts with Trees and Local Search,” presented at KDD 2023, takes a similar tree approach. It uses a variant of differentiable (a.k.a. soft) decision trees to address the challenge of training expert selection in MoE models.
Training Mixture of Experts Better
To address the issues of training mixture-of-experts LLMs more efficiently, Microsoft in early 2022 introduced and open-sourced DeepSpeed, a mixture-of-experts training library, that offered a 5x reduction in training costs and similar reductions in inference cost and latency on the NLG architecture. They presented their research in “Scalable and Efficient MoE Training for Multitask Multilingual Models.”
They showed equivalent pre-training loss curves for a 1.3B+128 MOE model and a 6B dense model. The 6.7B dense model with 6.7 billion parameters has equivalent performance to the 1.3B+MoE-128 with 52 billion parameters. The 1.3B+MoE-128 MoE model reduced training cost by 5x and had lower inference cost and latency, but the MoE model had 8 times the parameters of an equivalent dense model.
To put this in perspective for Mistral’s 8x7B model, the 8x7B model would perform as well as a 14B to 20B dense model.
Megablocks is an open-source library for training mixture-of-experts model that Mistral themselves apparently used for their own training.
Why Use Mixture of Experts?
The mixture-of-experts AI model has important benefits compared to dense models, it’s a way to use more training time to trade off for less inference cost and time. Since inference time and latency is a concern to users of models, it makes mixture-of-experts and similar sparse AI models an attractive alternative to large dense models.
For these reasons, we can expect to see large foundation AI models to adopt mixture-of-experts or similar forms of sparse models. It’s the most efficient way to scale up on knowledge and capability while keeping inference cost and speed in-line.
The future of LLMs is multi-modal and sparse.
Postscript - An Update
Hugging Face had the same thought I did and decided the release of Mixtral 8x7B was a good time for An Explainer on Mixture of Experts. Their blog posts covers similar ground to our article but points out additional recent research and considerations on MoE models, specifically around fine-tuning.
How is it that an 8x7B MoE model ends up ‘only’ 45B parameters? Simply put, the mixture-of-expert layer duplicates the FFN 8 times, but not the attention mechanism, which remains unitary on each layer. So it’s not duplicating 7B parameters, but a subset of that by 8, and adding further parameters for routing. The 45B parameter model with bfloat16 numbers yields an 87 GB model file.
Will Fedus, Barret Zoph, Noam Shazeer and colleagues at Google Brain did further work beyond Switch Transformers to explore and improve mixture-of-expert LLMs. They produced two papers of note, “GLaM: Efficient Scaling of Language Models with Mixture-of-Experts” and “ST-MoE: Designing Stable and Transferable Sparse Expert Models,” focused on solving the practical challenges in training and fine-tuning MoE models more reliably.
References
Jordan, M. I., & Jacobs, R. A. (1994). Hierarchical Mixtures of Experts and the EM Algorithm. Neural Computation, 6(2), 181–214.
David Eigen, Marc’Aurelio Ranzato, and Ilya Sutskever. 2013. Learning factored representations in a deep mixture of experts. arXiv preprint arXiv:1312.4314.
Shazeer, Noam, et al. 2017. Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538.
Fedus, W.; Zoph, B.; and Shazeer, N. 2022. Switch transformers: Scaling to trillion parameter models with simple and efficient sparsity. The Journal of Machine Learning Research, 23(1): 5232–5270.
Joan Puigcerver, Carlos Riquelme, Basil Mustafa, Neil Houlsby. 2023. From Sparse to Soft Mixtures of Experts. arXiv preprint arXiv:2308.00951.
Shibal Ibrahim, Wenyu Chen, Hussein Hazimeh, Natalia Ponomareva, Zhe Zhao, and Rahul Mazumder. 2023. COMET: Learning Cardinality Constrained Mixture of Experts with Trees and Local Search. In Proceedings of the 29th ACM SIGKDD Conference on Knowledge Discovery and Data Mining (KDD ’23), August 6–10, 2023. https://doi.org/10.1145/3580305.3599278
Kim, Young Jin, et al. 2021. Scalable and Efficient MoE Training for Multitask Multilingual Models. CoRR, arXiv preprint arXiv:2109.10465.