


On Situational Awareness Pt 1: The Race to AGI
The race towards AGI, then a quick take-off to ASI


Leo’s Thesis
Leopold Aschenbrenner is an interesting young man. He studied economics and graduated valedictorian at Columbia University at age 19(!), got involved with Sam Bankman Fried’s Founders Fund, and then when SBF’s empire collapsed in scandal, he moved on to work at OpenAI’s super-alignment team.
Then earlier this year, he got fired from OpenAI for ‘leaking information’ that sounds like he was fired for sharing warnings about AI safety and not following the OpenAI ‘party line’.
This article is not about Leopold himself, but about what he has to say about artificial intelligence progress, shared in a long blog Essay “Situational Awareness” and in a recent Dwarkesh Patel podcast. When I say long, I mean the full essay series as a PDF is 165 pages long, and the Dwarkesh Patel podcast ran four hours.
It’s interesting, mostly on-target, and reflective of what some in the San Francisco AI startup scene are thinking:
Our AGI and ASI future is near - AGI by 2027 and ASI this decade - and it will have major implications for our economy and national security. Who wins the race to ASI in the next decade will determine the global order this century.
The AI Decade Ahead
Dedicated to Ilya Sutskever, Leopold Aschenbrenner’s “Situational Awareness” discusses the rapid rise in AI capabilities.
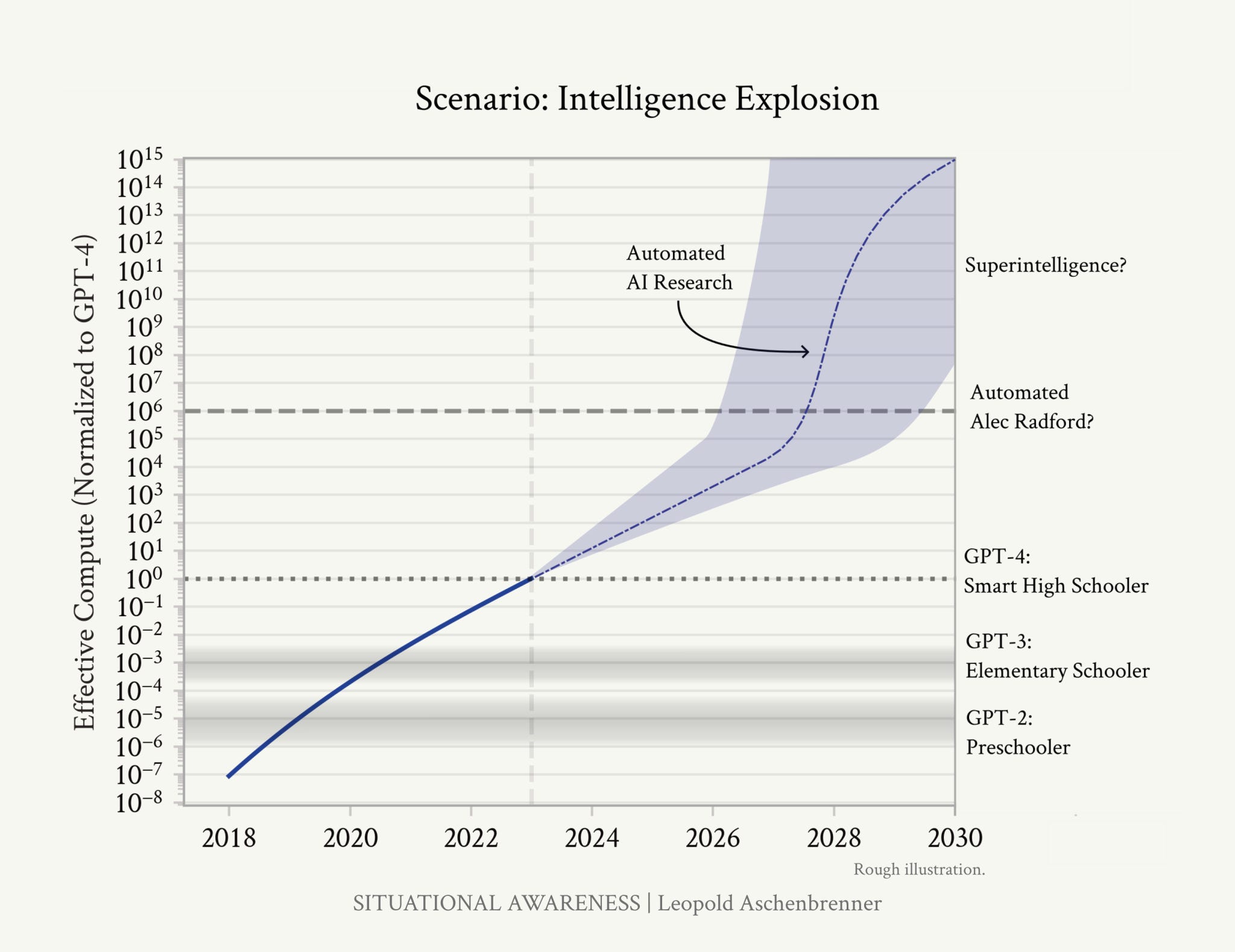
We are on course for AGI by 2027. LLM advancements toward AGI are due to three factors: increases in compute power, algorithmic improvements, and “unhobbling” techniques. It won’t be long before they’re smarter than us.
AGI will cause a massive acceleration in technology progress in many things, in particular accelerating AI development itself. AI progress acceleration will quickly move us into ASI.
AGI and ASI will birth massive technology and science acceleration and economic growth. It will do this because AI systems will basically be able to automate basically all cognitive jobs (think: all jobs that could be done remotely).
ASI-based technology superiority begets massive geo-political power and military advantage. It will have major impact on our national security and the national security of every nation will be impacted, that in his scenario necessitates a national-security-driven program to build ASI and to lock it down from others.
This article will focus on the first part of this - getting to AGI.
AGI By 2027
AGI by 2027 is strikingly plausible. AGI by 2027 is strikingly plausible. GPT-2 to GPT-4 took us from ~preschooler to ~smart high-schooler abilities in 4 years. Tracing trendlines in compute (~0.5 orders of magnitude or OOMs/year), algorithmic efficiencies (~0.5 OOMs/year), and “unhobbling” gains (from chatbot to agent), we should expect another preschooler-to-high-schooler-sized qualitative jump by 2027. - Leopold Aschenbrenner
Much of his argument for AGI by 2027 is drawing a straight line from prior progress and extrapolating it forward. LLM progress has and along three sources of progress are driving LLM improvements:
Trendlines in compute (2-3 OOMs)
Algorithmic efficiencies (1-3 OOMs)
“unhobbling” gains
Putting these gains together will produce “6+ OOM (orders of magnitude) better AI in 3 years” That will be e is including the This will give us AGI, and the equivalent of an automated AI research engineer.
Let’s unpack these three components and explain what “unhobbling” means, to understand whether this scenario and prediction is on target.
Scaling up simple deep learning techniques has just worked, the models just want to learn, and we’re about to do another 100,000x+ by the end of 2027. It won’t be long before they’re smarter than us. - Leopold Aschenbrenner
Compute Trends

The improvement in compute applied to AI model development in the past has been 0.6 OOM (orders-of-magnitude), which represents a massive 6-fold improvement every single year.
To understand why the 2024 - 2027 roadmap on compute will continue, you only need to look at the Nvidia roadmap. Nvidia continues to dominate data center compute for AI model training, and their roadmap is to release Blackwell (2024), Blackwell Ultra (2025), and Rubin (2026), in the next 3 years. Blackwell is 5 times more powerful than its Hopper H100 predecessor at AI training.

Now, Moore’s Law and Nvidia scaling up larger GPUs will not yield 6x per year increase in AI model compute. Much of that is building larger systems and running longer and bigger AI model training runs.
While his thesis contemplates $10 billion and then $100 billion clusters, it begs questions of limits on scaling such massive AI data centers: Chip availability; energy production for 10GW datacenters; ROI on $100 billion clusters.
For the next few years though, the money, chips, and energy is available for another 10x and perhaps 100x increase in AI compute infrastructure.
The translation from compute into AI model performance has been fairly direct. More compute allows for more data and parameters, and all that translates into higher model performance.
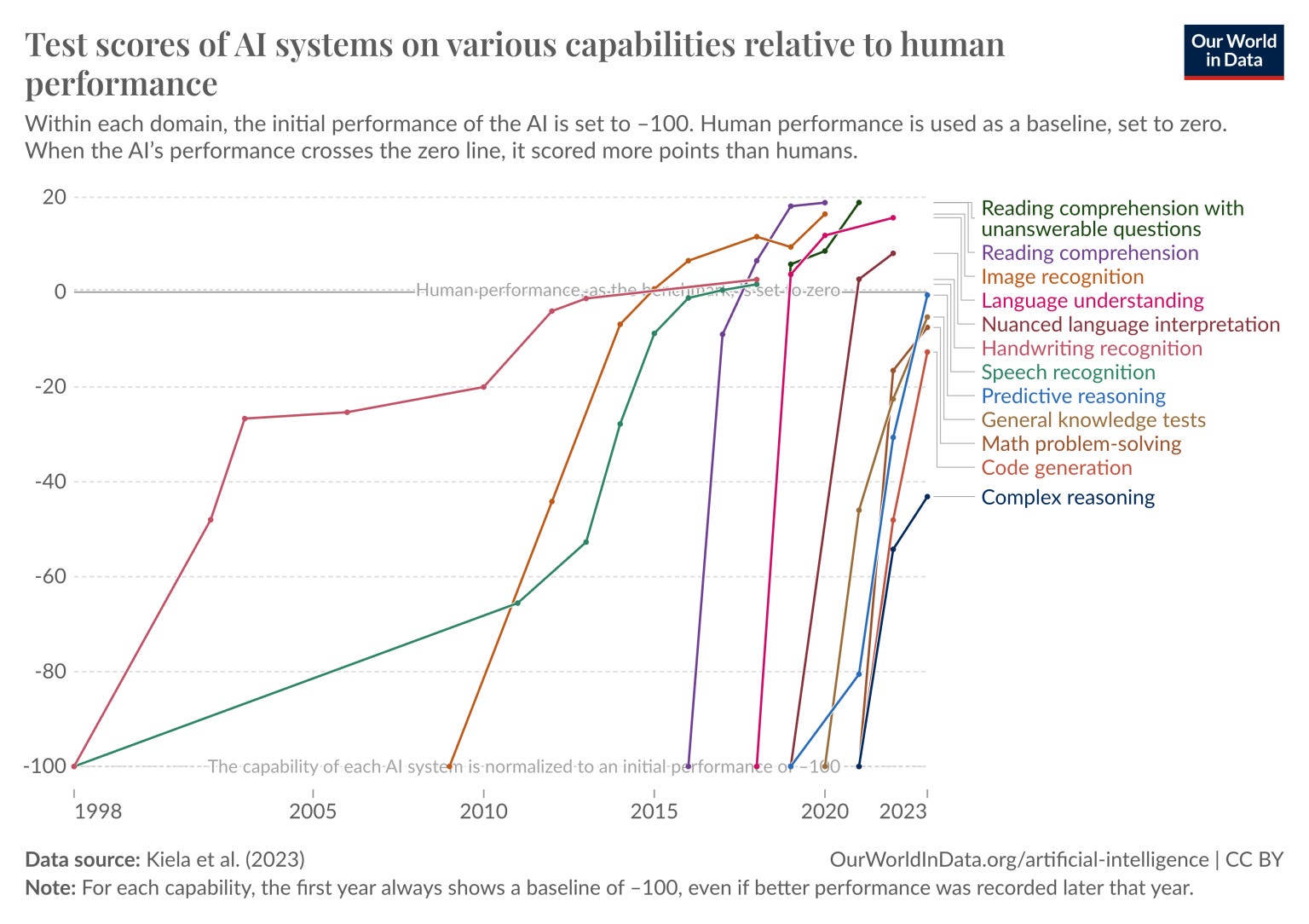
Algorithmic Gains
The next category is algorithmic gains. The below figure is from the paper “Algorithmic Progress in Language Models,” that shows how LLMs have improved based on algorithmic improvement.

Leopold simply extends the trend forward, projecting 0.5 OOMs or 5x improvement per year:
Over the 4 years following GPT-4, we should expect the trend to continue: on average 0.5 OOMs/yr of compute efficiency, i.e. ~2 OOMs of gains compared to GPT-4 by 2027. While compute efficiencies will become harder to find as we pick the low-hanging fruit, AI lab investments in money and talent to find new algorithmic improvements are growing rapidly.
Given the massive numbers of AI papers, new AI models, and innovations that come out each week, this is not an unreasonable estimate, at least in the near-term. Long-term, however, we could question if and when there is an efficiency “ceiling” on AI models.
For example, we’ve learned that high-quality data can help us train better AI models with less data. How far can that go?
Unhobbling AI
What does ‘unhobbling’ mean? He describes unhobbling gains as “paradigm-expanding/application-expanding” algorithmic progress that unlocks capabilities of base models.
Leopold calls LLMs “hobbled” by gaps in capabilities, and the ‘un-hobbling’ are various breakthroughs to overcome that. In particular, he suggests breakthroughs in AI systems that will enable higher-level reasoning and capability in AI models, saying of AI, “It needs to learn the system 2 thinking.”
He gives examples of prior ‘unhobblings’ that made LLMs much more capable:
RLHF (Reinforcement Learning with Human Feedback): Instruction fine-tuning of models via RLHF made them far more responsive and precise in instruction-following.
Chain of Thought: LLMs were bad at math, but this prompting tweak unlocked much better performance on reasoning tasks.
Scaffolding: Similar to CoT, these methods include review, critique and other agentic and iterative methods to get LLMs to reason better; this is a path towards AI agents.
Tools: Use of other programs and tools gives LLMs the capabilities of such tools.
Context length: Going from 2k token context (GPT-3) to Gemini 1.5 1 million token context unlocks a lot of capability.
He sees current GPT-4-level chatbots as still ‘hobbled’ by their weaknesses in autonomy and reasoning, and that unhobbling breakthroughs are needed to develop the a GPT-6 level AI model into an autonomous and useful AI Agent, an “agent-coworker.” He sees three possible unhobbling breakthroughs:
Solving the “onboarding” problem: Perhaps using long context or other methods, AI models will need to be better and quicker at personalization and knowing what we want them to do, without long training time.
Test-time compute: This is about getting AI models to think more about their response to hard tasks, trading off more compute effort at inference for better responses.
Using a computer: He sees this as the next step beyond current ‘tool use’ in AI models / systems. There examples like Open Interpreter that are trying to do this; Rabbit R1 promised similar; and the Apple App Intents is a move in this direction. It’s a key unlock for making AI agents extremely useful at all manner of computer-bound tasks.
These unhobbling challenges are not new or unknown; they have been worked on and progress is being made already. This suggests that we will overcome these challenges.
Putting is all together, he gives the example of Devin, the AI agent for software engineering as what the future AI model might look like.
AI Agents vs AI Models
My take: I would distinguish between AI models and AI agents. AI agents are a type of AI application built upon foundation AI models as a component.
A GPT-6 AI model might go beyond the current single AI model query-response paradigm and have agentic capabilities. However, a real full AI agent will need to be outside a given AI model.
If we understand unhobblings as algorithmic, architectural and efficiency breakthroughs needed to get to AGI, then some of the above examples are algorithmic improvements to LLMs. Those might be double-counting with LLM algorithmic improvements already mentioned.
Leopold himself uses this dichotomy to distinguish:
“within-paradigm” algorithmic improvements—those that simply result in better base models, and that straightforwardly act as compute efficiencies or compute multipliers.
“paradigm-expanding/application-expanding” algorithmic progress that unlocks capabilities of base models.
A better way to categorize is to distinguish between algorithmic improvements to LLMs - LLM algorithmic improvements - and AI system improvements outside LLMs - non-scaling AI system improvements.
In speaking of “paradigm-expanding” progress including AI agent capabilities, he makes an assumption that AI models will subsume or encompass AI agents. I find that an interesting perspective from a former OpenAI researcher, because it suggests that OpenAI will eventually try to build AI agents.
Perhaps AI architecture is a detail and the final result is the same: GPT-6-level AI systems based on foundation AI models will be be fully agentic. However, understanding AI agents and frontier AI models as distinct, helps us evaluate progress on each of them as related but distinct.
Breakthroughs vs Scaling for AGI
There have been skeptics of LLMs, such as AI researcher Yann LeCun, who say that LLMs, no matter how much scaling you do, will never get us to AGI.
On the other side are people like Ilya Sutskever, who say that “scaling is all you need.”
I find myself with others like Demis Hassabis, who says that breakthroughs are needed to get to AGI, but is optimistic about progress and says AGI is coming soon.
Situational Awareness is also presenting a synthesis of these camps. By presenting ‘paradigm-expanding’ unhobbling gains as a necessary component for progress, Leopold is saying scaling LLMs isn’t enough.
The AGI Timeline
Where Situational Awareness is right: The thought process and projected path to get from here to AGI makes a lot of sense.
The path to AGI is well-laid and will follow similar trends that got us from GPT-2 to GPT-4: Chip scaling, greater investments in chips and AI training; algorithmic improvements; plus, some key breakthroughs, such as getting AI systems to operate computers (take actions) and have agentic capabilities.
However, Leopold’s estimates of AGI timelines are aggressive. Let’s review the OOMs, order-of-magnitude:
The compute trend for AI models from Epoch AI is 0.6 OOMs per year. A 6-fold improvement every year is aggressive relative to Moore’s Law and NVidia chip roadmap, but greater investment can fill the gap. Even if we need $10 billion data centers, Elon Musk will build it.
The “Algorithmic Progress in Language Models” paper says: “Models require 2× less compute roughly every eight months” That works out to be about 0.3 OOMs / yr, more conservative than his 0.5 OOMs / yr estimate.
I can agree that the breakthroughs (unhobblings) to get us AI Agents, and many more innovations, will happen over the next few years.

Rounding that up becomes 1 OOMs per year of all-in improvements. At 1 OOM per year, Leopold’s own projection of 5 OOMs to get to AGI suggests 2028-2029 as an expected (50% probability) AGI arrival time-frame.
I have previously predicted 2029 as an AGI timeline and for now I will stick with it, while admitting a few things:
Many areas of progress are more rapid than I (and most of us) expected, so we may be surprised.
An AI that is with just 3 OOMs or 1,000 times more effort to train than GPT-4, let alone 10,000 times more, will be powerful indeed. Even if not AGI, it will still drastically impact our productivity, economy and society.
The exact date of AGI’s arrival is less important than the ongoing AI-driven acceleration that feeds on itself as we improve AI to AGI and beyond.
The arrival of AGI won’t be like a train coming into a station. It will be more like a bullet train at full speed going through the station.
As Leopold puts it: AI progress won’t stop at human-level.
Most of Situational Awareness covers what happens after AGI - the intelligence explosion, ASI, and the national security implications - which we will discuss in follow-up articles. Stay tuned, the ride hasn’t ended.
Off subject..The now and coming AI revolution ….and no one can stop robo calls.. No one can seem to offer a service to stop them. I would think this AI would make such a nuisance more effective and less limitable. Am I wrong?