


OpenAI Goes Omni: GPT-4o
Integrated voice/text/video GPT-4o model delivers "HER"-like conversational voice, video/image understanding, and a faster, cheaper, AI model for all ChatGPT users. Plus, ChatGPT desktop app.


OpenAI Announces GPT-4o
“With GPT-4o, we trained a single new model end-to-end across text, vision, and audio, meaning that all inputs and outputs are processed by the same neural network. Because GPT-4o is our first model combining all of these modalities, we are still just scratching the surface of exploring what the model can do and its limitations.” - OpenAI
Say hello to GPT-4o. OpenAI’s May 13 “Spring Update” announcement wasn’t search, nor a more advanced reasoning engine, nor GPT-5. They announced their new flagship model, GPT-4o. It’s a native text, vision, and audio input and output model, the “o” stands for “omni”.
The main new features of GPT-4o is the model is The native voice, text and vision AI model gives it better reasoning on different modalities and a lot of other benefits:
Voice interface: Real-time audio conversation, with amazing voice, inflection, and humor. It’s more natural, and there is no waiting like voice mode before, which relied on translation of text to audio on input and output.
Native image understanding, recognizing images and photos and generating image-based output.
Available on free tier ChatGPT, and cheaper on API faster on text, audio, and video.
Maintains memory for personalization and future conversations.
Is faster, cheaper, and has quality and speed upgrades for 50 languages.
They also announced a desktop app for Mac, an update to their browser-based ChatGPT UI, and an updated mobile app, all of which will run the flagship GPT-4o, which now supercedes all prior GPT models.
Voice
OpenAI led with the voice conversation capabilities of GPT-4o in their demos, showing a number of engaging and interesting use cases. The voice assistant was able to detect and express in a humanly emotional way, showing emotion sensitivity, emotive styles and dynamics.
In one demo, Rocky suggests wearing a fishing hat to his interview, which elicits a laugh and a jocular “Rocky, that’s quite a statement piece” from the AI model. The level of personableness and expressiveness is remarkable.
GPT-4o Comes with Better Vision
While voice was the headliner in the demo, but their vision features could be just as important. GPT-4o improves on image recognition over the GPT-4 V predecessor, so this might be considered a second generation attempt. Some GPT-4o capabilities in this domain:
Text-to-Font: It can generate font outputs. I tried to replicate this feature, and got, well, mixed results. It turns out the image output is actually Dalle-3 under the hood, and that is frankly, not as compliant to specific prompts for lettering. Our Figure 1 has “GPT-40 arrives!” in celtic (Book of Kells) style, but has trouble generating the right letters.

Image and video recognition: OpenAI trolled Google Gemini with this demo, showing how GPT-4o on a phone app could recognize the gestures in a rock-paper-scissors game and play the referee as a voice assistant. It’s trolling Google because it is delivering on a capability Google purported to show in their December demo, but it was faked up. It’s incredibly useful to recognize visually what’s going on.

Another example of the utility of multi-modality is this 45 min video lecture summarization. This is something only Google Gemini could handle before.
We’ll need to experiment to understand how good the video capabilities really are, but there are many use cases for user interaction as this features gets better.
Reasoning -
GPT-4o boasts marginal improvements on reasoning: MMLU about the same at 88.7, HumanEval bumped up to an impressive 90.2, MATH up to 76.6. It’s really not a game-changer on this front, but it’s still the best AI model in the world.
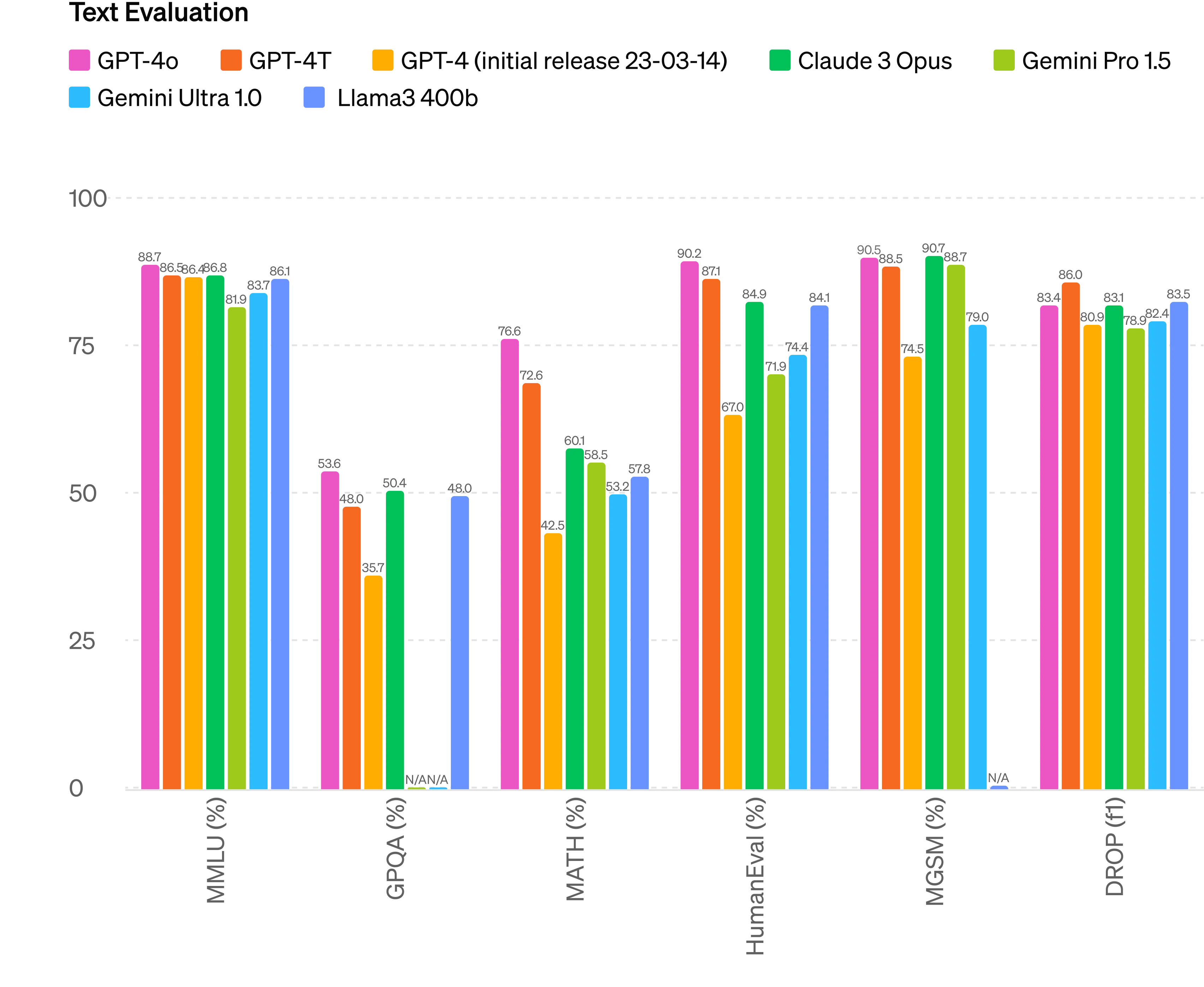
If you were expecting GPT-5 or an AI agent from OpenAI, curb your enthusiasm. This was not a leap in reasoning that some thought OpenAI was working on. Either it’s proving to be a harder problem than OpenAI thought, or this capability is being left in reserve for a future release.
GPT-4o Is Free on ChatGPT
ChatGPT Free users get access for GPT-4o and its features:
Browse with Bing, which searches the internet to help answer questions.
Advanced Data Analysis, which executes code and analyzes data.
Photos and image recognition. or what your iPhone camera sees.
Upload files for summarizing or analyzing documents.
Use custom GPTs from the GPT Store.
Personalize experience and extend understanding with memory.
They have safety concerns around the audio output (consider the capability for deep-fakes), so this part may have a delayed release:
We recognize that GPT-4o’s audio modalities present a variety of novel risks. Today we are publicly releasing text and image inputs and text outputs. Over the upcoming weeks and months, we’ll be working on the technical infrastructure, usability via post-training, and safety necessary to release the other modalities. For example, at launch, audio outputs will be limited to a selection of preset voices and will abide by our existing safety policies.
Faster and Cheaper - API Pricing For GPT-4o
Access to GPT-4o for all users via free ChatGPT. Developers can also now access GPT-4o in the API as a text and vision model. GPT-4o is 2x faster and half the price ($5.00 per 1M tokens for input, $15.00 per 1M tokens for output.
Another GPT-4o improvement is better tokenization, which has a side-effect of making the AI model faster and cheaper for many users, especially using other languages. They show drastic reductions in token counts in 20 languages, chosen as representative of the new tokenizer's compression across different language families.

It’s the “Her” Interface!
the new voice (and video) mode is the best compute interface I’ve ever used. It feels like AI from the movies; and it’s still a bit surprising to me that it’s real. Getting to human-level response times and expressiveness turns out to be a big change. - Sam Altman on GPT-4o
With GPT-4o blessed with a voice interface that is expressive, low latency, and shows common-sense reasoning, we have an AI Assistant that presents itself as about as human as an AI has ever been.
Much X commentary that OpenAI's voice sounds very much like the AI assistant voice from “Her,” the voice of Scarlett Johansson. Their choice of that voice for the demos could be deliberate to evoke comparisons, but OpenAI’s Sky voice is one of several they have to choose from.
Does this Turing-test-passing emotive human voice assistance mean we are at AGI? Not in my book, but the anthropomorphic behavior is going to turn heads. And if you can get it to be an emotional companion AI assistant, it’s not hard to see it melt hearts too.
Multi-modal models are a big step closer to AGI, because it means it can interact and understand our world in ways that we do. The human-like voice interface gives a sense of being convincingly more human, but reasoning is the real issue. On reasoning, this is still GPT-4 level.
Summary
OpenAI delivered an update that raised the bar for AI. Some takeaways:
GPT-4o brings video, image, voice and text into an integrated multi-modal AI model.
Native multi-modal AI models are the new baseline for best-in-class frontier models. Only Gemini and GPT-4o are natively multi-modal.
The voice interface is very human-like, an interface that goes beyond the text prompt in ease of use and naturalness. A “chatGPT moment” for voice AI?
All prior GPT models are literally obsolete, as free ChatGPT users get access to GPT-4o and its features.
Pressure is on Google to compete and deliver. Hopefully, Google I/O will tell us more about Gemini updates and improvements. Is Gemini 1.5 Ultra coming soon?
As for Apple, it may be a win/win for Apple and OpenAI to get GPT-4o voice assistant into the new Siri. This is in truth what Siri should have been by now.
The lack of reasoning progress is the dog that didn't bark. Reasoning progress has been incremental. Two years after GPT-4 was trained, latest reasoning is only slightly better, even while other features (speed, cost, multi-modality) all get better.
What about GPT-5? OpenAI is opaque about roadmaps. Some observers claim that OpenAI is being reactive, delivering just enough capability to stay ahead of the competition, while they have even better capabilities in reserve.
We can glean from hints dropped by OpenAI leaders that future releases will be incremental updates rather than big releases, and GPT-5 won’t be arriving any time soon.