


Qwen 3 Release Brings AI Home
The Qwen 3 release is an open-weights family of high-performing hybrid reasoning models, bringing o1-level reasoning to small AI models you can run locally.


Qwen 3 Hybrid Reasoner Models Released
I didn’t intend to write Yet Another Great New Model article, but this great Qwen 3 AI model family was just released, and it’s too good to pass up.
Alibaba’s Qwen team has released the Qwen 3 AI model family of eight models, featuring six dense and two Mixture of Experts (MOE) architectures. Qwen 3 is a major release of great open-weights AI models, most of which you can run locally, delivering a notable advance of performance across various model sizes.
The MoE models are: Qwen3-235B-A22B, a large model with 235B total parameters and 22B activate parameters, and Qwen3-30B-A3B, a smaller MoE model with 30B total and 3B active parameters. The MoE architecture has128 experts, with 8 of 128 activated for each inference. The largest 235B MOE model rivals leading systems like OpenAI o1 and Gemini 2.5 Pro on benchmarks, despite activating only 22B parameters.
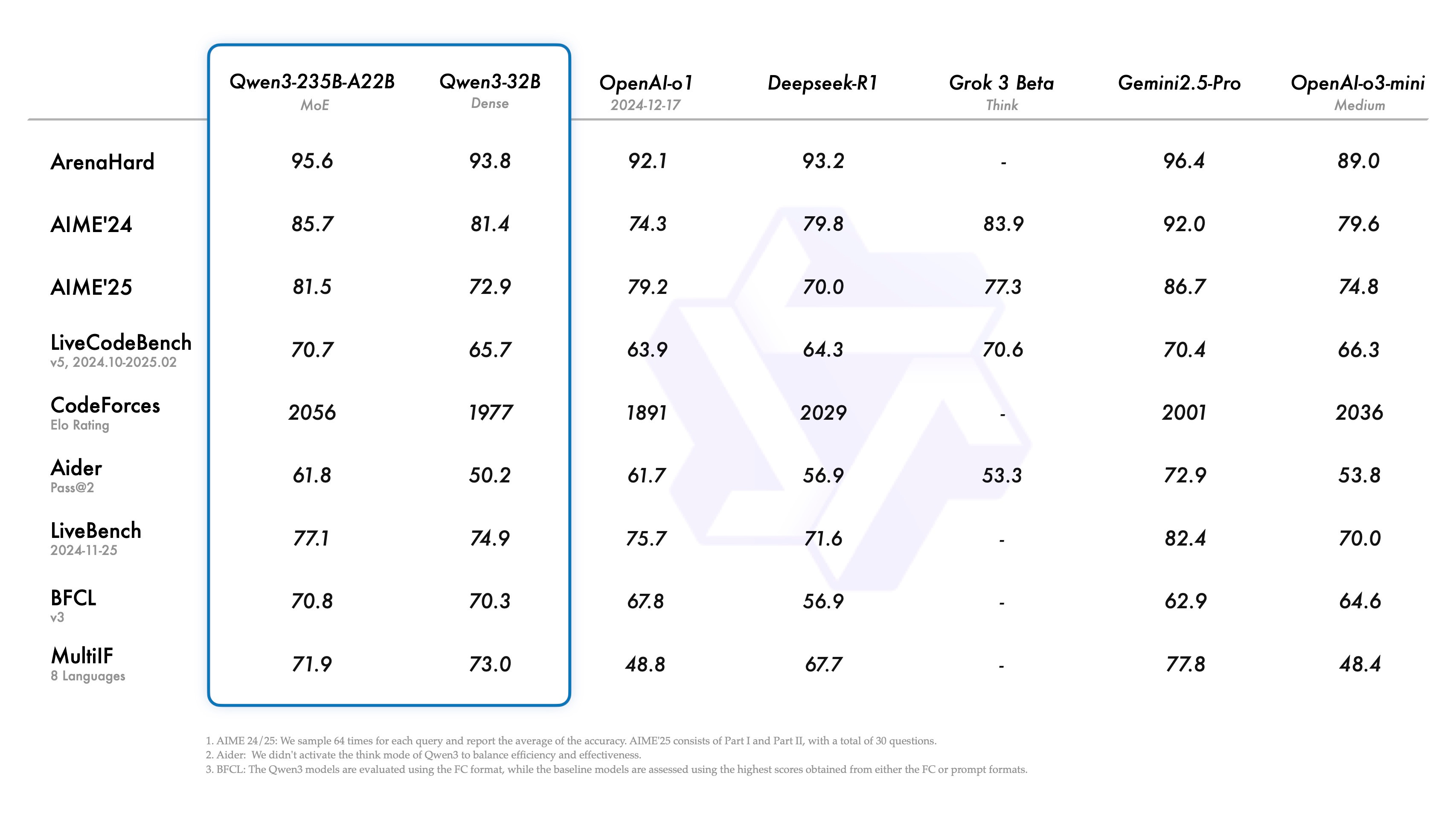
The six dense models range from 32B down to 0.6B: Qwen3-32B, Qwen3-14B, Qwen3-8B, Qwen3-4B, Qwen3-1.7B, and Qwen3-0.6B. All perform excellently and are state-of-the-art for their size. In particular, Qwen 3 32B achieves o1-level benchmark results, SOTA for a model you can run locally.
The Qwen 3 models boast large context windows (up to 128k tokens for 8B and above models), support 119 languages, and exhibit robust coding and agentic skills. This includes sequential tool use and native Multi-Candidate Prediction and Selection (MCPS). Qwen team notes they also have strengthened the support of MCP.
Qwen 3 is very accessible, with weights available on Hugging Face under the permissive Apache 2.0 license, as well as on several other platforms (ModelScope and Kaggle) and deployment frameworks, including my local deployment tool of choice, Ollama, and Qwen’s own chat interface.
Pre-training Innovation: Data Synthesis
While AI foundation models have made remarkable progress in key features in the past year - multimodality, tool use, and reasoning - pre-training scaling has had little to do with most of that progress, and some AI model training efforts struggled to scale pre-training performance. Yet this is not the case with Qwen 3.
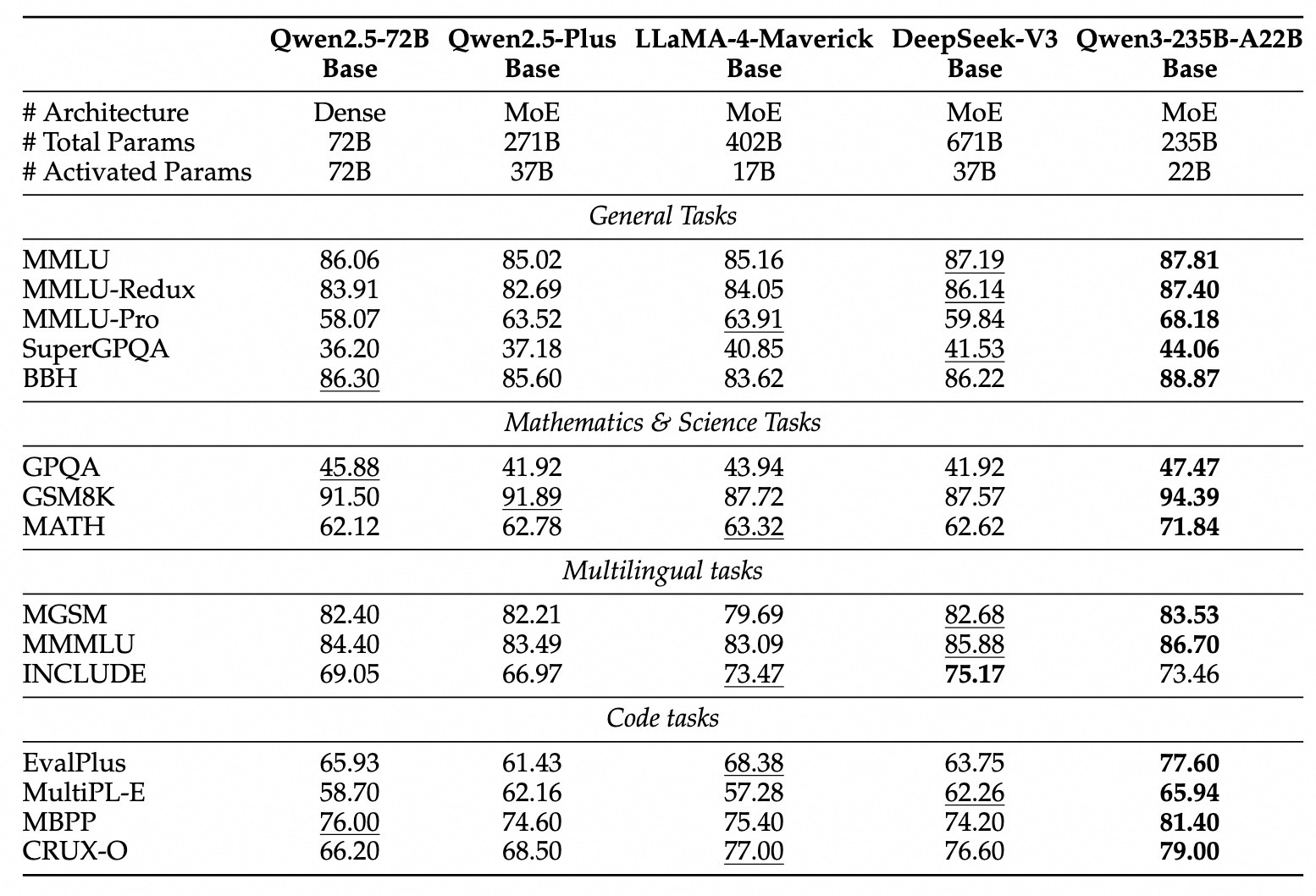
The Qwen 3 models were pre-trained on an extensive dataset of approximately 36 trillion tokens through sophisticated multi-stage pre-training. The Qwen 3 release announcement touts how advances in pre-training yielded even more efficient high-performing AI base models:
Due to advancements in model architecture, increase in training data, and more effective training methods, the overall performance of Qwen 3 dense base models matches that of Qwen 2.5 base models with more parameters.
How did they achieve this? Not by scaling alone. We need massive quantities of high-quality data to scale AI performance, but there are limits on data quantity and quality that are impeding pre-training scaling.
The Qwen team worked around data limitations this by curating synthetic data to improve skills like math and coding, using Qwen 2.5 itself to generate high-quality pre-training data:
“To build this large dataset, we collected data not only from the web but also from PDF-like documents. We used Qwen2.5-VL to extract text from these documents and Qwen2.5 to improve the quality of the extracted content. To increase the amount of math and code data, we used Qwen2.5-Math and Qwen2.5-Coder to generate synthetic data. This includes textbooks, question-answer pairs, and code snippets.”
Synthetic data helped optimize datasets in Qwen 3 training for quality, relevance, and diversity. The end result was Qwen 3 base models that are smaller than DeepSeek V3 and Llama 4 Maverick yet outperform both.
Hybrid Reasoning with 4 Stage Learning
A key innovation is Qwen 3's hybrid reasoning capability, allowing users to toggle between detailed, step-by-step reasoning and faster, direct responses to queries. This capability was trained into Qwen 3 models using a specialized four-stage post-training process.
The first two steps of post-training for hybrid reasoning are similar to the DeepSeek R1 post-training process: A chain-of-thought cold start using diverse long CoT data; and then a scaled up RL utilizing rule-based rewards to enhance model reasoning. The third step integrates non-thinking capabilities into the thinking model by fine-tuning, and the fourth step is additional general RL.

Stellar Small AI Models and MoE
The Qwen team combined pre-training and post-training innovations to enable more efficient small AI models in the Qwen 3 family to perform as well as a bigger AI models of the previous generation.
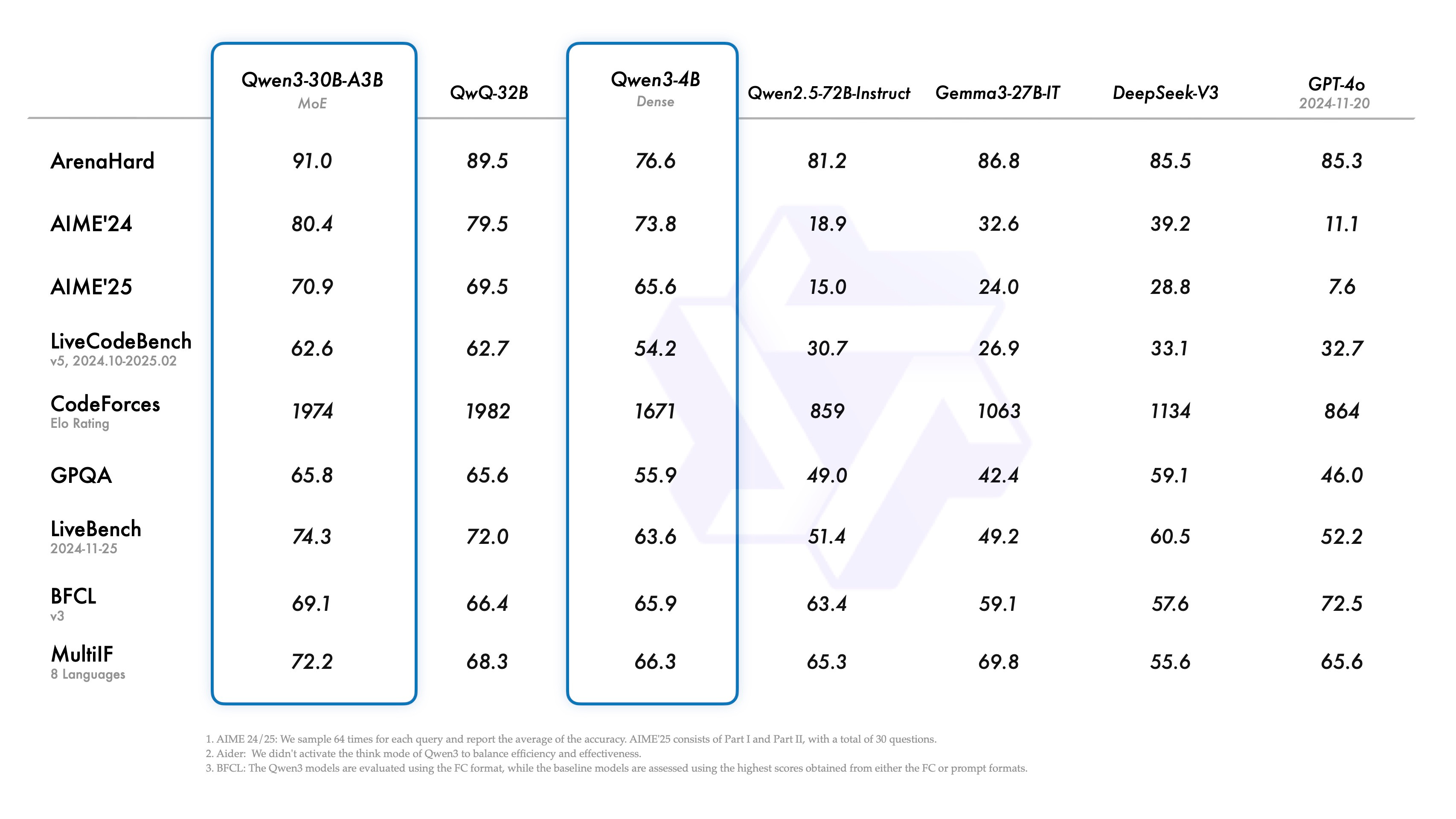
Compounding these improvements with distillation, they were able to distill the Qwen 3-32B model down to high performing 14B, 8B, and 4B models. The Qwen 3-4B model is a remarkable example of extending reasoning capabilities to small AI models; it outperforms GPT-4o on many benchmarks in math and reasoning.
It is likewise remarkable that the Qwen 3-30B-A3B MoE model, with only 3 billion active parameters, performs so well on math and reasoning; it scores 80% on AIME ‘24, better than o3-mini, DeepSeek R1, and o1.
Qwen 3 Has Good Vibes, but It Overthinks
We have learned we need to check AI model benchmark numbers against the ‘vibes’ of real-world use. In less than 24 hours since Qwen 3’s release, many have tried Qwen 3 models and shared their results. Early reports are good, but there are issues.
Bijan Bowen praised the smaller 0.6B Qwen 3 model for coding capabilities. His test of the larger Qwen 3 30B-A3B for various coding and non-coding tests praised it for its efficiency and performance. He notes that you can turn thinking on or off, emphasizing the need adjust sampling parameters.
For coding, it works well. For math, it stays calm. For language, it sounds real, not strange like other models … It’s been a long time since an open-source model was this good.
Qwen’s problem is overthinking. In his first look, GosuCode dinged the larger Qwen 3 models for “way too much thinking,” making them less useful for coding. His conclusion was that “Qwen 3 Plus (Qwen3-235B-A22B) doesn't work at all in RooCode.”
Theo also notes Qwen’s bad overthinking habit:
“Qwen3 maintains the Qwen trend of massively overthinking tasks, generating thousands of thinking tokens and running out of context before answering.”
AICodeKing mentions Qwen’s overthinking problem and thinking in loops. In his view, the models are capable but do not quite reach the performance level of DeepSeek R1 in coding.
My brief use so far of Qwen 32B and Qwen 3 30B-A3B in Ollama has been positive. The 30B MoE model with 3B in active parameters nailed the Snake game in one shot. It can overthink, taking hundreds of words to think about how to reply to ‘goodbye’. However, “no_think” at the beginning of a query turned off thinking.
Qwen 3 overthinking may be a parameter settings issue, since Qwen 3, like other hybrid reasoning models, has an adjustable thinking budget.
Conclusion – Qwen 3 Brings SOTA AI Reasoning Home
Qwen 3 is the AI model release Llama 4 should have been. Qwen 3 establishes a significant new efficient performance standard, bringing open-source AI to near-parity with state-of-the-art proprietary frontier AI models. Qwen 3 also delivers high-performance AI models you can run locally.
The Qwen team achieved this not by just brute-force scaling of compute, but by innovating in the whole training process. In pre-training, they used synthetic data to improve data quality at scale. In post-training, they combined RL for reasoning with RL for non-reasoning tasks to make hybrid reasoning models.
There may be some benchmark chasing in these models, but overall, Qwen 3 checks out as a very robust, efficient, and high-performance family of AI models for real-world use. The smaller Qwen 3 models are state-of-the-art for their size, perfect for running locally. Qwen 3 brings near-SOTA reasoning home to local use.
With open weights Qwen 3 models freely available on HuggingFace under Apache 2 license, we can expect fine-tuned variants of Qwen 3 that provide yet more useful and interesting AI models.
Beyond being a great AI model release, the Qwen 3 release provides useful guidance for the topic I will publish in a follow-up: The challenge of AI model scaling.
and qwen3-235b-a22b is free for use in Openrouter.ai, so no need to worry inferring locally (y). All you need to do is pledge $10 and get 1000 requests a day which is 50 with < $10