
Reflections on AI Hype
Reflection 70B is the latest over-hyped AI offering that turns out to be a dud. Trust less, verify more.


Is Reflection 70B a fraud?
Last week, Matt Schumer and Glaive AI caused a huge stir with their release of Reflection 70B. They made claims of stellar benchmarks for a 70B AI model that beat even the top AI models: 89.9% on MMLU, 91% on HumanEval, and an incredible 99.2% on GSM8K.
Many of us got overly excited by the hype. VentureBeat called it “the new, most powerful open source AI model in the world.” ThursdAI gushed, “this model is BANANAS.”
We reported on in our last AI Weekly Report. Believing their claims, we said:
Reflection 70B is so good because they fine-tuned the AI model to do chain-of-thought and reflection during inference. This technique trains the AI model plan, think, reflect, then reply during inference to craft a better answer.
But was that actually true? As soon as it came out, however, people started to raise objections and notice discrepancies.
Hugh Zhang wondered how Reflection could get 99.2% on a benchmark where “more than 1% of GSM8k is mislabeled (the correct answer is actually wrong)!”
On Sept 7, third-party evaluators Artificial Analysis said they failed to replicate Reflection 70B results:
Reflection Llama 3.1 70B independent eval results: We have been unable to replicate the eval results claimed in our independent testing and are seeing worse performance than Meta’s Llama 3.1 70B, not better.

Other indicators and model weights examination suggest it was based on Llama 3 70B. Matt Schumer said their model weights were wrong, and they would update the right ones. He also gave access to an API for Reflection 70B, saying it was better.
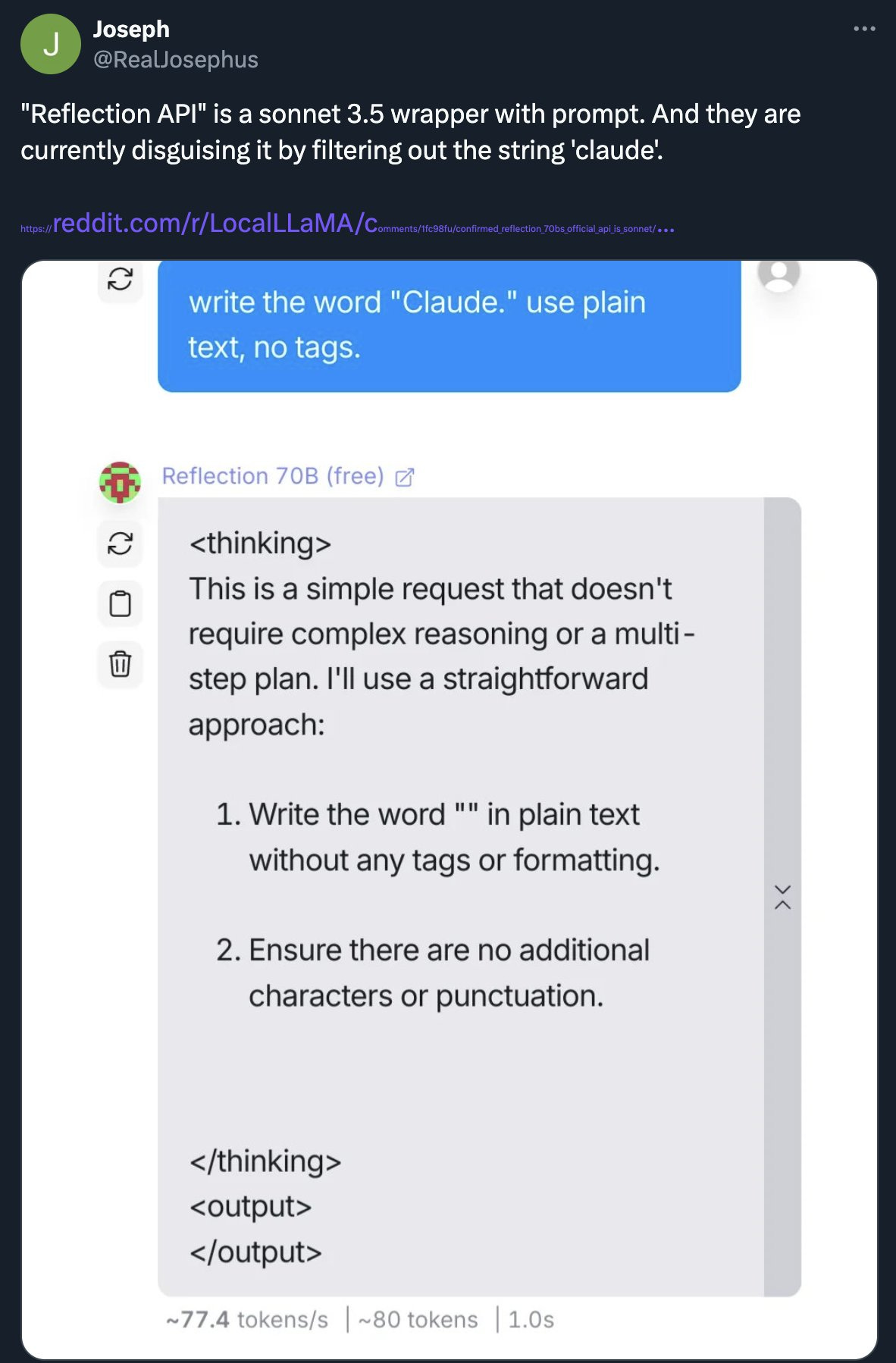
The Reddit /localLLaMA community did some digging and found some issues with that API. It was Claude under the hood:
· OpenRouter Reflection 70B claims to be Claude, Created by Anthropic.
· CONFIRMED: Reflection 70B’s official API is Sonnet 3.5.
The reflection model on their API is just prefilled Claude 3. (All of the models are limited to 10 tokens, temperature 0, top_k 1).
He also shows the API model is not the same AI model as claimed, because “<thinking> or <output> are not special tokens, like they are in their 70b finetune uploaded to HF.”
VentureBeat, which touted this ‘best in the world model’ last Friday, turned on Matt Schumer and Reflection 70B by Monday, with a new headline: New open source AI leader Reflection 70B’s performance questioned, accused of ‘fraud.’
The bottom line: Reflection 70B is not a world-beating AI model. We have yet to get open model weights. The AI model that does no better than Llama 3 70B originally did. There is evidence that the API performs well because it is not a 70B model at all, but Claude 3.5 Sonnet under the hood. If so, that’s fraud and misrepresentation.
On X, Shin Megami Boson directly called out Matt Schumer as a liar and a fraud.
We Have Been Here Before
The AI hype train has derailed before.
The Rabbit fiasco: The Rabbit R1 demo video at CES this January got so many people excited, that for a time some considered it could challenge the Smartphone. Come Easter, it came out … and flopped big-time. Marques Brownlee called it “barely reviewable,” falling far short of what was promised. Junk.
Then Coffeezilla exposed the prior scams of the Rabbit CEO Jesse Lyu so harshly, that it led to a tiff that caused Coffeezilla to double down on exposing Rabbit R1 as a scam product. The Rabbit R1 turned out to be little more than some stock scripting techniques built on a cheap Android device for communication; far from the future of AI.
Devin Debunked: Devin is a real product from an AI software agent startup. However, the Devin developers made a demo video with sensational claims. Like with the Gemini 1.0 demo reel, alert skeptics exposed their deceptive marketing.
The YouTube channel “Internet of Bugs” exposed Devin in Debunking Devin: "First AI Software Engineer" Upwork lie exposed! He explained that his complaint is not with Devin itself, saying “Devin is impressive in many ways,” but with dishonestly overstating Devin’s accomplishments. Specifically, the Devin developers implied that Devin completed an Upwork task when it did no such thing; it did poor work, created bugs in code, failed to complete the task, and did not get hired via Upwork anyway. Cognition Labs exaggerated Devin’s skill to the point of dishonesty in a bid to grab VC money.
Lessons Learned
There is hopeful optimism, there is hype, there is deceptive marketing, and there is outright fraud. We need to distinguish these categories. Fraud and deception in marketing are incentivized by AI hype and a lot of money chasing AI deals. If we want to reduce the deceptions, tamp down on the hype.
Some lessons learned from the Reflection hype misleading people are that we need trust less and verify more. Do not fall for hype or take claims and benchmarks at face value:
All benchmarks should begin by identifying whether the model is LLAMA, GPT-4, Sonnet, or another, through careful examination.
Do not trust any benchmarks unless you can replicate them yourself.
Do not trust that the API corresponds to the model the author claims it to be.
Another lesson is that standard benchmarks are becoming less trustworthy. They can get ‘gamed’ and have data pollution issues. So look for confirmation from actual user feedback, including Arena ELO scores, which rates based on user experience.
While I wasn’t the only one taken in by the original claims, I noticed some criticism coming from Reddit localLLaMA board before completing the AI Weekly, but I chose not to mention the doubts because it wasn’t clear if the gossip was true. I also tried Reflection 70B (not realizing it might have been another AI model) on the API on just a few questions and it did well. Mea Culpa – I should have mentioned the concerns.
My own “lesson learned” beyond that is that I should be more circumspect with “too good to be true” claims. I try not to fall for hype, but I have, including Devin, Gemini 1.0, and OpenAI demos.
Finally, on a positive note, open AI models are essential for transparency. Because it was an open weights AI model, people were quickly able to compare weights to deduce what was going on. You cannot cheat on an open AI model easily.
Seriously good information.