


SHOCK NEWS x2! Gemini 1.5 & Sora Breakthroughs
Gemini 1.5 delivers whopping 10 million context window, OpenAI's Sora generates stunningly better video from text


Two Big Reveals
Please excuse the “Shock News” headline, but this is not click-bait, it’s real - a genuinely huge pair of AI release announcements today have genuinely surprised me and in a good way.
I was ready to write an article covering Google’s big leap with Gemini 1.5 when I saw the announcement this morning. Google announcing “Gemini 1.5 pro is as good as Gemini 1.0 Ultra” is enough to take notice, but showing off a 1 million token context window in a production AI model is most remarkable.
However, OpenAI didn’t want to leave Google to have today’s AI news cycle to itself. So they dropped their own big reveal: Sora, a new text-to-video model that’s a huge leap forward with better consistency, fidelity and realism.
These two announcements are unrelated but have common themes. They both show huge progress in AI’s understanding and expression in video. They both show AI progress is on a steep curve and problems are getting solved quickly. AGI unlocked soon.
Google Announces Gemini 1.5
Google went big in their Gemini 1.5 announcement. It started with a note from CEO Sundar Pichai:
Our teams continue pushing the frontiers of our latest models with safety at the core. They are making rapid progress. In fact, we’re ready to introduce the next generation: Gemini 1.5. It shows dramatic improvements across a number of dimensions and 1.5 Pro achieves comparable quality to 1.0 Ultra, while using less compute.
Then Demis Hassabis gave the full Gemini 1.5 introduction:
Gemini 1.5 delivers dramatically enhanced performance. It represents a step change in our approach, building upon research and engineering innovations across nearly every part of our foundation model development and infrastructure. This includes making Gemini 1.5 more efficient to train and serve, with a new Mixture-of-Experts (MoE) architecture.
The first Gemini 1.5 model we’re releasing for early testing is Gemini 1.5 Pro. It’s a mid-size multimodal model, optimized for scaling across a wide-range of tasks, and performs at a similar level to 1.0 Ultra, our largest model to date. It also introduces a breakthrough experimental feature in long-context understanding.
Demis covers the main benefits of the Gemini 1.5 AI model as well as the safety and ethics guardrails on the model. Gemini 1.5 breaks ground in a number of ways, but the top three are:
Efficiency: “a highly compute-efficient multimodal mixture-of-experts model”
Long context window: “recalling and reasoning over … millions of tokens of context”
Performance: “Dramatically enhanced performance”
While Google has made progress in the overall approach with Gemini 1.5, they are releasing only the Gemini 1.5 Pro now, likely because Ultra 1.5 is still training or yet to be trained.
Gemini 1.5 Architecture
Google also released a technical report titled “Gemini 1.5: Unlocking multimodal understanding across millions of tokens of context” with this announcement, to explain details of Gemini 1.5 model’s architecture and performance.
Gemini 1.5 Pro architecture is a multi-modal mixture-of-expert (MoE) model “that builds on Gemini 1.0’s .. multimodal capabilities … and a much longer history of MoE research at Google.” It was trained on Google’s TPUv4 accelerators, and many improvements to the model and training stack yielded a higher performance AI model that needed less pre-training effort and is more efficient at inference.
The pre-training dataset is multi-model for Gemini 1.5, including web documents, code, image, audio, and video content. Instruction fine-tuning used a collection of multimodal data (containing paired instructions and appropriate responses), with further tuning based on human preference data.
Gemini 1.5’s Long Context Length
Through a series of machine learning innovations, we’ve increased 1.5 Pro’s context window capacity far beyond the original 32,000 tokens for Gemini 1.0. We can now run up to 1 million tokens in production.
Gemini 1.5 Pro has a “long-context understanding of inputs up to 10 million tokens without degrading performance.” This remarkable feat is not out of the blue; recent research has explored and advanced various approaches to creating longer context windows for LLMs.

Gemini 1.5 Pro can also take as input a mix of audio, images, videos, text, and code. This multi-modal input is a powerful combination with a large context window.
Translated into real world data, this context length enables Gemini 1.5 Pro models to comfortably process almost a day of audio recordings (i.e., 22 hours), more than ten times the entirety of the 1440 page book (or 587,287 words) "War and Peace", the entire Flax (Heek et al., 2023) codebase (41,070 lines of code), or three hours of video at 1 frame-per-second.
They shared several examples of long context window multi-modal input used in their technical report, and the results found. For example, they showed inputting an entire 45 minute-long Buster Keaton silent movie, then asking the model questions about it. Video input is translated into 1 frame-per-second tokenized representations, and then it is analyzed as part of the AI model’s context.

They show good recall on audio and text as well, and they also claim a remarkable 99% recall all the way up to 10 million context window tokens using various Needle-in-haystack tests.
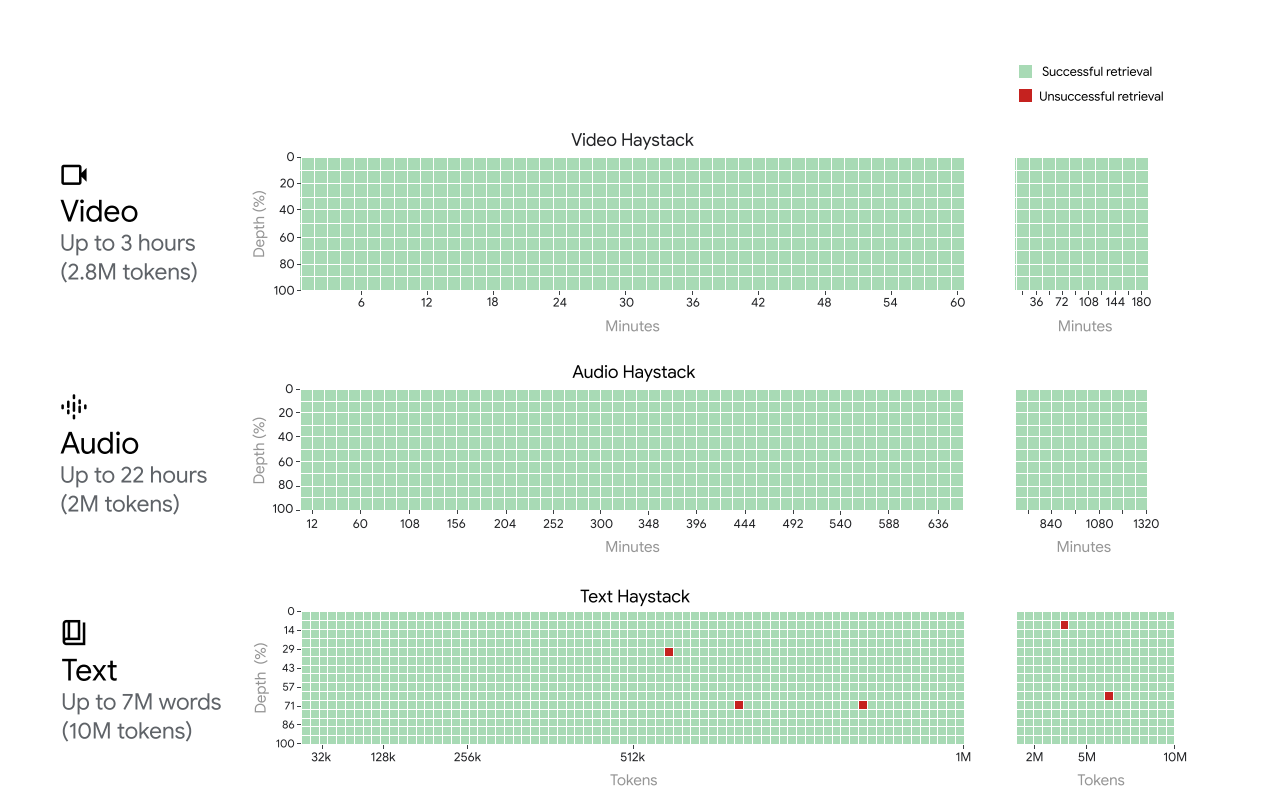
A high quality AI model that can reason about long-context video and audio hugely expands use cases for audio and video recall and analysis, far beyond document-based LLM use cases. Multi-media is richer, longer and more complex. This is a big advance.
Gemini 1.5 Performance and Availability
Long context length would just be a parlor trick if the performance doesn’t hold up.
Here’s what Google’s benchmarks indicate: A Gemini “Pro” that’s an efficient equivalent to Gemini 1.0 Ultra, itself about a GPT-4-level model. Details show 1.5 Pro beats 1.0 Ultra overall but not uniformly. Throw in the massively increased context length and a future Ultra 1.5 AI model could finally surpass GPT-4 decisively.

If Gemini 1.5 lives up to what Google is describing, a caveat we need to make given Google’s history of over-promising demos, they finally released a world-beating AI model.
I won’t go further into performance claims, because of the above caveats and I’d like to try it for myself first, but if this holds up, this is what we were hoping for all along from Google Deep Mind. They have led in AI research for years, and it’s time to see that leadership show in their released products. From Bard to Gemini 1.5 Pro is not bad progress for 12 months!
Regarding availability, Gemini 1.5 is currently available in a ‘limited preview’ to developers and enterprise users:
Starting today, we’re offering a limited preview of 1.5 Pro to developers and enterprise customers via AI Studio and Vertex AI. Read more about this on our Google for Developers blog and Google Cloud blog.
I hope it will soon be available for the rest of us to try out, hopefully users will be able to use Gemini 1.5 Pro with 1 million token context on the free tier Google Gemini.
OpenAI Sora
OpenAI’s Sora is not just another 5-second video diffusion model. This model, like Dall-E in the image generation space, has raised the bar significantly for what it means to generate video from text. OpenAI says:
Sora is able to generate complex scenes with multiple characters, specific types of motion, and accurate details of the subject and background. The model understands not only what the user has asked for in the prompt, but also how those things exist in the physical world.
A written article cannot do justice to the video generations, they need to be seen to be believed. The 3D scene stability and consistency is remarkable and camera shots seamlessly move while maintaining integrity of the objects in the shot.

Examples of Sora capabilities on X: Video-to-video, changing weather or styles, extending them forward and backward in time, mixing two videos to transition one to another.
Sam Altman was generating videos on command on X on release day. Here is “a futuristic drone race at sunset on the planet mars.” And here is “A bicycle race on ocean with different animals as athletes riding the bicycles with drone camera view”
OpenAI’s online technical research blog post “Video generation models as world simulators” shows some of the results and a high-level explanation of their approach. Sora is a diffusion transformer model that gets inspiration from LLMs, where it uses patches instead of tokens:
At a high level, we turn videos into patches by first compressing videos into a lower-dimensional latent space, and subsequently decomposing the representation into spacetime patches.
Sora is trained on and subsequently generates videos within this compressed latent space. We also train a corresponding decoder model that maps generated latents back to pixel space.
The technical post mentions the model is a virtual world representation model. It has applicability to simulation and other uses beyond video generation.
While this AI model being so good is a surprise, OpenAI isn’t the only player in the AI video generation space. This raises the bar for current AI video generation leaders like Runway ML, and its another sign AI will surely change the way we create movies soon.
Sixty-second video shots from a single prompt can be done now, and longer high-quality results will come soon. Even full-length movies from AI are not far off.
Summary
Two different releases but a common theme: AI keeps getting better and at a very fast pace.
With Gemini 1.5 Pro, multi-modal AI models got better with vastly extended context windows. Video generation AI models got better with Sora’s more realistic and stable generation of consistent video.
AGI is closer than you think.