
The Best Ways to Run AI Locally
Jan, Ollama and OpenWebUI plus the latest Phi3 models open the way to great local LLM experiences.


It’s Time to Run LLMs Locally
What’s the best way to get a ChatGPT-level experience running LLMs locally?
We ideally would like a graphical chat interface for inference, possibly with voice input-output, running a good-quality LLM locally with decent response speed. It’s even better if we enable file import so we can interact with local files and data. The good news is we now can.
There are a plethora of awesome local AI interfaces and tools to run LLMs locally, thanks to a vibrant open source community that have been pioneering awesome local LLM solutions since ChatGPT burst on the scene 18 months ago.
This started with getting LLMs to run on CPUs with llama.cpp. To make LLM memory footprints smaller, LLM quantization methods were developed to reduce parameter weight precision down from 16 bits to 4, 5, 6 or 8 bits, trading off slight performance degradation for large memory reduction.
I wrote about Running your own AI models last September. I explained about llama.cpp, quantization, and local UIs to run LLMs. However, even then LLMs were either too big, too slow, or just not good enough to run locally and match best-in-class LLMs like GPT-4. At the time, I suggested running LLMs locally if you were a hacker, but added:
If you are an AI model user or consumer, even a power user, but don’t want to explore open AI models, then stick with OpenAI’s ChatGPT plus subscription. GPT-4 plus plug-ins and code interpreter remains best-in-class AI models for users.
This has changed: Smaller open-source AI models are getting really good. Phi-3 Medium, a14B model, is almost as good as Claude Sonnet, with an MMLU of 76. Just-released Mistral’s Codestral achieves over 81% on HumanEval for Python, making it a great CoPilot for coding (literally a drop-in replacement for Github CoPilot using Continue.dev).
The HuggingFace open leaderboard tells the tale: SOTA open AI model scores have been steadily improving over time.
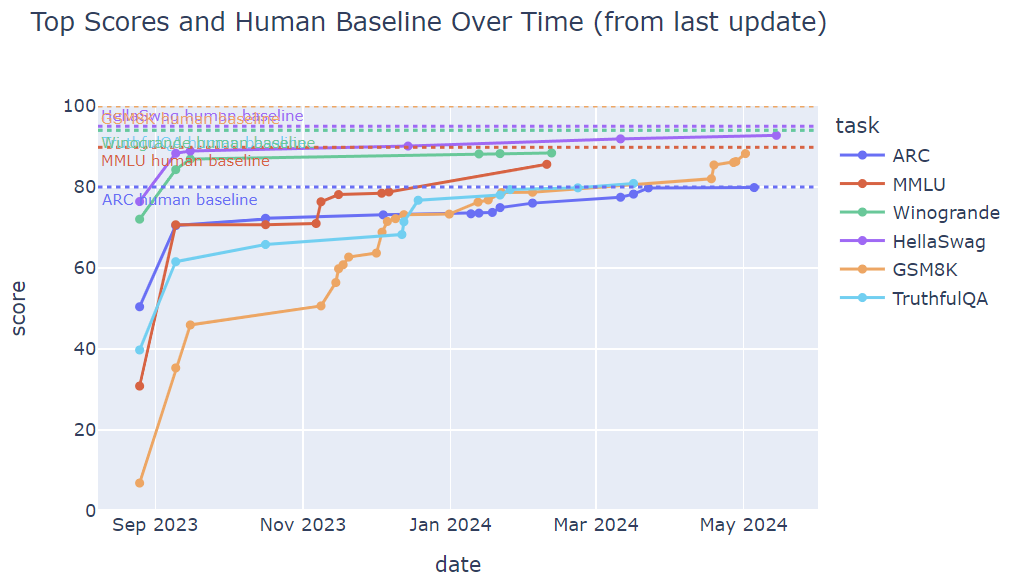
The bottom-line: Smaller open LLMs are good enough for real use. Now’s a good time to setup and run a local LLM, if you haven’t already.
Don’t Pay for Running LLMs
Putting aside local LLMs for a bit, there are alternatives for web-based running of LLMs. Proprietary frontier AI model builders offering their own chatbots: Google Gemini, ChatGPT, and Anthropic’s Claude. Other options including accessing GPT-4o via Microsoft Copilot, and Poe.com which lets you run anything.
Because there are so many free options and best-in-class models available for free tier access, there is rarely a need to pay for any of these, unless you are a heavy user needing specific AI models or interfaces. For example, you don’t even need to be a Chat-GPT+ subscriber now to get access to running GPTs, data analysis, and GPT-4o.
Setups to Run Local LLMs
With those options in mind, there is still good reason to run locally - for speed, privacy, and ability to interact with local data. There are two part to a system to run AI locally:
An LLM inference engine that runs and serves model inference on your local GPU or CPU. Tools like Ollama fill that role.
The interface used to access LLM inference, via either a CLI (command-line interface) or UI. The latter can connect to either local LLM inference or to external APIs. Interfaces like WebUI fill that role.
Some tools like LMStudio and Jan combine the two.
LMStudio
LM Studio is a vertically integrated desktop application to run LLMs locally, with both a server engine to serve LLMs and a graphical chatbot interface to interact with LLMs.
LMStudio is easy to download, setup and get started, and it’s available on Windows, macOS, and Linux. While not open-source, it’s free to download. It has access to a large number of LLMs, including quantized models in the GGUF format (llama.cpp).
It has some modular components: Lms is LMStudio's companion CLI tool. It also has its own "local LLM server" to serve LLM inference via an API server running on localhost, following OpenAI's API format.
My blocker issue with LMStudio is that it was slow to serve; Phi-3 medium was coming out at about 3 tokens a second - non-usable. It might be a configuration issue, but it acted like it knew about my available GPU (a 24GB RTX4090), and there was no apparent way to fix it. So it’s a pass for me.

Jan - Open Source Chatbot GUI
An open source alternative to LMStudio is Jan. It is not as feature-rich as LMStudio, but it does have a clean and elegant UI, living up to its intention of being a local ChatGPT substitute. Jan was also very easy to install, and I was able to set it up, download a Phi-3 medium model and run in minutes on Windows. (They offer it for MacOS and Linux as well.)
It has access to models both via API (you can enter API keys) as well as locally served models via “Multiple engine support (llama.cpp, TensorRT-LLM),” so it supports a variety of LLMs to serve.
Unlike LMStudio, Jan gave me fast LLM inference out of the box: Phi-3 medium at 50 tokens/sec, Llama 3 8B over 60 tokens/sec, Codestral 32 tokens/sec.
The models can be configured via the interface (temperature, system prompts). Jan also has the ability to set up a local server to serve models via a local OpenAI-compatible API. It has good documentation.
Jan is open source, which is is a bonus, as they are transparent in their code, features and roadmap. Jan’s interface lacks some features, like file upload for RAG-type applications, audio input-output, but those may be coming, as there is active development on it.

Ollama
My own personal go-to local LLM server is Ollama, and I’m not alone - it’s very popular, with 71,000 stars on Github. Ollama is a command-line desktop application that can run any GGUF-encoded models, including various LLMs like Llama 3, Mistral, and Phi, etc.
Ollama download and setup is fairly simple, on either Windows, Mac or Linux. From there, you operate Ollama from a command line or terminal. You can ‘pull’ models, list your downloaded models, and run models to interact with them directly in the command line to have a conversation:
$ ollama run phi3:medium-128k
>>> what is the capital of France?
The capital of France is Paris. It's known for its art, fashion, gastronomy and
culture. The city also boasts iconic landmarks like the Eiffel Tower, Louvre Museum, Notre-Dame Cathedral, and many more historical sites.Ollama runs a local LLM server to serve LLM inference in a REST API, that can be used within other AI applications. For example, to set up Codestral as a local Copilot, or set up a local version of Perplexity, Ollama is your server.
Since our goal is a full graphical interface, what we need is a front-end UI to Ollama. Fortunately, Ollama’s Github page has a Community Integrations section that lists dozens of such integrations: Open WebUI, Enchanted (macOS native), Hollama, Lollms-Webui, LibreChat, Bionic GPT, HTML UI, Saddle, Chatbot UI v2, etc.
Open WebUI
Open WebUI is a feature-rich web UI that provides local RAG integration, web browsing, voice input support, and much more. It supports various LLM runners, including Ollama and OpenAI-compatible APIs. Previously called ollama-webui, this project is developed by the Ollama team.
Open WebUI’s feature list is very long.
Installation is not as dead-simple as other tools mentioned. The standard way to install Open WebUI is as a docker instance, that you then connect with Ollama server. For myself, I went an alternative route: From my conda environment, I did a pip install of the web-ui package and then launched it with a command-line:
open-webui serveThen I went to my browser and plugged in http://0.0.0.0:8080 in the search bar to access open-webui.
Most additional features require setup and configuration via the settings panel, and the Open WebUI Documentation walks users through setting up various features: Image generation with Dall-E3 or Automatic1111 (StableDiffusion); audio input and output with Whisper; openAI API connections; personalization with memory, similar to that in ChatGPT.
One capability I was able to get running quickly was Open WebUI’s RAG system that can read a PDF, embed it and query it in an LLM. This feature is exactly what I’m looking for in local LLM inference, as I don’t want to send my local files to OpenAI to analyze.

Recommendations
With so many options out there to serve LLMs, many of them open-source projects, it can be confusing. I haven’t done justice to all the choices available, as many other good open-source projects with much to recommend. In the interest of time, thought, I just focused on a few prominent ones that worked well for me. So to answer the question:
What’s the best way to get a ChatGPT-level experience running LLMs locally?
Jan - Jan is simple and easy to install and use, with a clean ChatGPT-like interface, and supports a broad selection of models.
Ollama - Ollama is a great choice for your local LLM server. It’s popular for many reasons: It’s a well-supported flexible platform that serves a variety of LLMs efficiently, and is an active developed open-source project with a strong community.
Open WebUI - Pairing Open WebUI with Ollama is a good combination. OpenWebUI has a feature-rich interface that has all that I’ve been looking for in local LLM execution.
I found in my research that Vince Lam has a list of 50+ Open-Source Options for Running LLMs Locally. You can explore there further, but it turns out his own final recommendations closely match mine:
For UIs, I prefer Open WebUI for its professional, ChatGPT-like interface, or Lobe Chat for additional plugins. For those seeking a user-friendly desktop app akin to ChatGPT, Jan is my top recommendation. I use both Ollama and Jan for local LLM inference, depending on how I wish to interact with an LLM. - Vince Lam