


The DeepSeek Meltdown
Reacting to Wall Street's overreaction: DeepSeek R1 is a win for AI efficiency, open source and reinforcement learning. China isn't leading US, and US AI labs will meet this "Sputnik moment."


Wall Street Has a DeepSeek R1 Meltdown
In the week since it launched, reactions to DeepSeek R1 have gone into overdrive. While many of us predicted rapid advances in AI reasoning models, few expected an open source o1-level AI reasoning model to arise a mere month after the full o1 model release. This has clearly shaken some people up.
The reactions moved from amazement as more people realized how good the DeepSeek R1 model, into a freak-out over that a smaller Chinese AI lab could beat out US AI firms. Claims about DeepSeek needing only $5 million got repeated, and the story got more hyperbolic as the underdog R1 story got retold.
Then many on Wall Street figured that if the best AI models could be built without a boatload of GPUs, it might be bad for the biggest GPU seller. Nvidia stock got clobbered, sinking 17% on Monday and wiping a record-breaking $600 billion from the chipmaker's market value. It took much of the tech sector with it.
DeepSeek R1 has gone viral and so has the panic around what this release represents, presenting a need to separate wheat from chaff. So, here are six points to hopefully put things in proper perspective:
Yes, DeepSeek R1 (likely) only cost $5 million to train.
No, China is not beating USA in the AI race.
DeepSeek R1 is really a win for open source.
Wall Street overreacted by dumping on Nvidia.
Gemini 2.0 Flash Thinking is a better AI reasoning model.
Reinforcement Learning is a powerful force.
DeepSeek R1 Only Cost $5 Million to Train
Elon Musk and Alexandr Wang claimed that DeepSeek actually has 10,000 or even 50,000 GPUs, sharing numbers reported by Semi Analysis. We know that China is getting around export bans, so it’s possible.
However, it’s not out of the question to make a GPT-4-level AI model for a modest amount of money: Databricks spent $10M on new DBRX generative AI model, a 130B MoE model trained in early 2024 that performed close but not at GPT-4 levels.
DeepSeek V3 is their third generation, and they learned from prior iterations how to make training more efficient.
Emad Mostaque confirmed that the DeepSeek AI training run could be done in $5 million, showing the math that 15T tokens of pretraining takes 3 x 10^24 FLOPs, which can be done in 844 hours on a cluster of 2048 H800s, at the $5 million cost DeepSeek reported:
It’s pretty much in line with what you’d expect given the data, structure, active parameters and other elements and other models trained by other people. You can run it independently at the same cost.
While the training of the DeepSeek V3 itself was likely done in $5 million, it’s also likely that testing iterations were done outside that budget to evaluate algorithms and set up training runs. While it was an impressive achievement of training efficiency, it was based on learning about training from their own experience and what other AI labs did.
Emad also mentions how this AI model training is reproducible:
Given 2.8m H100 hours and a month or two of set up I am confident I can build a similar model.
Other AI labs will be able to train R1-like AI models with similar efficiency.
China is not Beating USA in the AI Race
While DeepSeek R1 is a great AI model and this is a great achievement, some reactions to R1 got carried away.
There have been claims that DeepSeek is a CCP Psyops. No, DeepSeek is a quiet but effective AI Lab that spun off from a Chinese quant trading firm a few years ago. Nor is DeepSeek a “Mom and Pop” operation. The DeepSeek team is close to 200 people, a significant talent pool, albeit smaller than Meta, OpenAI and Google DeepMind teams.
The worst take on DeepSeek R1 is claiming that “China figured out how to train models without GPUs.” No, they didn't. While $5 million is a relatively small budget, DeepSeek used significant resources to pull this off and have significant GPUs at their disposal.
Claims that “China has leap ahead” also don’t make sense. DeepSeek is a fast-follower that reverse-engineered what OpenAI did. US AI firms have been ahead but never years ahead, and the followers have been able to replicate what the leading AI labs do, typically in 6 to 12 months.
China AI labs have made many good AI models already, including SOTA image generation and video generation models, and Qwen 2.5 excellent LLMs. DeepSeek has been gradually making increasingly better AI models over the last two years. DeepSeek R1 itself was a surprise, but it’s not a great surprise that DeepSeek team developed a great AI model.
All this is to say that China is not leading, but they are highly capable and competitive.
DeepSeek R1 is a Win for Open Source
The “China is beating USA” is missing the bigger picture: DeepSeek R1 is a win for open source, not China.
DeepSeek R1 is a replication of o1, that is by itself not more noteworthy than Qwen QWQ and Google Gemini 2.0 Flash Thinking. DeepSeek R1 went viral because they released an open-source model and made it as easy as possible to use and replicate it.
Some have criticized their release as not open. Percy Laing notes:
While we celebrate @deepseek_ai's release of open-weight models that we can all play with at home, just a friendly reminder that they are not *open-source*; there’s no training / data processing code, and hardly any information about the data.
While many AI labs loosely use “open source” to describe open weights AI models that are not fully open, DeepSeek R1 is more open than most ‘open’ AI models.
DeepSeek R1 is released under the MIT license, which allows unhindered use of the AI model. This is more open than most open AI models, including the open weights AI models from Meta or Qwen. Only the AI2 Olmo AI models have gone as far as sharing training code and data, what they called “fully open” LLMs.
DeepSeek didn’t share their data, but they did share many technical details in their Technical Report. DeepSeek explained the R1 training pipeline, presenting a clean RL process to train an AI reasoning model. Publishing how DeepSeek R1 was trained is most important because it’s the guidance for others to reproduce their work, which will accelerate AI progress.
Wall Street Overreacted by Dumping on Nvidia
Wall Street’s overreaction to the DeepSeek news was based on misunderstanding the implications of DeepSeek’s achievement.
DeepSeek R1 presents a big challenge to OpenAI and Anthropic. They cannot afford to spend hundreds of millions of dollars training their next-generation AI model, only to have to compete with an open-source AI model that costs pennies to run and can be downloaded and reused.
However, the DeepSeek news doesn’t justify dumping on Nvidia. The assumption that a great new AI model will reduce demand for AI chips because it was trained efficiently makes little sense.
There’s an informed short case on Nvidia. It’s a long read, but the summary is that the Nvidia chip and software (CUDA) moat are under long-term threat, while DeepSeek’s release shows AI infrastructure provisioning might be too large. Both are arguable, but that is what makes a market.
The bull case for Nvidia is that AI demand will go up as more efficiency and performance unlocks more use cases. DeepSeek used Nvidia GPUs to train their model and even if their training is more efficient, the long game on Nvidia GPUs is scaling data centers for AI inference and GPU edge-devices (Project Digits, self-driving cars, and AI robots).
Nvidia put out a statement praising DeepSeek, while declaring scaling is continuing:
DeepSeek is an excellent AI advancement and a perfect example of Test Time Scaling. DeepSeek’s work illustrates how new models can be created using that technique, leveraging widely available models and compute that is fully export control compliant. Inference requires significant numbers of NVIDIA GPUs and high-performance networking. We now have three scaling laws: pre-training and post-training, which continue, and new test-time scaling.
More AI efficiency means more AI demand. Jevons paradox has gotten a lot of mentions, including from Satya Nadella:
Jevons paradox strikes again! As AI gets more efficient and accessible, we will see its use skyrocket, turning it into a commodity we just can't get enough of.
The more compute efficient AI gets, the more use cases start becoming economically viable, the more we'll deploy AI, and the more compute we'll need.
Gemini 2.0 Flash Thinking is a Better AI Reasoning Model
How fares the US AI lab competition right now? The freakout about R1 is discounting how much is going on at the US AI labs.
The China is crushing US rhetoric totally forgets about Gemini 2.0 Flash Thinking. Likely cheaper, longer context and better on reasoning.
He shares a chart that shows Gemini 2.0 Flash Thinking is actually beating DeepSeek R1.
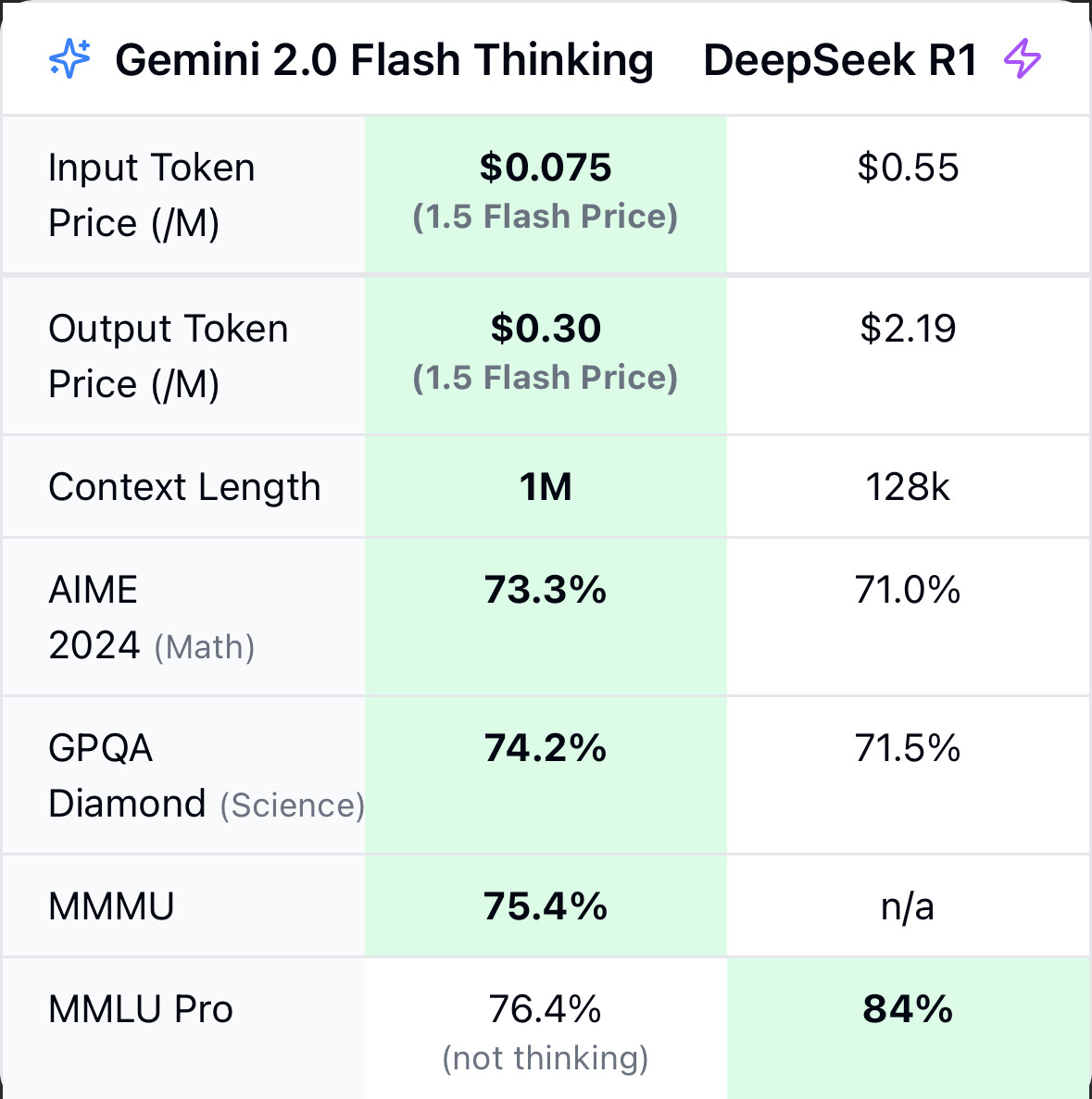
Google 2.0 Flash Thinking 1-21 gets less attention because it’s not open-source and it’s not surprising that a leader released a leading AI model. Yet it’s a shockingly good AI model.
OpenAI will soon release the o3 model, the best AI reasoning model yet.
Chubby says that Meta is the biggest loser here, saying that Meta’s Llama 4 is reportedly underwhelming, and they are scrambling. However, other AI labs are reportedly having similar issues with pre-training of next-generation AI models.
Meta has the opportunity to build the world’s best open AI models by extending what DeepSeek R1 did both in pre-training (a better base model) and in RL post-training (a better reasoning model). They can also beat out others through their advantage in multi-modality.
If this is a “Sputnik moment” like Marc Andreessen said, then it’s good that US AI labs are scrambling. It means the AI labs are rising to meet the challenge. Don’t count them out.
Reinforcement Learning is a Powerful Force
Andre Karpathy shares his thoughts on DeepSeek R1/ He points out not the power of China or of open source, but the power of reinforcement learning to making the magic of DeepSeek R1 happen:
There are two major types of learning, in both children and in deep learning. There is 1) imitation learning (watch and repeat, i.e., pretraining, supervised finetuning), and 2) trial-and-error learning (reinforcement learning). My favorite simple example is AlphaGo - 1) is learning by imitating expert players, 2) is reinforcement learning to win the game. Almost every single shocking result of deep learning, and the source of all *magic* is always 2. 2 is significantly more powerful. 2 is what surprises you. 2 is when the paddle learns to hit the ball behind the blocks in Breakout. 2 is when AlphaGo beats even Lee Sedol.
And 2 is the "aha moment" when the DeepSeek (or o1 etc.) discovers that it works well to re-evaluate your assumptions, backtrack, try something else, etc. It's the solving strategies you see this model use in its chain of thought. It's how it goes back and forth thinking to itself. These thoughts are *emergent* (!!!) and this is actually seriously incredible, impressive, and new (as in publicly available and documented etc.).
The model could never learn this with 1 (by imitation), because the cognition of the model and the cognition of the human labeler is different. Humans would never know to correctly annotate these kinds of solving strategies and what they should even look like. They have to be discovered during reinforcement learning as empirically and statistically useful towards a final outcome.
Conclusion – Winners and Losers
DeepSeek R1 is a major release, and it has ‘gone viral’ in multiple ways, causing something of a panic about the state of AI in the US.
While this release shows the prowess of Chinese AI labs, the China versus US angle misses the real story: There is no moat. Open-source fast followers can compete quickly and well. Leading AI labs must constantly innovate and improve. The fastest innovators will win the AI race.
There are no permanent winners and permanent losers among the AI Labs - yet. The competition in the AI world is fierce, and those that are behind today have the opportunity to catch up.
Another lesson of DeepSeek R1 is the power of reinforcement learning. Whoever makes it first to the AGI milestone, they will use reinforcement learning to make it happen.
DeepSeek R1 confirms that AI progress is rapid. Greater efficiency in AI use is not bad news for Nvidia; demand will grow, and scaling will continue. However, it’s a reminder that no tech company can rest easy, including Nvidia, for all things in AI change quickly.