
The Rabbit and the LAM
Are Large Action Models powering AI Agents the GOAT?


Natural Language as the Interface
There was a lot of excitement around the Rabbit at CES. What was shared in the Rabbit demo was a primitive device, with a walkie-talkie voice interface and a scroll wheel that looked like an etch-a-sketch-like child’s toy. Why the excitement?
I believe the excitement is centered around the birth of a new interface paradigm : Natural language. What impressed people was seeing an interface that was so useful yet so simple, it could change how we interact with all our applications. And it’s based on the most natural interface we have, our own natural human language.
How do you define user intentions? This has been the subject of human-computer interfaces (HCI) and user experience design (UX). The earliest primary interface to direct computer applications was the command-line interface. The emergence of the graphical user interface (GUI) in the 1980s opened up a much easier manner of conveying user intention, pointing and clicking with a mouse. Browsers extended GUI concepts to access internet services, while touch screens on smart phones and lap tops made the interface even more seamless.
Using AI to understand human language directly gives us the most seamless way to convey human intention. Typing works, but humans aren’t natural typists; pointing and clicking and tapping on phones are acquired skills, but we are natural talkers. We want to interact with our computer apps and online services by talking to them.
Bill Gates has called generative AI the biggest innovation in interfaces since the GUI for this reason.

Large Action Model (LAM)
“the (Large) Action Model, or LAM, emphasizes our commitment to better understand actions, specifically human intentions expressed through actions on computers and, by extension, in the physical world.” - Rabbit Research document
If natural language is the interface, then the primary question is: How do you turn language into intention?
For conversational chatbots based on LLMs, turning language into intention is easy: You can fine-tune the LLM to respond to any user question or instruction with an answer or response, hopefully one that is helpful, harmless, aligned and factually correct.
When it comes to more complex applications than question-answering, such as converting language into another mode, or getting the AI model to perform complex actions as an agent, it’s not so easy. How do you make natural language work as an interface to complex computer applications? Including web applications and services?
This is where a LAM comes in. A LAM (Large Action Model) understands human intentions on computers. When you use an application by clicking and moving a mouse, entering text in specific fields, or entering inputs on a command line, you make the computer do specific actions based on intentions and specific actions on the computer. LAMs are designed to understand such actions and invoke them when instructed.
LAMs connect the natural language world to the GUI world. As Rabbit tech report authors put it:
“LAM can be seen as a bridge, connecting users to these services through the application's interface.” - Rabbit research document
AI Agents for Web Tasks
Rabbit is an early-stage startup, so it is both surprising and helpful that they took the time to publicly share their research findings in a research document. Titled “Learning human actions on computer applications” and posted on their website in early December, it discusses their approach to Large Action Models (LAMs) that can learn web interactions and prior work in the area.
Web interface tasks are a large, complex, and varied subset of real-world GUI interface interactions. Thus, while getting an AI agent to understand browser-based web interactions and execute tasks is a hard problem, if you can solve that, you can automate most interactions on a computer.
The research cites prior approaches to automating web interactions and mentions two main approaches to the challenge:
Web automation and robotic process automation approaches use symbolic algorithms that to learn to extract data by example. These would infer a program to extract desired data from examples. While it works in specific domains, it can be hard to generalize.
Neural-net based approaches create or fine-tune a model to take either rasterized graphics or web text (HTML) as input, comprehend the web information, and then reason towards an action or response. The rise of LLMs adds a lot more power behind this approach.
An example of the latter would be the paper “Understanding HTML with Large Language Models,” which fine-tuned LLMs to create specialized LLMs for specific tasks of autonomous web navigation, description generation, and semantic classification.
The paper “HeaP: Hierarchical Policies for Web Actions using LLMs” also looked at leveraging LLMs for this problem. The authors observed that web interfaces are large, complex, and varied, and thus the solution is to decompose complex web interactions into sub-tasks, which can be handled by low-level policies. They show that hierarchical methods “outperform prior works using orders of magnitude less data.”
Rabbit points out:
Both sides advocate for a hybrid approach, which involves combining a neural component and a symbolic component
This hybrid approach is called “neuro-symbolic” and combines neural-net and structured symbolic methods together. They cite prior work that pursues this approach: “Web question answering with neurosymbolic program synthesis.”
Rabbit’s approach combines various elements of these prior works to develop their own neuro-symbolic approach to web understanding.
By utilizing neuro-symbolic techniques in the loop, LAM sits on the very frontier of interdisciplinary scientific research in language modeling (LM), programming languages (PL), and formal methods (FM). … by putting together neural techniques (such as LLM) and symbolic ones, one ends up combining the best parts of both worlds, making the task of creating scalable and explainable learning agents a feasible one. Yet to date, no one has put cutting-edge neuro-symbolic techniques into production — LAM seeks to pioneer this direction.” - Rabbit research document
About Rabbit’s LAM
Since they have not released a real product, we should caveat that this description is solely from non-peer-reviewed research claims, and it’s unclear how well this will work in practice. That said, there’s a few basic points about how the LAM works:
The LAM does not need an API to connect to a tool or service; it learns it directly from the web behavior and actions. This is different from the plug-ins that OpenAI has connected to GPT-4.
LAM learns actions by demonstration. “LAM's modeling approach is rooted in imitation, or learning by demonstration.” This is similar to Imitation Learning that is often used in robotics; train it on a sequence of actions and then it learns it as a script or a skill that can be called upon repeatedly for similar tasks.

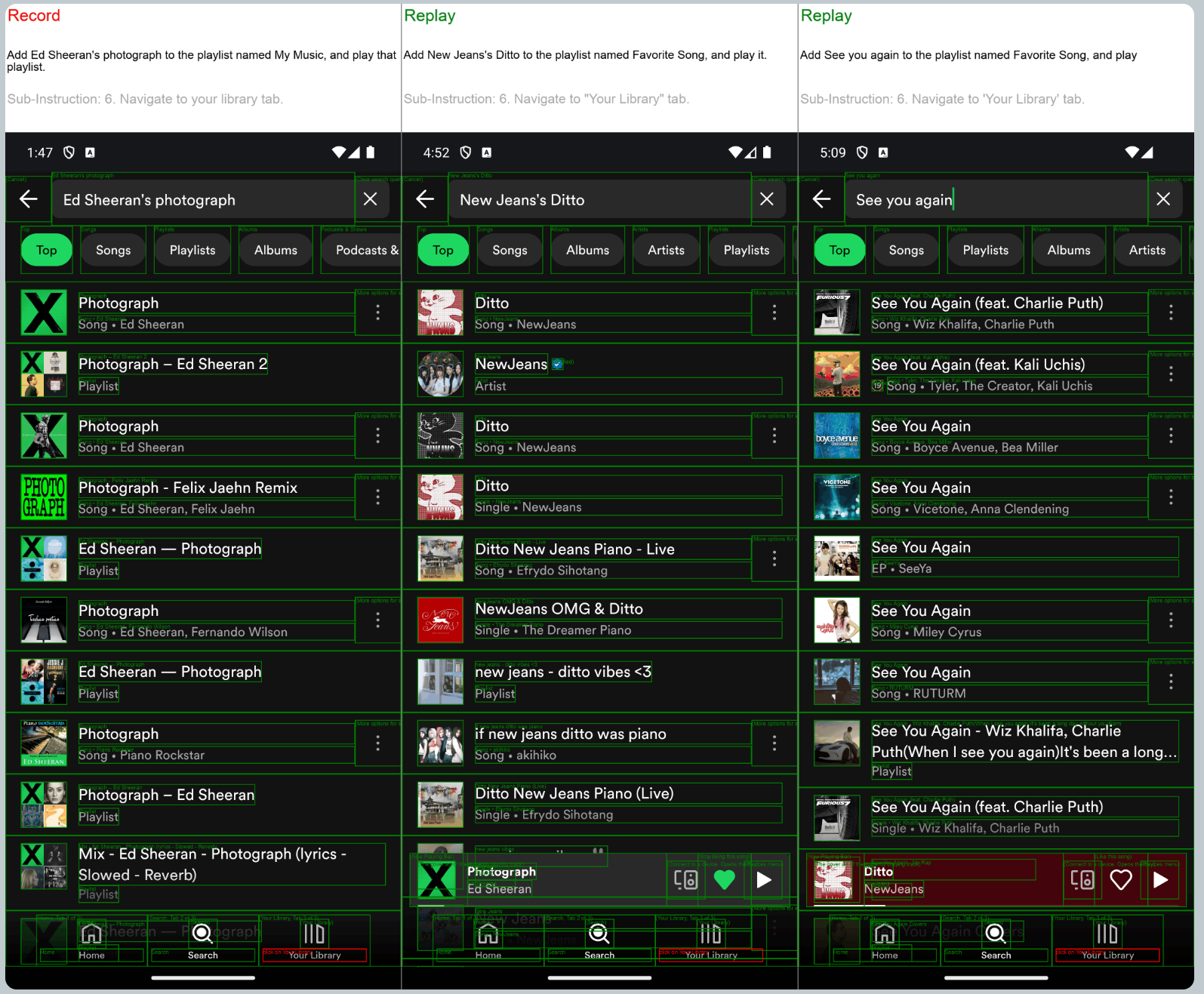
Figure. LAM recording and replaying web interactions on Spotify. The LAM understands websites visually and graphically. An MLLM (Multi-modal Large Language Model) akin to GPT-4 vision or another form of vision model is used to comprehend the browser or application interface.
The LAM has some understanding of hierarchy, so that they can “define and model complex application structures, beyond simple token sequences, from first principles.”
How does the LAM encode actions? In the symbolic approach, the actions are encoded as a program that declares a sequence of operations or steps. They reference a paper called Ringer that “creates a script that interacts with the page as a user would.” They apparently do something similarly, but specifics are not stated.
The LAM runs in the cloud. This is not done locally on the device, which is used solely for interface. This has benefits in that the edge device is simpler and lower-cost and the LAM itself can be run efficiently on cloud services. On the other hand, there may be issues with latency and control.
Summary
The Rabbit is an interesting and potentially innovative device due to be out this Easter. The excitement around it is due to the power of a human language (voice) interface powered by the LAM, Large Action Model.
The LAM automates complex web-based application tasks by creating a direct path from human intention through language direction to actions on computer applications. The LAM understands applications visually, so doesn’t need an API to work.
The concepts behind the LAM is not limited to just the Rabbit, but we are seeing similar concepts to the LAM applied to other AI agent applications. AI Agents such as Multi-On likewise are using LAM-type AI models to directly interpreting web interfaces and invoke actions; projects like open interpreter are using LLMs to invoke actions on computers.
If the real secret sauce of the Rabbit is the LAM, and the LAM is a software component, then it begs a few questions:
Does the hardware matter? Is it really necessary to ditch the smartphone? What if Apple wows us with turning Siri into a LAM-enabled software interface? Would that be enough?
If the most natural interaction is voice, what is the most natural hardware for the most natural interaction mode? For voice, I would think it is some kind of a headset, enabled with microphone and earbuds or near-ear speakers, plus a display and cameras for real-world understanding. That combination lends itself to AR/VR glasses as a hardware embodiment.
Action is one mode of operation, so would the larger interface be a Suite of AI models on demand, and you tap into a specific one, depending on your need? A user could tap into a plethora of AI models in the same system: A fact-based answer engine; a friendly chatbot companion; a LAM-based Action-model Assistant; a data analytics assistant, etc.
Consumer choices are unpredictable, so what hardware form-factor ‘wins’ remains to be seen. While Rabbit as a hardware form-factor is interesting, it is the LAM that will be the important and enduring part of Rabbit, needed to bridge the gap between language and computer-based actions.