
This week in AI 23.04.08
SAM, HuggingGPT, BloombergGPT, and the power of LLMs in-the-loop.


AI Tech and Product Releases
Meta Releases SAM - Segment Anything Now, that can identify and segment items in images and videos in real-time. You can quickly identify and then manipulate semantically those image representations. This capability is groundbreaking for Augmented Reality, but even more useful in robotics, helping robots understand their environment. Embodied multi-modal intelligence for robots is not far behind LLMs, and the combination will be truly powerful.
Microsoft Jarvis aka HuggingGPT on github was presented in a paper recently. This is a way to manage multiple execution APIs and models with an LLM, a capability that super-charges the LLM:
Specifically, we use ChatGPT to conduct task planning when receiving a user request, select models according to their function descriptions available in Hugging Face, execute each subtask with the selected AI model, and summarize the response according to the execution result.

Related to this, Microsoft open-sourced Semantic Kernel, a toolkit for integration of LLMs with conventional programming languages. “developers can infuse their applications with complex skills like prompt chaining, recursive reasoning, summarization, zero/few-shot learning, contextual memory, long-term memory, embeddings, semantic indexing, planning, and accessing external knowledge stores.”
Bloomberg announces BloombergGPT, a 50B parameter LLM for finance, which “has been specifically trained on a wide range of financial data to support a diverse set of natural language processing (NLP) tasks within the financial industry.” We will see if vertical-specific AI becomes a ‘thing’. One impressive data point is they pulled from Bloomberg’s own financial data archives “to create a comprehensive 363 billion token dataset consisting of English financial documents.” If Bloomberg can find that much data just in public financial records, it suggests the amount of document data usable for training LLMs is far from untapped, perhaps in the 10s of trillions of tokens.
There’s been a more development of small LLMs models following-up on Alpaca’s LLaMA-based 7B model:
LLaMA model modified to run on your own PC - LLaMA.cpp, then extended with this chat UI github project: “Alpaca-Turbo: A Fast and Configurable Language Model-Based Chat UI and API.”
Berkeley AI Research announced “Koala: A Dialogue Model for Academic Research”, a 13B model trained by fine-tuning LLaMA 13B on high-quality dialog data. One learning from that was that quality of the dialog matters more than quantity in getting model improvement.
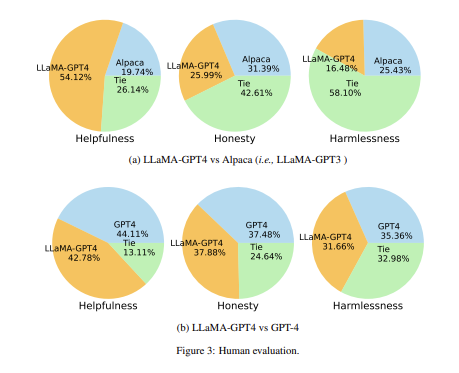
“Instruction Tuning with GPT-4” starts with a 7B LLaMA-based model, then uses GPT-4 to generate 52K instruction-following prompt data points for LLM fine-tuning. This “LLaMA-GPT4-7B”result shows improved performance vs Alpaca, in some cases close to GPT-4 level based on human eval. There is a github for data and code, but suspiciously the github prompt data was taken down, maybe due to questions around the legality of using GPT-4 outputs.

Many LLM-based useful tools cropping up, one of them is Unriddle.ai: Read PDFs, then interact and query your documents using GPT-4. Very useful. I’ve also found that Bing Chat can summarize online PDF links such as Arxiv papers.
AI Research News
“Self-Refine: Iterative Refinement with Self-Feedback” introduces a framework that improves initial outputs from LLMs through iterative feedback and refinement. The main idea is to allow the same model to provide multi-aspect feedback on its own output, and then use that feedback to refine the output. They showed up to 20% improvement on GPT-4 output results using this method.

Another recent paper looking at feedback methods to improve LLMs is “REFINER: Reasoning Feedback on Intermediate Representations.” It proposes a new feedback method that using a “critic model”to provide fine-grained feedback on intermediate representations of model responses. Their method improves performance on several tasks vs a GPT-3.5+CoT model baseline. See workflow below.

As my son once joked, if we achieve Artificial Intelligence, does that mean we’ll have Artificial Stupidity too? Well, yes. “Humans in Humans Out: On GPT Converging Toward Common Sense in both Success and Failure” looks at how advanced LLMs are are picking up human flaws:
Remarkably, the production of human-like fallacious judgments increased from 18% in GPT-3 to 33% in GPT-3.5 and 34% in GPT-4. This suggests that larger and more advanced LLMs may develop a tendency toward more human-like mistakes, as relevant thought patterns are inherent in human-produced training data.
AI Business News
Google announced their new T4 AI chips claiming they are “1.2x-1.7x faster and uses 1.3x-1.9x less power than the Nvidia A100.” Oops! That was the last generation of NVidia chips. Still, this is powerful.
China's Alibaba invites businesses to trial AI chatbot. This article mentions other Chinese players in the AI race: Huawei Technologies is unveiling Pangu, Baidu’s ErnieBot is in limited release, and SenseTime is set to make an AI product announcement next week. China isn’t standing still.
TechCrunch reports on Anthropic’s $5B, 4-year plan to take on OpenAI to compete with OpenAI on what they call Frontier Models, the next-generation of AI models:
It plans to build a “frontier model” — tentatively called “Claude-Next” — 10 times more capable than today’s most powerful AI, but that this will require a billion dollars in spending over the next 18 months. …
Anthropic estimates its frontier model will require on the order of 10^25 FLOPs, or floating point operations … it relies on clusters with “tens of thousands of GPUs.”
Anthropic will use their approach to Constitutional AI to build this model. It was noted that Anthropic.
A side note on the scale and cost of model building: Looking at the 2022 Chinchilla paper estimate of compute optimal models, a ~10^25 FLOP model would be trained on 13 Trillion tokens of data and could around 500B parameters. With each H100 capable of 2 petaflops of AI compute, it would take 25,000 H100 GPUs about 70 days to compute the ~10^10 petaflops to train this model. Hardware cost alone for that is hundreds of millions of dollars, with NVidia H100s costing over $30,000 each.
“These models could begin to automate large portions of the economy … We believe that companies that train the best 2025/26 models will be too far ahead for anyone to catch up in subsequent cycles.” - Anthropic Pitch Deck
AI Opinions and Articles
The future that AI predicts: Someone asked ChatGPT, and got “a chilling glimpse into the horrors that await us in the 2030s.” It was the kind of conventional doomer predictions you’d expect from a Reddit thread, which it probably how this “GPT-3 in a Sarcastic and Ominous style” picked up this verbiage in its training. As we said above - Human In, Human out.
A Look Back …
OpenAI was created 7 years ago as a non-profit open source research organization with a bold goal aiming towards AGI. Elon Musk was worried that Google’s dominance in AI might lead to a monopoly in AI (perhaps wanting open source AI so his self-driving car efforts wouldn’t be hampered). Now, OpenAI is closed and in Microsoft’s orbit - “Not what I intended at all,” says Elon.
