
Truth-Grounding AI Models with Vector Databases
Adding memory and knowledge context to LLMs


Let’s be clear: Language models are not knowledge models. Today’s most powerful LLMs gets their representation of the world from training on trillions of words of text. This yields many capabilities in understanding and knowledge embedded in their learning. It can spit out wikipedia-level understanding of many facts, concepts, events, and more. However, that understanding of the world is approximate, statistical, and inferential. Inferential processes in that AI can sometimes fail in the same way that humans fail, suggesting some shared flaws in reasoning.
“Many experts have pointed out that the accuracy and quality of the output produced by language models such as ChatGPT are not trustworthy. The generated text can sometimes be biased, limited or inaccurate.”
The above quote came from this article on “The best AI tools to power your academic research.” AI can be useful, but we need to overcome or avoid its traps and flaws.
chatGPT Flunks Math
As Amazing as the latest LLMs like chatGPT and GPT-4 are in some domains, they still fall flat on some surprising simple fact-based challenges. Let’s start with chatGPT making a hash out of a math question.

I’m kind of shocked that chatGPT did even close to well on any kind of standardized tests when it makes such a hash out of this simple request: What is 965x95? Correct answer: 56,935. Not only did it get the final answer wrong, but the ‘show your work’ is just fantasy. It’s like a student who has no clue of the real answer and hand-waves to imitate what he thinks looks impressive.
GPT-4 does better on these kinds of problems, but not great. Bing chat (GPT-4-based) gave the correct final answer but had incorrect ‘show your work’.

“They (Large Language Models) have these (reasoning) capabilities, but they are not reliable. Unreliability makes them less useful, but with more research, they will be much more reliable as well. GPT-4 does not have built-in retrieval, it will get better with retrieval.” - Ilya Sutskever
Why does it do so badly? It was built to predict the next likely token, not the ground-truth.
Many flaws stem from the LLMs reliance on a large body of text, treating words as tokens, and predicting the next token as its underlying skill. Aside from tripping up on simple arithmetic, word puzzles involving letters (like palindromes, Wordle, or crossword puzzles) are also a challenge.
LLMs can also be found hallucinating facts, getting confused about contexts, or losing track of where it started. It yields lack of certain knowledge; weaknesses in reasoning; and unreliability. Bottom line: LLMs need an assist in knowing specifics about the world.
How to Ground LLMs in Truth and Knowledge
To fix hallucinations and bad math and ground LLMs in truth better, several approaches can be used separately or in combination:
Connect LLMs to relevant knowledge as context: Use retrieval augmented generation and vector databases.
Give LLMs a change to iterate to revise their answer: Prompt for "step-by-step” or chain-of-thought reasoning, or review, critique and revise the LLM response iteratively.
Give the LLM access to a tool to answer or calculate directly: Using ChatGPT plugs-ins, HuggingGPT or LangChain to connect AI tools.
Safe approach - only say what you can verifiably know to be true: PerplexityAI approach.
Knowledge Contexts with RAG and Vector Databases
This most direct way to avoid an LLM from hallucinating is to get the proper knowledge context into the LLM prompt. Microsoft Bing Chat has adopted the approach of doing a Bing search and then providing those results into the GPT-4 context window to process their final and hopefully more accurate response.
Microsoft CoPilot for Word uses a similar approach but with local data, grabbing its context from the word document you are writing itself.
The generalized way to grab that knowledge and make it available to LLMs is with Retrieval Augmented Generation (RAG). RAG performs information retrieval then feeds that relevant knowledge context to the generation process. We retrieve relevant information from our desired knowledge base (e.g., it could be from wikipedia, your local files and emails, domain-specific knowledge repo etc.) and feed this information into the generation model as a secondary source of information.
How do we efficiently find an include relevant information and context? Use vector databases. Vector databases store their information in vectors that represents the words, phrases and sentences of the documents. They capture in some sense the meaning behind our words and text, because of how vector representations are a representation of word, sentence and larger text meanings.
Representing text as vectors matches the ‘native representation’ of the LLM, and the vector database can be thought of as the external long-term memory of our LLM.
Vector database solutions including the leading company Pinecone and the open-source solutions Milvus, Weaviate and several others.
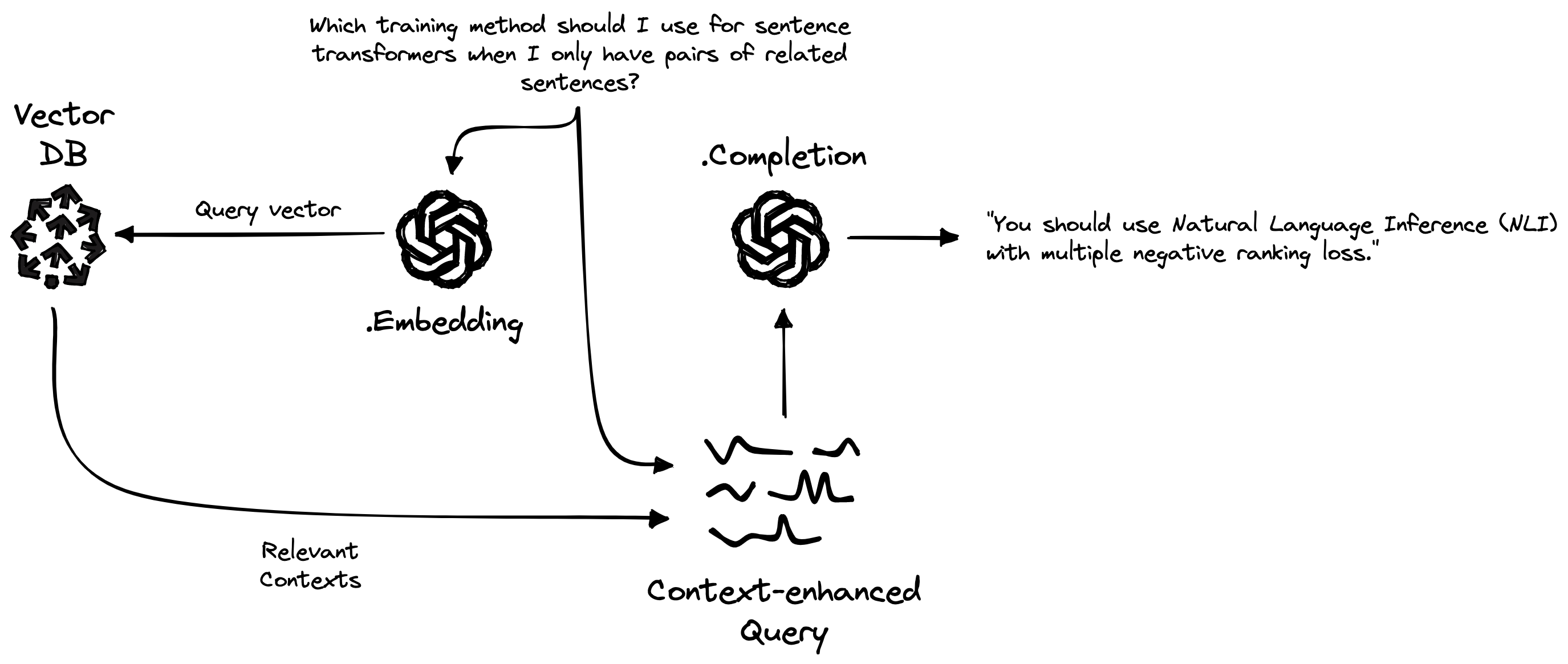
Pinecone’s “Generative Question-Answering with Long-Term Memory” explains how to put these pieces together to create factual grounding in LLM query responses:
Store your full knowledge domain in your Vector DB.
Intercept any query to the Embedding LLM and convert it into semantic similarity query on the Vector DB.
The VectorDB will return the Relevant Contexts. Add those to the original query to make a Context-Enhanced Query.
Perform a completion by querying the LLM with the Context-Enhanced Query to generate a Completion.
You can also use Pinecone and LangChain it to maintain conversational context memory.
Supercharging LLMs
Language models by themselves have many limitations, but pair language models with knowledge bases and you have far more reliable ground-truth-based models that can answer specific fact-based queries. For example, tis would be the path to AI models good enough to be relied upon for healthcare condition diagnosis.
In followups articles, we will discuss further the other approaches to improving AI model results: Iterative refinement of the LLM response to a query; and use of specialized tools and plug-ins to answer specific queries. Combined, these three different approaches will advance the state-of-the-art results of the best AI models, so we will see a lot of use of them
PostScript: Augmenting LLMs with Memory, A Theory Result
This is a theoretical computing result, but it tells us that we are getting in the territory of a complete solution with memory-augmented AI models. In “Memory Augmented Large Language Models are Computationally Universal”, it is shown that LLMs with memory are Turing-complete:
We show that transformer-based large language models are computationally universal when augmented with an external memory. Any deterministic language model that conditions on strings of bounded length is equivalent to a finite automaton, hence computationally limited.
A ‘Turing-complete’ problem is the hardest problem there is; it basically means that if it can solve this problem, it can solve any problem.