


AI Engineer World's Fair pt 2: Models, Training and AI Code Assistants
Models, LLM Training and fine-tuning, & AI Code Assistants. Github Copilot, Codeium, Cursor, Cody, Q.

World’s Fair Debrief Part Two
This is part two of my review of the AI Engineer World’s Fair, you can find part one here.
As a conference for AI builders, a main thrust of the conference was on the AI models, frameworks and tools to help AI builders create great AI applications. In this article, we will cover: AI models, both frontier models and open AI models; LLM training and fine-tuning; and AI coding assistants.
Frontier AI Models
“We are still in early innings of that [AI] transition” - Roman Huet, OpenAI
Alex Albert of Anthropic gave a presentation on Claude 3.5 Sonnet and the recent Anthropic features, Artifacts and Projects. He touted Claude 3.5 Sonnet’s 200k context, top metrics, pull request eval pass rates, SOTA vision capabilities, and economy. It’s only $3 per million tokens input, $15 per million tokens output, a fraction of what GPT-4o costs.
He showed off how Artifacts and Projects are moving AI models beyond the chatbot interface. Anthropic’s future releases this year include Haiku and Opus versions of Claude 3.5, as well as interpretability and a Beta steering API for steering the output without prompting.

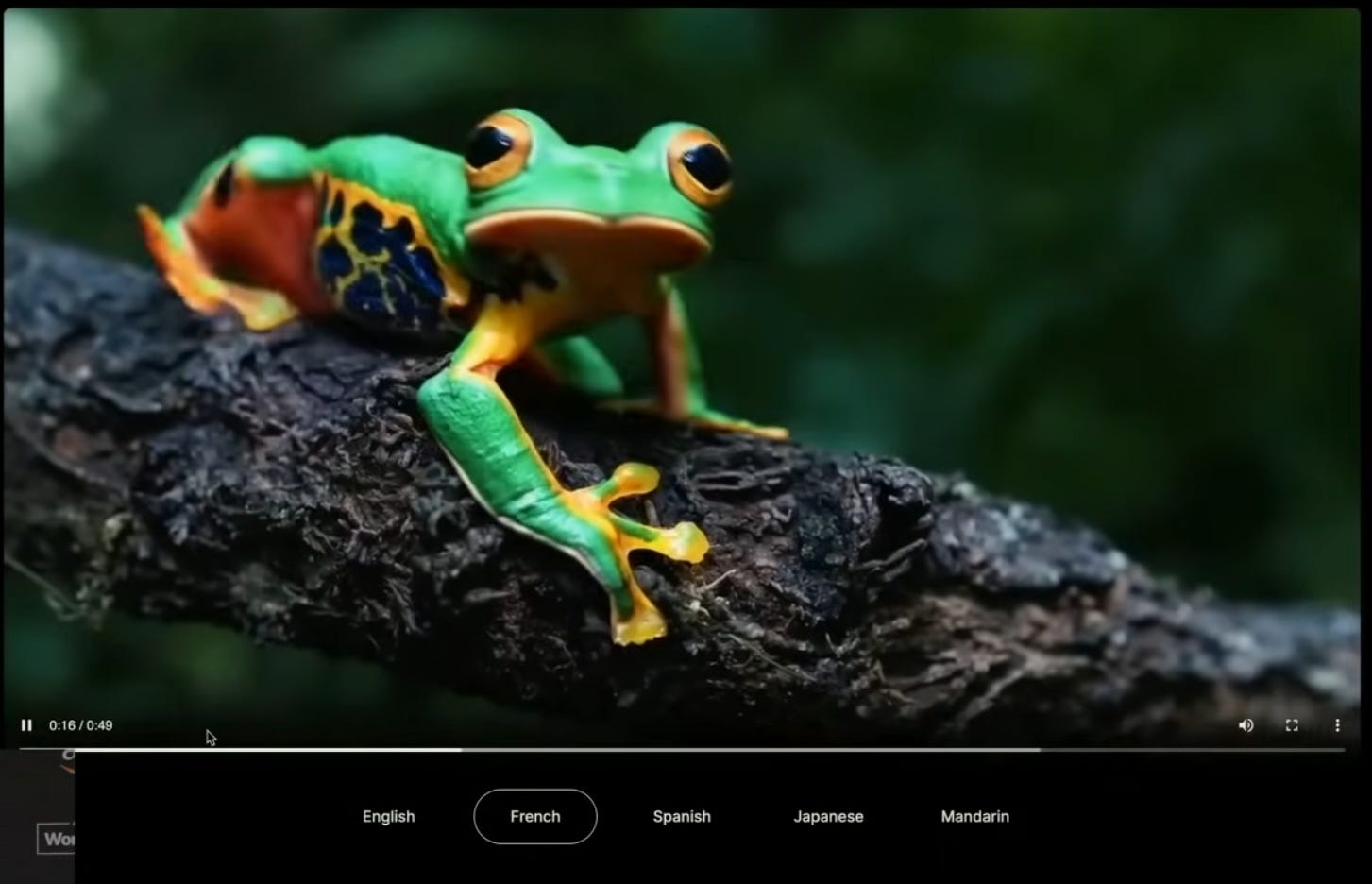
Roman Huet of Open AI gave a great GPT-4o demo, although we’ve seen most of it in great prior demos of Sora and GPT-4o. He showed off GPT-4o’s multi-modal features through voice mode ChatGPT: Recognizing a drawing of the Golden Gate bridge; summarizing a page from a Charlie Munger book just by looking at its image; and using voice to narrate a Sora-made video, then showing off voiceovers instantly translated into multiple languages (see Figure 1.)
For their next moves, OpenAI promises smarter, faster, and cheaper AI models, including AI models of different sizes, customized GPT models, and async inference. Roman also mentioned supporting AI agents, saying “we are very excited about agents” and giving the example of Devin, the AI software engineer agent. It raises a question: What AI agent capabilities will OpenAI put into their next GPT models, and will that steamroll AI agent builders?

Open AI Models
Mistral presented on the training process behind their open-source models - Mistral 7B, Mixtral 8x7B and Mixtral 8x22B. Cohere spoke on the successful adoption of the open-source AI model Command-R+, in particular due to its strength in function-calling.
But the biggest open AI model announcement out of the AIEWF event was Google announcing their Gemma 2 models, which we covered in our latest AI Weekly. One thing highlighted in the talk was the multi-lingual capability of Gemma 2, thanks to its rich tokenizer. As mentioned by Google’s Kathleen Kenealy:
One of my favorite projects we saw it was also highlighted in I/O was a team of researchers in India fine-tuned Gemma to achieve state-of-the-art performance on over 200 variants of Indic languages which had never been achieved before.
LLM Training and Fine-Tuning
Gradient spoke about improving AI models for domain-specific use cases and fine-tuning LLMs for increased context length. They are the company behind Llama-3-70B-Instruct-Gradient-1048K, a Llama 3 70B fine-tune with a 1 million token context length. They showed how a 1 million context can help write in the style of Mark Twain, with the help of in-context learning.
“Long context LLMs results in more grounded and robust systems with fewer moving parts, reducting hallucinations.” - Gradient

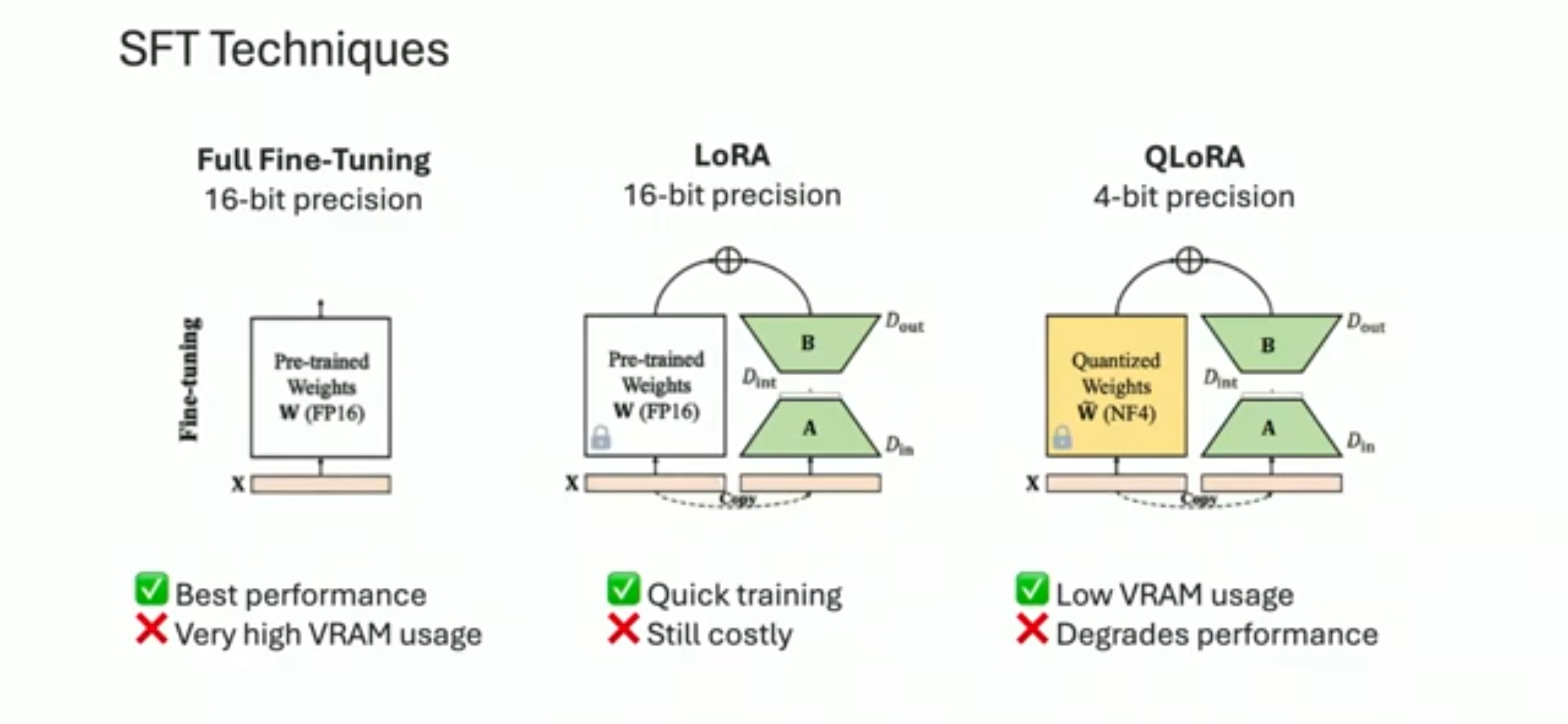
Maxime Labonne of LiquidAI presented on fine-tuning, which takes a base model and trains it with custom instructions to improve performance and alignment. SFT (Supervised Fine-Tuning) takes a (hopefully accurate high-quality) dataset of instruction-answer pairs, and uses that to align the AI model response. This makes for a more performant AI model and/or customizes it for a specific domain or use case.
Libraries to support fine-tuning include TRL, Axolotl, LLaMA factory, and Unsloth. LoRA or QLoRA adjusts a small fraction of the AI model weights, which reduces overhead in fine-tuning; this has made it the go-to method for many fine-tuning applications.
Model merging is the crazy idea that you can slap model weights together from multiple LLMs to create a useful franken-model. Remarkably, it works.
Techniques like SLERP and DARE prune and merge weights through interpolation.
Pass-through is another technique, which concatenates layers from different LLMs or even the same model. By upscaling Llama 3 70B with this self-merge pass-through method, Maxime created Meta-Llama-3-120B-Instruct, which is smarter and better at creative writing than the original Llama 3 70B.
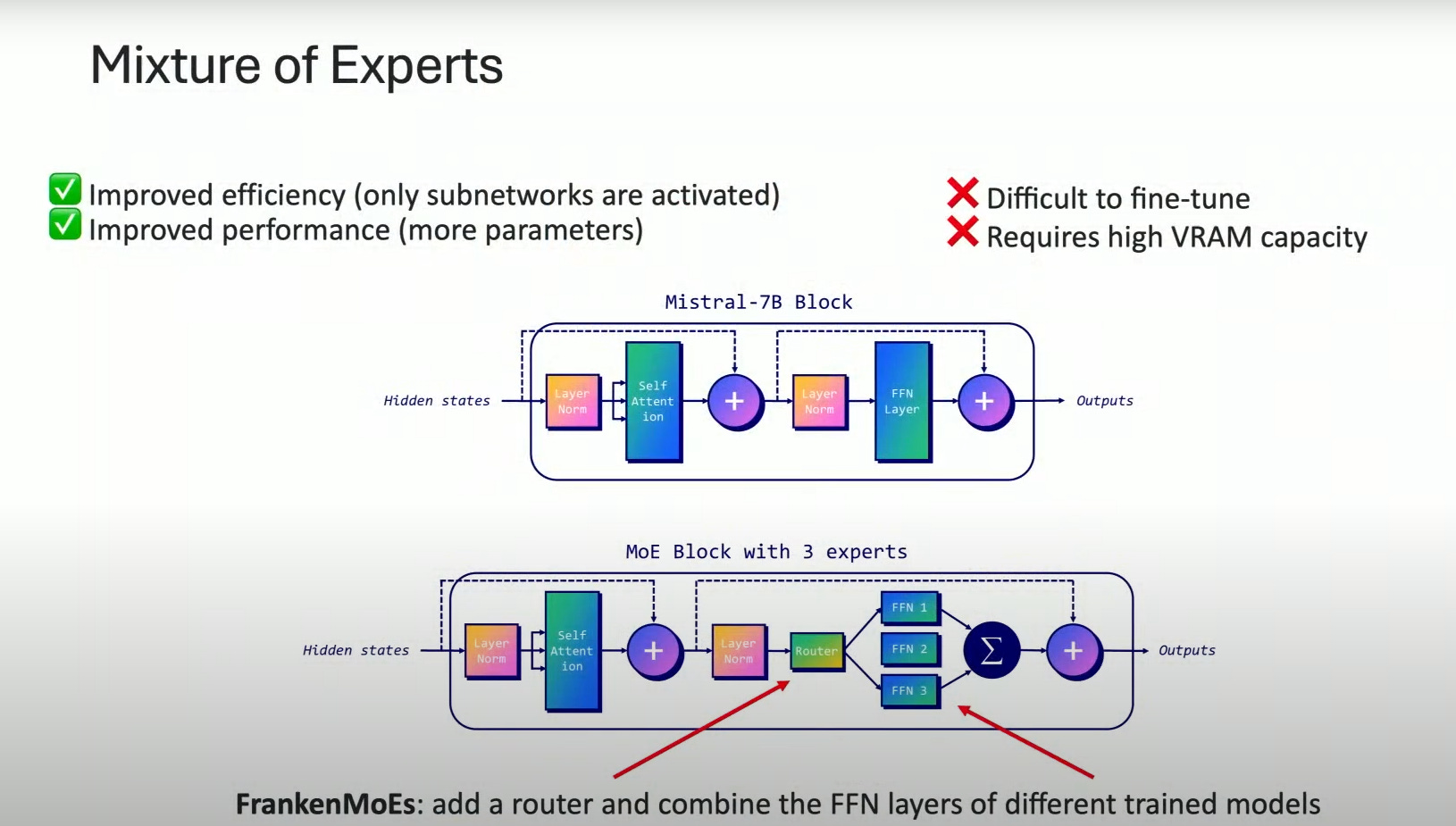
The final method Maxime mentioned is a model merge via Mixture of Experts - FrankenMoE - which takes multiple LLMs and merges them to act like routed experts in an MoE architecture. I hadn’t heard before, but I’ve wondered if such a thing could work.
AI Coding Assistants
A developer conference will naturally discuss coding tools, and an AI conference will naturally discuss one of first and best use cases for AI tools - AI coding assistants.
Github Next on Github Copilot: Github Next is a separate org in Github, itself part of Microsoft. They have a process of exploration, experimentation, and internal dog-fooding ideas, before releasing them as features or products. Github Copilot’s direction is to extend Copilot from code completions to task completions. Recent developments:
Copilot Workspace: This recent release simplifies getting started, integrates cloud compute and an environment for iteration and collaboration. They showed off the plan - spec - code - test flow in Copilot Workspace.
NES - Next Edit suggestions: Adding or deleting lines, not just at current cursor level.
They are also thinking about how AI changes planning, tracking, code reviews and the code editor.
Codeium AI code assistant supports coding auto-complete and chat across 70 programming languages on many IDEs and has had 1.5 million downloads. Kevin Hou of Codeium gave a presentation about context retrieval and why “Embeddings are Limiting AI Agents.”
Three ways of retrieving context to answer AI queries are: Long context, fine-tuning, and embeddings. Long context is slow and expensive; it takes 36 seconds for Gemini to process 325K tokens. Fine-tuning can’t keep up with real-time changes in data.
That leaves embeddings, faster and low-cost to compute and store, but standard retrieval from embeddings gets poor to mixed results in real-world applications.
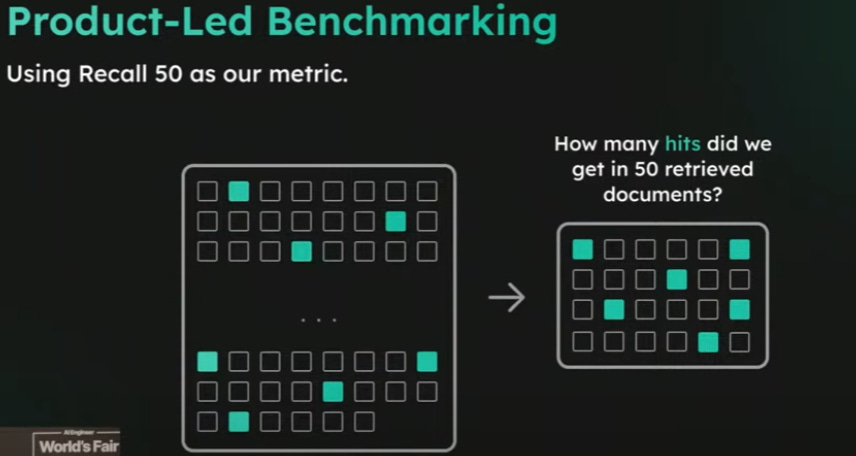
Real-world retrieval is not just about getting a semantically similar context but getting full appropriate contexts and being able to reason on it. NIAH, needle-in-a-haystack, is not realistic, and they needed a Product-driven not research-driven benchmark. They came up with Recall 50: what fraction of your ground truth are in the top 50 documents?
This product-led benchmark used their “Commit Message Databank” to evaluate their own internally developed LLM, using parallel calls (a process called M-Query) to evaluate relevance of documents for retrieval to improve on this task and get best-in-class results on it.
This talk expressed a good example of the data, evaluations and iteration process for building good AI products, that was mentioned in the talk “What We Learned from a Year of Building with LLMs.”
Cursor is an AI-first programming editor that aspires to be the “best tool for professional programmers to use AI.” Cursor CEO Michael Truell asks the question: What does Coding look like in age of AI? There are two existing approaches: Plugins that make auto-complete better in your IDE, and AI Agents that replace the whole code development effort. They have a different take:
Programming will still exist in 5 years, and still be a profession, but it will change a ton and it’s going to demand an entirely new tool for Software Engineering.
Cursor’s current features are around AI code-writing and Q&A, similar to other AI code assistants, but they presented some of their ongoing developments:
Predicting your next edit or action anywhere in code base - copilot++.
Command-K: ask AI to change a block of code and iterate
Letting you read and write pseudocode, with control over levels of abstraction
Last but not least, there were demos and presentations of Amazon Q. They stated Amazon Q is based on best model for coding, but they didn’t talk about internals. The features were standard for current AI coding assistants: Q can explain code, generate code at function level; Q’s planning feature can do multi-step transforming and generating code. They pitched that with Gen AI, you can become more of a product manager with AI as your dev.
What Really Works in AI Assistants?
In the final keynote, the Github CEO mentioned that half of the code on Github is written via the Github copilot auto-complete. But Quinn Slack, CEO of Sourcegraph, which makes the Cody AI coding assistant, mentioned that the ARR from code AI enterprise usage is currently only $300 million, not enough to pay upstream foundation AI model companies.

Quinn Slack’s take is that AI hype is distracting from what really works and gets DAUs, daily active users. Customers ask for features not because they need them, but because they think it will make the AI finally work.
“I want fine-tuned models” == “I want it to work” - Quinn Slack, Sourcegraph CEO
So is AI hype or real? Yes to both. We are still exploring and experimenting how to turn AI into useful assistants for our work and lives. Some AI will live up the hype, some will not.

Conclusion
In Part 1 and Part 2 of our review of the AIEWF - AI Engineer World’s Fair - we have covered highlights in AI trends, AI building principles, AI models, fine-tuning, and AI coding assistants. There’s still more to cover.
Follow-up articles will focus on developments, releases and products for the AI stack: GPUs and inference; AI infrastructure and AI frameworks; RAG (retrieval-augmented generation) and managing data and context; and AI agents. More to come!