


AI Research Review 24.12.18 - NeurIPS 2024
NeurIPS 2024 Main Themes and Top Papers: Visual Autoregressive Modeling, PRISM Alignment Dataset, Scattering Graph Representation Learning, Convolutional Differentiable Logic Gate Networks, xLSTM.


Introduction – NeurIPS 2024
The latest Annual Conference on Neural Information Processing Systems, NeurIPS 2024, just concluded in Vancouver, Canada. NeurIPS is one of the most prestigious AI conferences globally, with a record number of submissions and attendees.
Our AI Research Review for this week covers the main themes and top papers and presentations from NeurIPS 2024. The papers we cover are based on winning best paper conference awards or achieving high reviewer scores:
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
The PRISM Alignment Dataset: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of Large Language Models
Exploitation of a Latent Mechanism in Graph Contrastive Learning: Representation Scattering
Convolutional Differentiable Logic Gate Networks
xLSTM: Extended Long Short-Term Memory
Additional noteworthy NeurIPS 2024 papers and talks
Before discussing specific papers, we will discuss major themes at the conference.
Major Themes of NeurIPS 2024
This year's conference highlighted themes such as generative AI, ethical considerations, data-centric AI, advancements in large language models (LLMs), and innovations in the peer-review process. Key themes and takeaways:
Fast progress in Generative AI and LLMs: NeurIPS 2024 highlighted considerable progress in generative AI, with researchers presenting new AI models and applications. Many papers explored new techniques for training LLMs more efficiently, improving their performance, and addressing their limitations.
Novel AI model architectures: Novel architectures, such as xLSTM, Latent Prompt Transformer (LPT), and Visual Autoregressive Modeling (VAR), were presented.
Focus on Real-World Applications: While many papers at NeurIPS are academic, many papers and talks focused on applying AI to real-world problems. Examples include groundbreaking AI applications in drug discovery and clinical time series analysis.
Data-centric AI: Data quality and management are increasingly recognized as crucial for building robust and reliable AI systems. Many researchers presented methods for improving data quality, detecting and mitigating biases in datasets, and efficiently managing large datasets.
AI Research Assistants: The conference experimented with using LLMs to assist authors in meeting submission standards, demonstrating the potential of AI to improve scientific rigor and accelerate scientific workflows.
Ethics in AI: Ethical considerations were a prominent topic, catalyzed by a controversy involving a Chinese researcher expelled from a top-tier university for manipulating research results. Rosalind Picard’s keynote speech further fueled debate, as her reference to this case raised concerns about cultural sensitivity.
Interdisciplinary Collaboration: The conference fostered collaboration between researchers across different domains, including computer scientists and neuroscientists. Panel sessions on AI for Autonomous Driving at Scale, Neuroscience and Interpretability, and Human-AI Interaction highlighting the interest in a broad range of AI-related topics.
Finally, as we mentioned in our prior AI Week in Review, Ilya Sutskever gave an invited talk at NeurIPS accepting the “Test of Time” award. He made waves by predicting that scaling AI via pre-training will end due to limits on data, saying “Data is the fossil fuel of AI. There is but one internet.”
Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction
The paper Visual Autoregressive Modeling: Scalable Image Generation via Next-Scale Prediction won Best Paper at NeurIPS 2024 for good reason: It introduces Visual Autoregressive Modeling (VAR), a novel approach to image generation using autoregressive models that is remarkably faster and better than prior methods. Unlike traditional autoregressive methods that predict pixels sequentially, VAR predicts entire image scales in a coarse-to-fine manner.
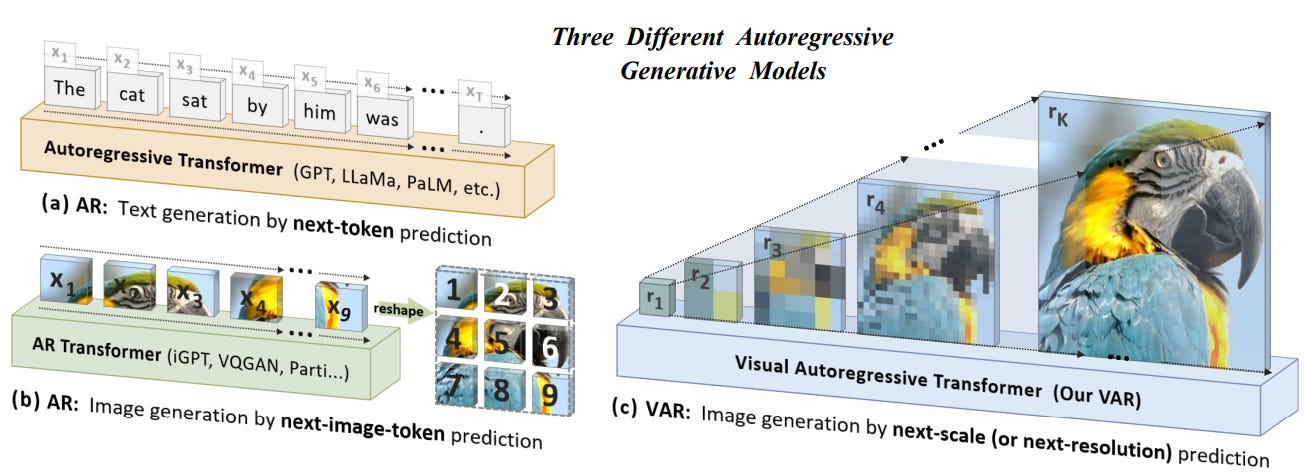
Generating an image with "next-scale prediction" starts with a blurry low-res overview and progressively adds finer details. This approach marks a significant shift in autoregressive image generation and allows the model to learn visual patterns more efficiently and generalize better.
This GPT-style autoregressive VAR model outperforms diffusion models, the current leading method, in image generation tasks, as well as auto-regressive (AR) baselines:
On ImageNet 256x256 benchmark, VAR significantly improves AR baseline by improving Frechet inception distance (FID) from 18.65 to 1.73, inception score (IS) from 80.4 to 350.2, with around 20x faster inference speed. It is also empirically verified that VAR outperforms the Diffusion Transformer (DiT) in multiple dimensions including image quality, inference speed, data efficiency, and scalability.
This is a major breakthrough, as autoregressive models are known for their scalability and ability to generate high-quality, diverse images. The paper also reveals intriguing scaling laws within VAR transformers, suggesting that performance can improve predictably with increased model size and data. This paves the way for even more powerful and efficient image generation models.
The PRISM Alignment Dataset: What Participatory, Representative and Individualised Human Feedback Reveals About the Subjective and Multicultural Alignment of LLMs
Human feedback is vital to creating aligned LLMs, but the subjectivity of human feedback raises questions and challenges about what feedback to collect and how to process it to effectively refine LLMs.
The PRISM Alignment Dataset presents an approach to address that challenge, with the PRISM dataset boasting a diverse range of human interactions and perspectives.
The authors collected data from 1,500 participants in 75 countries with diverse demographics and sourced both subjective and multicultural perspectives benchmarking over 20 current frontier AI models. PRISM incorporated:
(i) wider geographic and demographic participation in feedback;
(ii) census-representative samples for two countries (UK, US); and
(iii) individualised ratings that link to detailed participant profiles, permitting personalisation and attribution of sample artefacts.
The PRISM dataset provides a unique perspective on human interactions with LLMs and cultural differences on human preferences with AI, and it enables research on pluralism and disagreements in RLHF. This research also demonstrates the need for careful consideration of which humans provide what alignment data.
Exploitation of a Latent Mechanism in Graph Contrastive Learning: Representation Scattering
Graph Contrastive Learning (GCL) is a technique used to learn representations of nodes in a graph. The paper “Exploitation of a Latent Mechanism in Graph Contrastive Learning: Representation Scattering” identifies a key mechanism called "representation scattering" that plays a crucial role in the effectiveness of GCL and proposes a new framework called Scattering Graph Representation Learning (SGRL) to exploit it.
SGRL introduces two novel mechanisms:
Representation Scattering Mechanism (RSM): This mechanism embeds node representations onto a hypersphere, ensuring they are positioned away from the mean center. This promotes diversity in the learned representations.
Topology-based Constraint Mechanism (TCM): This mechanism considers the interconnected nature of graphs and prevents excessive scattering, ensuring that important structural information is preserved.
The authors demonstrate the effectiveness of SGRL through extensive experiments on various downstream tasks and benchmark datasets. Their findings highlight the importance of representation scattering in GCL and provide a structured framework for harnessing this mechanism to improve graph representation learning.
Convolutional Differentiable Logic Gate Networks
This paper Convolutional Differentiable Logic Gate Networks introduces a novel class of neural networks called Convolutional Differentiable Logic Gate Networks (CDLGNs). These networks combine the flexibility of deep neural networks with the interpretability and composability of logical operations.
CDLGNs are designed to learn and represent logical functions efficiently. They achieve this by:
Utilizing logic gate operators like NAND, OR, and XOR Boolean operators, which are fundamental building blocks of hardware and can be executed efficiently.
Incorporating deep logic gate tree convolutions, which allows for scaling up logic gate networks.
Employing logical OR pooling: This mechanism helps in aggregating information and making decisions based on logical operations.
Using residual initializations: This technique improves the training process and stability of the network.
The authors demonstrate the effectiveness of CDLGNs on the CIFAR-10 dataset, achieving state-of-the-art accuracy with a significantly smaller model size compared to traditional neural networks. The logical structure of CDLGNs enables AI systems that are more trustworthy and explainable, which opens up new possibilities for building AI systems that are both powerful and interpretable.
xLSTM: Extended Long Short-Term Memory
This paper “xLSTM: Extended Long Short-Term Memory” revisits and revises Long Short-Term Memory (LSTM) networks, a popular type of recurrent neural network used for sequence modeling. We first reviewed the xLSTM paper in May when a pre-preprint was first published.
While LSTMs have been successful in various applications, they have limitations in parallelization and information retention. The authors introduce two key modifications to develop xLSTM to address these limitations:
Exponential gating: This mechanism improves the ability of LSTMs to revise storage decisions and retain information more effectively.
Novel memory structures: xLSTM introduces new memory structures, including scalar memory and matrix memory, which enhance the storage capacity and parallelization capabilities of LSTMs.
The authors demonstrate that xLSTM performs favorably compared to state-of-the-art Transformers and State Space Models both in performance and scaling.
By addressing the limitations of traditional LSTMs, xLSTM offers a potentially more efficient and interpretable alternative for building powerful LLMs. This paper is important because the development of xLSTM challenges the current dominance of Transformers in sequence modeling.
Additional Noteworthy Papers and Talks at NeurIPS 2024
Additional talks and papers at the conference:
In-context learning: The talk “Learning to grok: Emergence of in-context learning and skill composition in modular arithmetic tasks” explored how AI models can learn and adapt to new tasks and contexts, potentially drawing inspiration from cognitive science and human learning.
Graph neural networks: “Temporal Graph Neural Tangent Kernel with Graphon-Guaranteed.” This paper presents theoretical properties of graph neural networks and their ability to learn from temporal data and model dynamic systems.
AI models for biology: “MSA Generation with Seqs2Seqs Pretraining: Advancing Protein Structure Predictions” improves protein structure prediction using AI. The highly rated paper “Trajectory Flow Matching with Applications to Clinical Time Series Modelling” presents an improved method for modeling time series data that is both stochastic (randomly determined) and irregularly sampled, addressing a common challenge in medical applications.
Symbolic AI: The paper “LogiCity: Advancing Neuro-Symbolic AI with Abstract Urban Simulation” presents a new platform for developing and testing AI systems that combine neural networks with symbolic reasoning. the reasoning abilities of symbolic AI.
Depth estimation: The research in “Self-Distilled Depth Refinement with Noisy Poisson Fusion” presents new techniques for improving AI-based depth estimation, useful in robotics and autonomous driving.
Deepfake Detection: The paper “DF40: Toward Next-Generation Deepfake Detection” focuses on developing more robust methods for detecting deepfakes.
Conclusions and Takeaways
NeurIPS 2024 provided a glimpse into the rapid advancement of AI, with researchers pushing the boundaries of what's possible in AI. The conference highlighted ethical considerations in AI, data-centric approaches in AI, practical real-world AI applications, novel AI model architectures, and marked progress in developing efficient and interpretable AI models.
These trends are likely to continue, and they will shape the research and development of AI in coming years. Done right, this will lead to AI systems that are more accessible, trustworthy, reliable, and better aligned with human values.
PostScript
I ran Google’s Deep Research in Gemini Advanced as an experiment to help research and write this article. The result was startling and impressive; in a few minutes, it combed through 37 websites, analyzed the information, and produced a 2500-word report.
I was initially impressed with a thorough and accurate being that quick. On closer inspection, however, I noticed it needed much rework. It got details wrong, missed covering papers it should have, and wrote wordy “fluff” prose with overused cliches (“delve” was used several times).
Deep Research definitely saves you time as an AI assistant for online research and drafting, and it is a cut above Perplexity, ChatGPT search or other alternatives for this task. However, it needs oversight to get to useful output; even the best AI agents are still junior co-pilots.