


AI Research Roundup 24.04.26
Apple's OpenELM, Phi-3 Tech Report, AutoCrawler, Multi-head MoE, AI and Knowledge Collapse, Your LLM is a Q-function, CT-Agent


Introduction
Here are our AI research highlights for this week:
Apple’s OpenELM: An Efficient Language Model Family
Phi-3 Technical Report: A Highly Capable Language Model on Your Phone
AutoCrawler: A Web Agent for Web Crawler Generation
MHMoE: Multi-head mixture of experts
AI and the Problem of Knowledge Collapse
From r to Q∗: Your Language Model is Secretly a Q-Function
CT-Agent: Clinical Trial Multi-Agent with LLM-based Reasoning
Apple’s OpenELM: An Efficient Language Model Family
Apple has released some remarkable open AI models called OpenELM models on HuggingFace. Apple calls these language models “ELM” for Efficient Language Model, to distinguish them from LLMs as smaller but more efficient language models, with 270M, 450M, 1.1B and 3B parameters.
The Apple team behind OpenELM shared their results and training process in “OpenELM: An Efficient Language Model Family with Open-source Training and Inference Framework.” Apple is being very open in their work, sharing not only the model weights, but data training set details, training process, and even their CoreNet training source code on Github:
.. our release includes the complete framework for training and evaluation of the language model on publicly available datasets, including training logs, multiple checkpoints, and pre-training configurations. We also release code to convert models to MLX library for inference and fine-tuning on Apple devices.
The pre-training dataset totals approximately 1.8 trillion tokens and contains parts of other open datasets (RefinedWeb, PILE, RedPajama, and Dolma). To improve the model’s accuracy, OpenELM used a layer-wise scaling strategy to efficiently allocate parameters within each layer of the transformer model.
Model performance: OpenELM 1B and 3B models are improved over other LLMs like oLMo, but not close to the best-in-class Phi-3 LLM. For example, OpenELM 1B and 3B have an MMLU of 27, while Phi-3 has a stunning MMLU score of 69.
By being so open with code and date, the OpenELM paper and project is a great contribution towards open AI research and reproducibility for LLMs. The open AI model efforts empower the open research community in further AI model development endeavors.
Phi-3 Technical Report
The paper “Phi-3 Technical Report: A Highly Capable Language Model Locally on Your Phone” describes Microsoft’s recently released Phi-3 model. We discuss Phi-3 in the article “Data Is All You Need,” and the main message of our article and the Phi-3 paper is about data. Specifically, developers created high-quality training data to train Phi-3 as efficiently as possible:
Unlike prior works that train language models in either “compute optimal regime” or “over-train regime”, we mainly focus on the quality of data for a given scale. We try to calibrate the training data to be closer to the “data optimal” regime for small models.
Data optimal for Phi-3 3.8B means that it was trained on 3.3 trillion tokens of carefully curated data: “a combination of LLM-based filtering of web data, and LLM-created synthetic data.” The result is stunning - Phi-3 3.8B achieves SOTA 68.8 MMLU score, matching and beating much larger LLMs in quality. I am using it through ollama as a quick, practical LLM for local use.
AutoCrawler: A Web Agent for Web Crawler Generation
To automate web tasks, we need to automatically navigate and extract info from web pages, i.e., web crawling. The paper “AutoCrawler: A Progressive Understanding Web Agent for Web Crawler Generation” presents an approach to handle the web crawler challenge that combines LLMs and web crawlers:
We propose AutoCrawler, a two-stage framework that leverages the hierarchical structure of HTML for progressive understanding. Through top-down and step-back operations, AutoCrawler can learn from erroneous actions and continuously prune HTML for better action generation.
Phase 1 uses top-down and step-back to navigate the DOM hierarchy of a webpage. The phase 2 synthesis converts the webpage navigation into a directed action sequence.
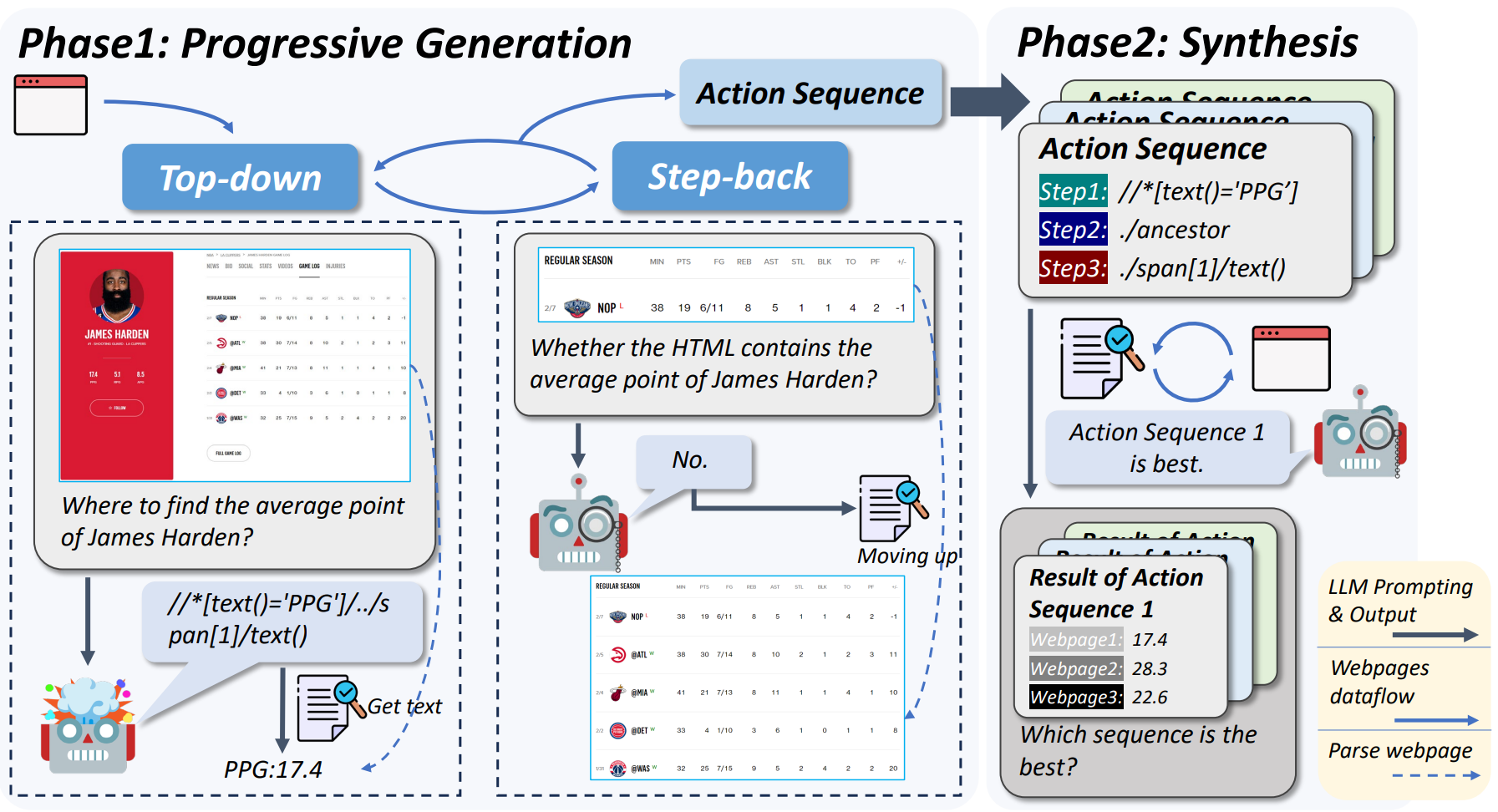
They conducted experiments with multiple LLMs and demonstrated how different LLMs perform with the framework. GPT-4 combined with AutoCrawler had the best performance on benchmarks of web-page understanding. Resources for this paper can be found here.
Multi-Head Mixture-of-Experts
The paper “Multi-Head Mixture-of-Experts” takes another twist on the mixture-of-experts transformer architecture. Sparse Mixtures of Experts (SMoE) scales model capacity efficiently, because both training and inference can be conducted without activating all parameters. However, MoE models can be limited by low expert activation (in which some experts on some layers are rarely used), and they lack ability to process multiple concepts in a token.
To enable more fine-grained treatment of each token through experts they propose Multi-Head Mixture-of-Experts (MH-MoE):
[MH-MoE] employs a multi-head mechanism to split each token into multiple sub-tokens. These sub-tokens are then assigned to and processed by a diverse set of experts in parallel, and seamlessly reintegrated into the original token form.

They show through experiments that MH-MoE enhances expert activation and allows the model to “collectively attend to information from various representation spaces within different experts.” In layman’s terms, the MH-MoE model can analyze multiple concepts at the same time, which deepens understanding.

It’s unclear whether MH-MoE will displace existing mixture-of-experts, but this research shows positive results. It also is an indicator that there are many possible architectural innovations left to explore for transformer-based models.
AI and the Problem of Knowledge Collapse
The paper “AI and the Problem of Knowledge Collapse” takes a deep-dive into the problem that can occur when AI models are built on AI output data:
While large language models are trained on vast amounts of diverse data, they naturally generate output towards the 'center' of the distribution. This is generally useful, but widespread reliance on recursive AI systems could lead to a process we define as "knowledge collapse", and argue this could harm innovation and the richness of human understanding and culture.
This concern is worth noting because we are seeing increased LLM-generated content on the web and AI-generated synthetic data, all being fed into AI model datasets. The author’s solution is maintaining knowledge diversity and the “long-tails” of knowledge:
We provide a positive knowledge spillovers model with in which individuals decide whether to rely on cheaper AI technology or invest in samples from the full distribution of true knowledge. We examine through simulations the conditions under which individuals are sufficiently informed to prevent knowledge collapse within society.
This issue, and its solution, could become more important over time, as AI content becomes a larger portion of the information available in books, the web, video, etc.
From r to Q∗: Your Language Model is Secretly a Q-Function
Researchers from Stanford tie Reinforcement Learning From Human Feedback (RLHF), Direct Preference Optimization (DPO), and Q-learning together in the paper “From r to Q∗: Your Language Model is Secretly a Q-Function.” From these connections and theoretical results, they identify a way to improve DPO fine-tuning.
RLHF has been used to fine-tune LLMs, but it is complex and human-intensive, so alternatives such as DPO have arisen. The authors point out a discrepancy in how DPO works versus RLHF:
Standard RLHF deploys reinforcement learning in a specific token-level MDP (Markov Decision Process), while DPO is derived as a bandit problem in which the whole response of the model is treated as a single arm. In this work we rectify this difference, first we theoretically show that we can derive DPO in the token-level MDP as a general inverse Q-learning algorithm, which satisfies the Bellman equation.
The Bellman equation is an important equation for Q-learning, which is a key algorithm in reinforcement learning. The DPO optimization algorithm can be formulated as learning a Q-function, and we can use DPO to learn the optimal policy for any per-token reward function.
This has several practical benefits and applications:
With token-level interpretation, DPO is able to perform token-based ‘credit assignment’ to identify helpful vs unhelpful tokens in a response. This is useful for improving reasoning.
They are able to connect search methods to DPO, and show that a simple beam search with DPO yields meaningful improvement over the base DPO policy.
They are able to explain how choice of reference policy causes implicit rewards to decline during training.
This formulation of DPO can be extended to improving LLM reasoning, optimizing AI agent applications, and end-to-end training of multi-model systems.
CT-Agent: Clinical Trial Multi-Agent with LLM-based Reasoning
CT-Agent, presented in the paper “CT-Agent: Clinical Trial Multi-Agent with Large Language Model-based Reasoning,” is an AI Multi-Agent designed to autonomously set up and manage a clinical trial:
Recognizing the potential of advanced clinical trial tools that aggregate and predict based on the latest medical data, we propose an integrated solution to enhance their accessibility and utility. We introduce Clinical Agent System (CT-Agent), a Clinical multi-agent system designed for clinical trial tasks, leveraging GPT-4, multi-agent architectures, LEAST-TO-MOST, and ReAct reasoning technology.
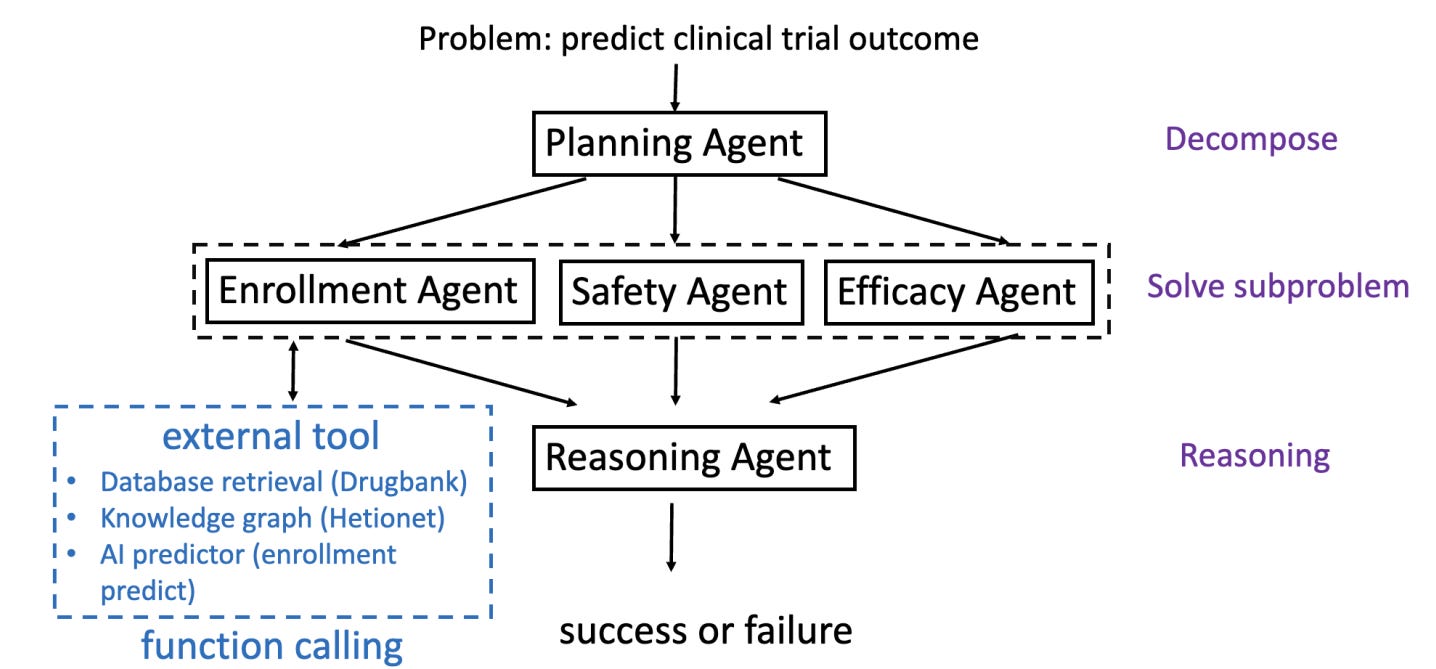
CT-Agent combines conversational AI and actionable intelligence to manage complexities inherent in clinical trials. This is a great example of how to implement specialized AI Agents for healthcare.