
AI Research Roundup 24.06.21- Models and Variations
DeepSeek Coder V2, DataComp LM framework and dataset, Instruction-based pre-training, and Self-MoE.


Introduction
Here are our AI research highlights for this week:
DeepSeek-Coder-V2: Beating Closed-Source Models in Code Intelligence.
DataComp-LM: Next generation of training sets for language models.
Instruction Pre-Training: Language Models are Supervised Multitask Learners
Self-MoE: Towards Compositional LLMs with Self-Specialized Experts.
DeepSeek-Coder-V2: Beating Closed-Source Models in Code Intelligence
AI coding models keep getting better. Just-released Claude 3.5 Sonnet gets an astounding 92% on Human eval. Now, open-source Mixture-of-Experts (MoE) AI coding model DeepSeek-Coder-V2 beats all prior AI models as well, getting 90.2% on HumanEval.
The paper “DeepSeek-Coder-V2: Breaking the Barrier of Closed-Source Models in Code Intelligence” presents the key technical details on this model suite.
There are two MoE models, DeepSeek-Coder-V2-Lite and DeepSeekCoder-V2, with 16B and 236B total parameters respectively; they have activation parameters of only 2.4B and 21B respectively.
The MoE architecture: DeepSeek-Coder-V2 follows that of DeepSeek-V2, with 2 shared experts from 64 routed experts:
DeepSeek-V2-Lite also employs DeepSeekMoE, and all FFNs except for the first layer are replaced with MoE layers. Each MoE layer consists of 2 shared experts and 64 routed experts, where the intermediate hidden dimension of each expert is 1408.
Pre-training: DeepSeek-Coder-V2 starts from an intermediate checkpoint of DeepSeek-V2, trained on 4.2T (trillion) tokens, and is further pre-trained with an additional 6T tokens. This additional training substantially enhances its coding and mathematical reasoning capabilities, while without losing general language performance comparable to DeepSeek-V2.

Alignment: Both SFT and RL-based alignment was performed.
Capabilities and benchmarks: DeepSeek-Coder-V2 demonstrates significant advancements in code-related tasks, supports 338 programming languages, and extends the maximum context length to 128K tokens. DeepSeek-Coder-V2 achieves superior performance compared to closed-source models such as GPT4-Turbo, Claude 3 Opus, and Gemini 1.5 Pro in coding and math benchmarks.

DataComp-LM: Next generation training sets for language models
As we explained in “Data Is All You Need,” data is the driving factor in improving AI models. You need more data and higher quality data.
A large-scale collaboration of researchers in several Universities and and organization present DataComp-LM and the paper “DataComp-LM: In search of the next generation of training sets for language models,” which is a testbed for dataset experiments and a dataset corpus:
We introduce DataComp for Language Models (DCLM), a testbed for controlled dataset experiments with the goal of improving language models. As part of DCLM, we provide a standardized corpus of 240T tokens extracted from Common Crawl, effective pretraining recipes based on the OpenLM framework, and a broad suite of 53 downstream evaluations.
The DCLM workflow is to select an AI model scale, build and curate a dataset, train a model with it, and finally evaluate the results:
Participants in the DCLM benchmark can experiment with data curation strategies such as deduplication, filtering, and data mixing at model scales ranging from 412M to 7B parameters.

This experimental process over datasets their processing, and AI training over it, is a way to improve and optimize datasets for the best AI model results. Using their own process to optimize their dataset, they found:
DCLM-Baseline enables training a 7B parameter language model from scratch to 64% 5-shot accuracy on MMLU with 2.6T training tokens. Compared to MAP-Neo, the previous state-of-the-art in open-data language models, DCLM-Baseline represents a 6.6 percentage point improvement on MMLU while being trained with 40% less compute.
Remarkable, they were even able to get a result better than Llama 3 8B:
Our baseline model is also comparable to Mistral-7B-v0.3 and Llama 3 8B on MMLU (63% & 66%), and performs similarly on an average of 53 natural language understanding tasks while being trained with 6.6x less compute than Llama 3 8B.

This result is exciting for several reasons. More optimization of AI models is possible, thanks to significant data available to make better AI models. These techniques help optimize dataset curation, which leads to more efficient training. Also, this open research will improve open AI models; the data and techniques are available to all, not locked up by a few proprietary AI model makers.
Dataset, paper, comparison leaderboard, code and more is available at datacomp.ai.
Instruction Pre-Training: Language Models are Supervised Multitask Learners
Currently, LLM training consists of unsupervised pre-training and then fine-tuning using instruction-based question and answers. This is effective but it requires a lot of data. Could there be a more efficient way?
The paper “Instruction Pre-Training: Language Models are Supervised Multitask Learners” tries a whole different take on pre-training, turning it into supervised multitask pre-training, a training process more akin to instruction fine-tuning.
It’s called Instruction Pre-Training. It converts unsupervised training data into instruction-response pairs, and used that data to pre-train the LLM:
The instruction-response pairs are generated by an efficient instruction synthesizer built on open-source models.

They scale this process up to “200M instruction-response pairs covering 40+ task categories” to verify the effectiveness of Instruction Pre-Training. Their results showed a benefit to model performance:
Instruction Pre-Training not only consistently enhances pre-trained base models but also benefits more from further instruction tuning. In continual pre-training, Instruction Pre-Training enables Llama3-8B to be comparable to or even outperform Llama3-70B.
As a limitation, they note that this method generates and uses synthetic data, and so it could be susceptible to hallucination or other issues from synthetic data. However, I wonder if the billions of already-existing user interactions with models like GPT-4 could be used as data for this process.
The model, code, and data for Instruction Pre-Training are available on Github.
Self-MoE: Compositional LLMs with Self-Specialized Experts
The paper “Self-MoE: Towards Compositional Large Language Models with Self-Specialized Experts” presents an architectural wrinkle on the MoE, mixture-of-experts concept:
Self-MoE transforms a monolithic LLM into a compositional, modular system of self-specialized experts, named MiXSE (MiXture of Self-specialized Experts).

How it works is that it starts with a generalized dense LLMs, fine-tunes the base LLM into a number of specialized experts using self-generated synthetic data; then these are merged with a base LLM and are directed by self-optimized routing.
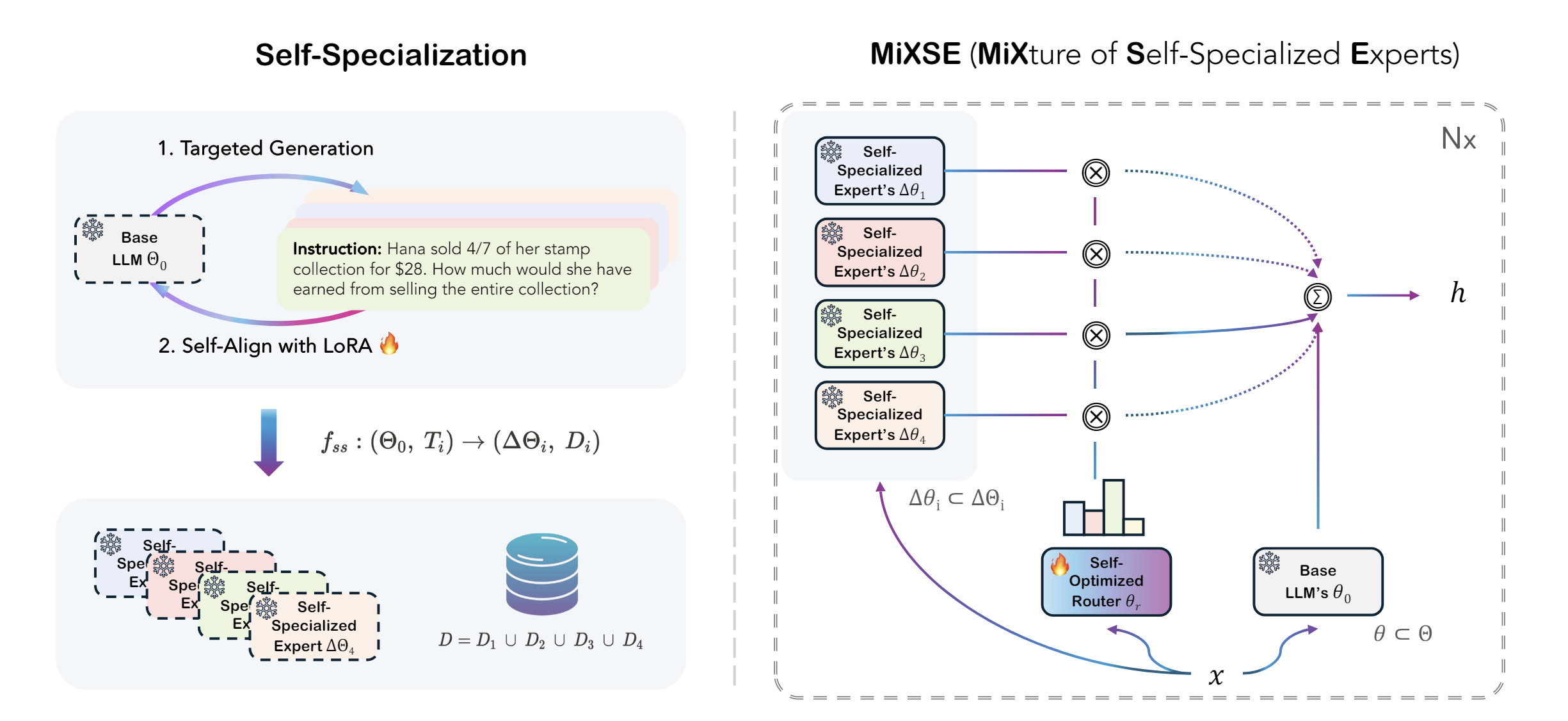
This architecture is quite different and much more coarse-grained than MoE AI models. It’s more similar to methods of AI model merging, but is far less brute-force than methods that simply merge weights. The authors note:
Self-MoE demonstrates substantial improvements over the base LLM across diverse benchmarks such as knowledge, reasoning, math, and coding. It also consistently outperforms other methods, including instance merging and weight merging, while offering better flexibility and interpretability by design with semantic experts and routing.
They were able to start with Gemma 7B and improve its benchmark performance with the Self-MoE architecture. Thus, it can be viewed as yet another promising variant on getting more out of AI models through AI model fine-tuning, merging, and routing.