
AI Research Roundup 24.07.19 - Scaling
Project Strawberry at OpenAI, Mixture of a million experts, NeedleBench: Evaluating a million token context, scaling to a trillion-token datastore for retrieval, Qwen 2 tech report


Introduction
Here are our AI research highlights for this week, with a focus on scaling experts, data and retrieval to “millions” - a million experts, needles in a million token context, and a million-million sized datastore for retrieval-based LLMs:
Project Strawberry
Mixture of a Million Experts
NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
Scaling Retrieval-Based Language Models with a Trillion-Token Datastore
Qwen2 Technical Report
OpenAI’s Project Strawberry
SingularityHub shares the news from Reuters that OpenAI’s Project Strawberry is Building AI that reasons to conduct ‘Deep Research’. This OpenAI research project news is a leak, not published, but gives us a sense of where OpenAI is going with AI reasoning.
In a related report, OpenAI Scale Ranks Progress Toward ‘Human-Level’ Problem Solving. OpenAI’s internal roadmap for AI envisions 5 ‘levels’ of AI. Beyond chatbot-level AI are human-level reasoning at level 2 and agentic systems that can take autonomous reasoned actions at level 3.

OpenAI's Project Strawberry aims to advance reasoning in AI: This initiative seeks to enhance AI models to perform complex tasks that require planning and advanced reasoning, moving beyond the limitations of current models that struggle with multi-step problem-solving.
The Strawberry project target capability is to build AI that can autonomously navigate the internet and conduct what OpenAI calls "deep research." This involves using a specialized dataset to train models that can perform long-horizon tasks, requiring them to plan and execute a series of actions over extended periods.
This project is likely an extension of Q*, which was reported last November to be a significant breakthrough in AI reasoning capabilities at OpenAI. It was reported that OpenAI demonstrated in an internal meeting a model that showcased new human-like reasoning skills. As we discussed last November in the wake of the Q* revelations, the Q* reasoning approach is likely based on process reward model, and this work may be extending that further.
Some have observed that the latest AI models are likely fine-tuned on process-reward models already to get better at complex reasoning queries. Ask Claude 3.5 Sonnet a complex reasoning question with a simple prompt, and it starts its answer with “Let's approach this step-by-step.”
Based on the information shared, OpenAI’s approach to get to AGI is to make their AI models more agentic: Planning, tool use (search the internet), and reasoning (complex problem-solving). This is not different from what others are trying, including some of their customers who build agentic AI tools on top of their AI model APIs.
Finally, this OpenAI project confirms that raw scaling is not the sole path to AI progress, and that significant algorithmic breakthroughs are needed in AI reasoning to get to AGI.
Mixture of a Million Experts
The paper Mixture of a Million Experts from a researcher at Google DeepMind introduces a new approach to mixture-of-experts (MoE) architectures. It’s been observed that fine-grained MoE can scale such that higher granularity leads to better performance, as shown in “Scaling Laws for Fine-Grained Mixture of Experts.” The author observes:
Extrapolating this fine-grained MoE scaling law suggests that continued improvement of model capacity will ultimately lead to a large model with high granularity, corresponding to an architecture of an immense number of tiny experts.
Most MoE architectures use a small number of experts for computational and training optimization reasons. (Mistral’s MoE models have used 8 experts, for example.) The fine-grained MoE approach has been underexplored. The challenge is an efficient way to route from a huge number of experts without extreme overhead.
The solution is PEER (parameter efficient expert retrieval). It’s “a novel layer design that utilizes the product key technique for sparse retrieval from a vast pool of tiny experts (over a million).” The PEER approach scales up the number of experts but makes each of them the smallest possible single-layer expert: a singleton MLP that has only one hidden layer with a single neuron.

The routing to the experts is done with matching retrieval, choosing the top k closest-matching experts of the N experts using a two-step process to make it more efficient.
Experiments on language modeling tasks demonstrate that PEER layers outperform dense FFWs and coarse-grained MoEs in terms of performance-compute trade-off.
NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
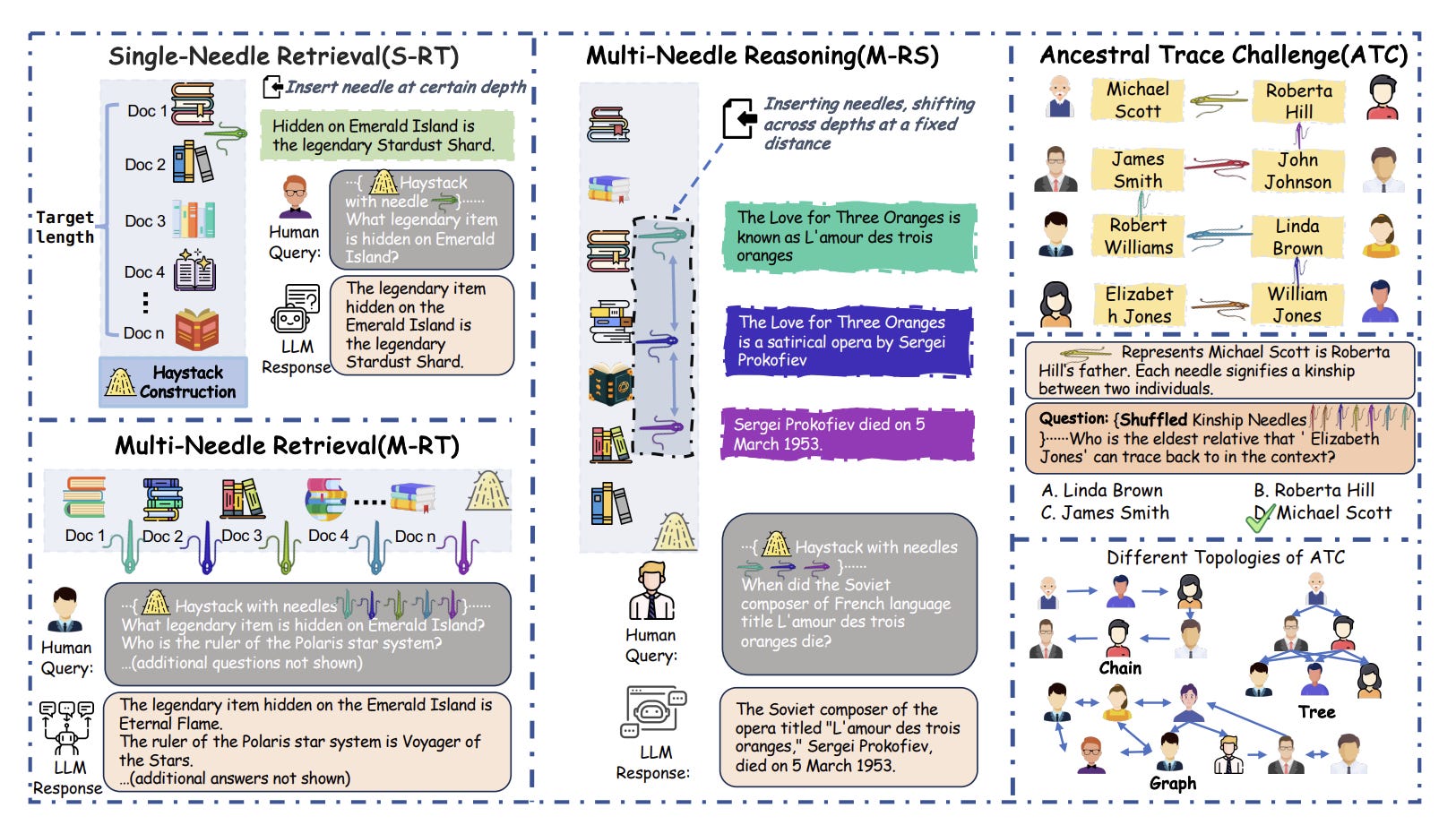
As LLM context windows expand, we need to know if LLMs are properly retaining and using the information in the context as they reason and respond to queries. Hence the question in the paper titled NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?
As the name implies, NeedleBench is a benchmarking framework of progressively challenging tasks to assess context retention and understanding across a range of length intervals and document text depths, done on bilingual (Chinese and English) text. These include Single-Needle Retrieval Tasks, Multi-Needle Retrieval Tasks, and Multi-Needle Reasoning Task. The last is evaluating complex reasoning over multiple inserted pieces of information (the ‘needles).
They also test using the Ancestral Trace Challenge (ATC):
Furthermore, we propose the Ancestral Trace Challenge (ATC) to mimic the complexity of logical reasoning challenges that are likely to be present in real-world long-context tasks, providing a simple method for evaluating LLMs in dealing with complex long-context situations.
They tested the NeedleBench framework on many leading open-source AI models. The LLMs tested had a drop-off in benchmark results from simple single-needle retrieval to multi-needle retrieval and reasoning and more complex tasks. To answer the question in the paper’s title: LLMs struggle with doing reasoning over multiple information sources across long contexts. There’s room to improve.
The NeedleBench dataset and code are available at OpenCompass on Github.
“Our research uncovers notable limitations in the current opensource LLMs’ ability to interpret and reason over long texts.” - From “NeedleBench: Can LLMs Do Retrieval and Reasoning in 1 Million Context Window?”
Scaling Retrieval-Based LLMs with a Trillion-Token Datastore
Using external data via retrieval methods (such as RAG) helps improve the performance of LLMs through better factuality, reducing hallucinations, etc.
The paper Scaling Retrieval-Based Language Models with a Trillion-Token Datastore considers the trade-off between datastore data used in retrieval and number of LLM parameters, and how scaling the data available at inference time improves performance.

To study this question, they built an open-source 1.4 trillion-token datastore used for retrieval called MassiveDS, and analyzed the effects of scaling the store versus other methods of scaling:
We find that increasing the size of the datastore used by a retrieval-based LM monotonically improves language modeling and several downstream tasks without obvious saturation, such that a smaller model augmented with a large datastore outperforms a larger LM-only model on knowledge-intensive tasks. By plotting compute-optimal scaling curves with varied datastore, model, and pretraining data sizes, we show that using larger datastores can significantly improve model performance for the same training compute budget.

They evaluate other factors and features such as improving the retriever, datastore quality filtering, etc. to determine best design choices and tradeoffs. The results show that datastores are more efficient method of addressing knowledge-based queries, and that datastore size is an important factor to consider in optimizing the LLM performance.
They share their open-source MassiveDS datastore and code on GitHub.
Qwen2 Technical Report
Qwen2 is a suite of open AI models from the Alibaba Qwen team released in early June. Qwen2 model sizes range from 0.5 to 72 billion parameters: Qwen2-0.5B, Qwen2-1.5B, Qwen2-7B, Qwen2-57B-A14B (mixture-of-experts), and Qwen2-72B. Qwen2 are very good AI models with the Qwen2-72B in particular showing SOTA performance for open LLMs across several benchmarks: 84.2 on MMLU, 37.9 on GPQA, 64.6 on HumanEval, 89.5 on GSM8K, and 82.4 on BBH as a base language model.
Now the Qwen team has released The Qwen2 Technical Report to share further details on the Qwen2 architecture, training, and evaluation results.
Qwen2 1.5B, 7B and 72B were trained on 7 trillion tokens. While they didn’t share specifics of the dataset used for pre-training Qwen2, they focused on refining the dataset by filtering out low-quality data, and expanding the data that they used. investigating methods to handle extended context lengths effectively
They employed LLMs and data synthesis techniques to help make instruction datasets for the fine-tuning (SFT) stages of training:
“We have assembled an extensive instruction dataset featuring more than 500,000 examples that cover skills such as instruction following, coding, mathematics, logical reasoning, role-playing, multilingualism, and safety”

While Qwen2 Technical Report doesn’t share all details, this is significantly more than the proprietary LLM providers are sharing at this time, and it’s enough to understand the process used at a high level to train the LLM.
The Qwen2 model weights are available on Hugging Face, and since Qwen 7B is quite capable, its worth downloading and running locally.