


AI Research Roundup 24.08.15
Agent Q, The AI Scientist, OpenResearcher, rStar - mutual reasoning, scaling test-time compute, RAG Foundry, improving RAG-augmented LLMs with self-reasoning.


Introduction
This week’s AI Research roundup focuses on reasoning, RAG, and AI agents:
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery
OpenResearcher: Unleashing AI for Accelerated Scientific Research
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers
Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
RAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented Generation
Improving Retrieval Augmented Language Model with Self-Reasoning
Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents
MultiOn is a startup building AI agents that can autonomously solve real-world tasks. This drives a need for a high level of AI capabilities in autonomous actions, planning, reasoning, acquiring knowledge via search, and balancing exploration and taking action to exploit information on hand.
This led them to develop Agent Q, an AI Agent with Planning & Self Healing Capabilities, and publish their research on it in a white paper “Agent Q: Advanced Reasoning and Learning for Autonomous AI Agents.”
MultiOn’s AI Agent is an Action model agent that interacts with web pages and compute environments to solve problems. To address reasoning for such complex tasks, they combine several (non-unique) ideas that are applied and scaled in a novel way. First, they use Guided Search with MCTS:
This technique autonomously generates data by exploring different actions and web-pages, balancing exploration and exploitation. MCTS expands the action space using high sampling temperatures and diverse prompting, ensuring diverse and optimal trajectory collections.
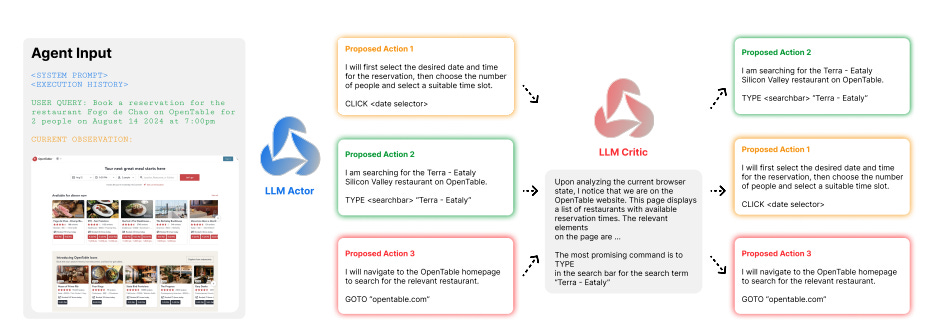
Any small error in MCTS can create an incorrect final agent output. So to improve final results and make credit assignment more useful, they used AI self-critique at each step:
At each step, AI-based self-critique provides valuable feedback, refining the agent's decision-making process. This step-level feedback is crucial for long-horizon tasks, where sparse signals often lead to learning difficulties.
The final component they use to learn from both successful and unsuccessful trajectories is fine-tuning through offline reinforcement learning, using the Direct Preference Optimization (DPO) algorithm, feeding the fine-tuning constructed preference pairs from MCTS-generated data.
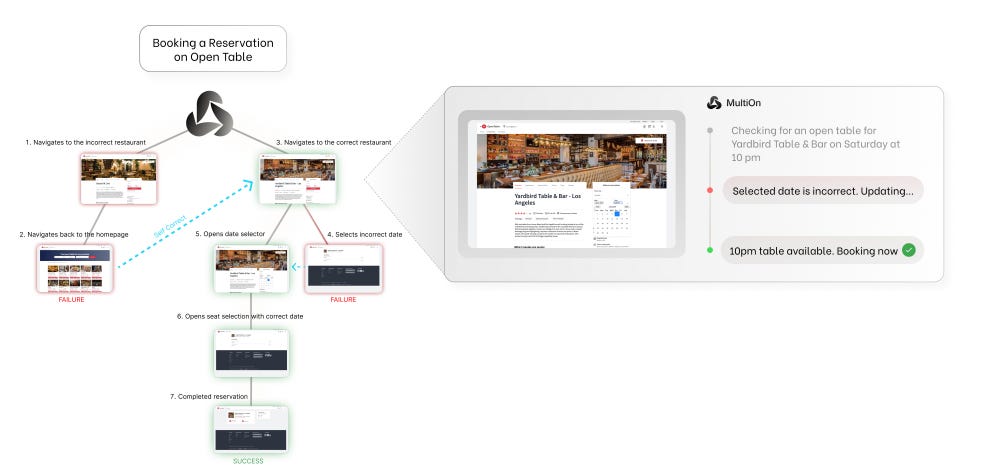
They validated the methods on WebShop tasks, where they beat average human performance, and a booking (OpenTable) task set, where they achieved SOTA results.
Search (with MCTS), AI self-critique, and DPO are familiar methods to improve AI reasoning. What’s new is MultiOn combines and applies them to improve AI action model performance for complex, multi-step reasoning tasks.
We believe this represents a substantial leap forward in the capabilities of autonomous agents, paving the way for more sophisticated and reliable decision-making in real-world settings. - Multi-On
The AI Scientist: Towards Automated Open-Ended Scientific Discovery
The Japanese AI firm Sakana AI has developed and presented the AI Scientist, an AI system for automating scientific research and discovery. They published their research results in the paper “The AI Scientist: Towards Fully Automated Open-Ended Scientific Discovery,” and open-sourced their project on GitHub.
The AI Scientist is an agent built on LLMs with custom prompts that execute each step of the entire research lifecycle: Inventing research ideas, writing code, executing experiments on GPUs, gathering and reporting results, and writing papers.
The AI Scientist has 4 main processes:
1. Idea Generation. Given a starting template of an existing topic, the AI Scientist “brainstorms” a diverse set of novel research directions on that topic. It can search Semantic Scholar to make sure its idea is novel.
2. Experimental Iteration. The AI Scientist proposes and then executes experiments, then produces plots to visualize its results. It implements ideas in code using Aider open-source coding assistant. It saves notes on all experiments, their results, plots, etc., required to write up the paper.
3. Paper Write-up. The AI Scientist turns the results found into a concise and informative write-up in the style of a conference proceeding in LaTeX. It uses Semantic Scholar to autonomously find relevant papers to cite.
4. Automated Paper Reviewing. An automated LLM-powered reviewer, capable of evaluating generated papers with near-human accuracy, generates reviews used to improve the project and as feedback for open-ended ideation. This feedback helps the AI Scientist iteratively improve.

How good is it? The AI Scientist generated research papers that produced novel contributions in Machine Learning research domains such language modeling, Diffusion and Grokking. The AI Scientist uncovered real new insights; positive aspects of written papers included “Precise Mathematical Description of the Algorithm” and “Good Empirical Results.”
Results were imperfect. Problems in one paper included hallucinations, positive interpretations of poor results, and minimal references. They found (as many authors do) that using Claude 3.5 Sonnet yielded the best papers. Overall, they produced papers that would be “weak accept” level results and presentations.

This AI Scientist is baby steps towards the automated AI researcher that Leopold Aschenbrenner said could catapult us quickly to ASI. The most impressive part of this is that it is open source, so available for others to use and improve upon.
OpenResearcher: Unleashing AI for Accelerated Scientific Research
OpenResearcher is an advanced Scientific Research Assistant designed to provide helpful answers to queries on published research. This work is published in the paper “OpenResearcher: Unleashing AI for Accelerated Scientific Research.”
Prior to LLMs, exposing information related to queries was the domain of search engines and information retrieval, but with LLMs, more sophisticated semantic understanding can help researchers get more exact answers to queries more efficiently.
OpenResearcher provides LLMs with current domain-specific knowledge using a Retrieval-Augmented Generation (RAG) system that accesses scientific papers in the arXiv database. OpenResearcher has tools to refine research queries, search for and retrieve scientific references, filter retrieved information, and self-refine answers to queries. It changes tool flow depending on the query for efficiency and effectiveness.
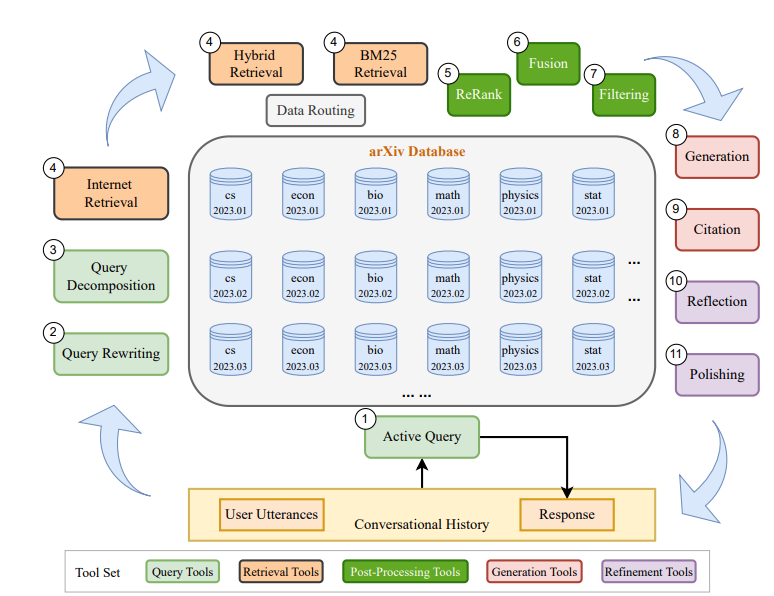
OpenResearcher is an effective knowledge aid for human researchers, supporting query types such as summarization, scientific question answering, paper evaluations and more. Its overall performance was evaluated to be significantly better than naive RAG systems and Perplexity AI, a reflection of the utility of LLM-based refinement tools in the flow. Demo, video, and code are available at this GitHub repo.
Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers
The paper “Mutual Reasoning Makes Smaller LLMs Stronger Problem-Solvers” introduces self-play mutual reasoning, rStar, as a technique to greatly improve reasoning in smaller LLMs.
rStar works by treating reasoning as process of generating then discriminating on candidate steps to determine a reasoning trajectory:
First, a target SLM augments the Monte Carlo Tree Search (MCTS) with a rich set of human-like reasoning actions to construct higher quality reasoning trajectories. Next, another SLM, with capabilities similar to the target SLM, acts as a discriminator to verify each trajectory generated by the target SLM. The mutually agreed reasoning trajectories are considered mutual consistent, thus are more likely to be correct.
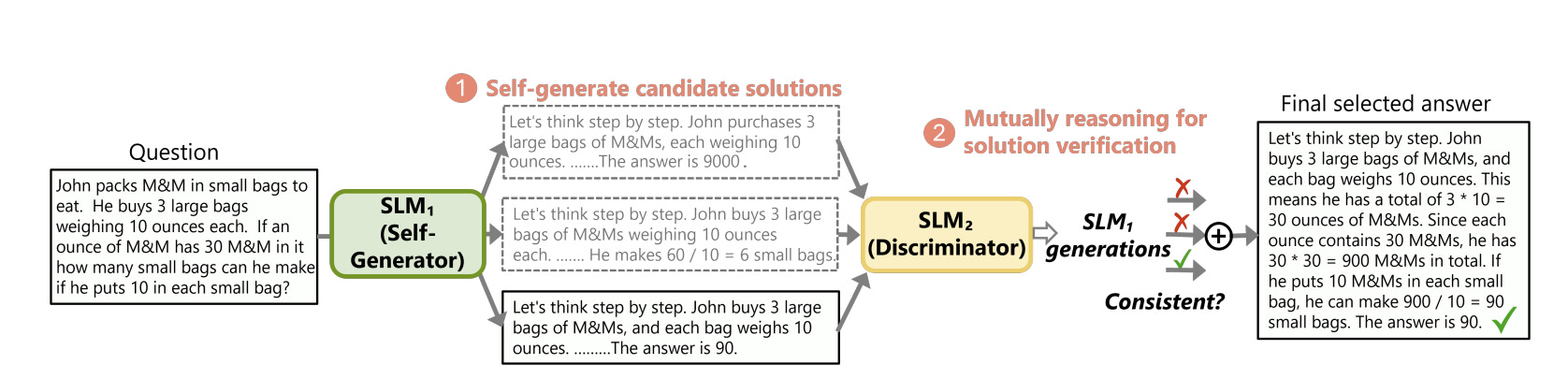
Using MCTS and review of each reasoning step, rStar can solve diverse reasoning problems and achieve state-of-the-art performance on different LLMs. For example, rStar boosts GSM8K accuracy from 12.51% to 63.91% for LLaMA2-7B, far outperforming CoT (chain-of-thought) or ToT (tree-of-thought).

Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters
Researchers at DeepMind asked: How much can more inference-time compute help an LLM improve its performance? They quantified the answer in their paper “Scaling LLM Test-Time Compute Optimally can be More Effective than Scaling Model Parameters.”
They looked at different methods to scale inference-time (test-time) compute: First, they found that Beam Search using dense, process-based reward models (PRMs) was more efficient than best-of-N majority voting. Second, they found efficacy of a given approach correlates with problem difficulty, so they updated the model's distribution over a response adaptively, given the prompt at test time.
Using this compute-optimal strategy, we can improve the efficiency of test-time compute scaling by more than 4x compared to a best-of-N baseline. Additionally, in a FLOPs-matched evaluation, we find that on problems where a smaller base model attains somewhat non-trivial success rates, test-time compute can be used to outperform a 14x larger model.
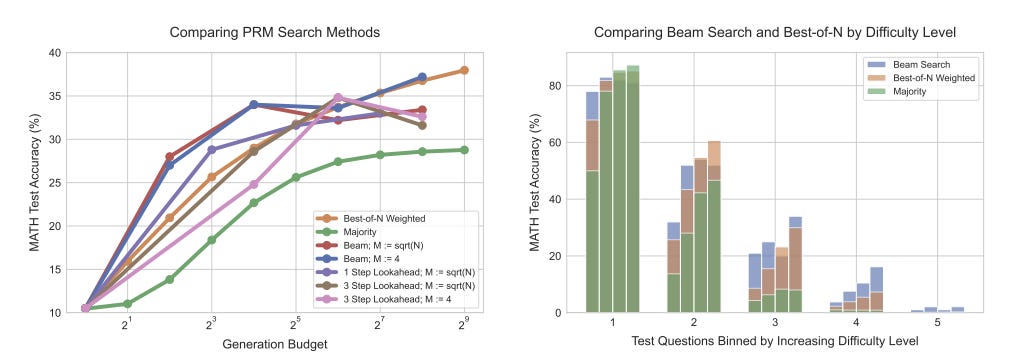
This research helps quantify the benefits of test-time compute effort, and it can be used to determine best trade offs between inference-time and training-time compute.
Improving Retrieval Augmented Language Model with Self-Reasoning
The Retrieval-Augmented Language Model (RALM) uses Retrieval Augmented Generation (RAG) to inform LLMs in inference. The paper “Improving Retrieval Augmented Language Model with Self-Reasoning” looks to improve reliability and traceability in the RALM knowledge retrieval process with a self-reasoning process.
The ‘self-reasoning’ process has the LLM reason over retrieved information to determine its accuracy and relevance:
[The] core idea is to leverage reasoning trajectories generated by the LLM itself. The framework involves constructing self-reason trajectories with three processes: a relevance-aware process, an evidence-aware selective process, and a trajectory analysis process.

They evaluated the self-reasoning method on several knowledge-related datasets (two short-form QA datasets, one long-form QA dataset, and one fact verification dataset), demonstrating superior performance over baseline RAG methods.
RAG Foundry: Enhancing LLMs for Retrieval Augmented Generation
The open-source framework RAG Foundry helps setup LLMs for RAG development and use. It is presented in the paper “RAG Foundry: A Framework for Enhancing LLMs for Retrieval Augmented Generation.”
RAG Foundry integrates data creation, training, inference and evaluation into a single workflow, facilitating the creation of data-augmented datasets for training and evaluating large language models in RAG settings.
This framework helps AI developers experiment with RAG settings and configurations and train RAG-enabled AI models. The open-source RAG Foundry code is available on GitHub.
As the previous papers on OpenResearcher and self-reasoning over retrieval-augmented LLMs show, there are ways to make RAG better through more refinement and reasoning. RAG frameworks will prove helpful as AI researchers further experiment with and improve on RAG methods.