
AI Research Roundup 24.08.22 - Multi-modality
TWLV-I, VITA, Transfusion, JPEG-LM, xGen-MM (BLIP-3), Imagen 3


Introduction
This week’s AI research roundup covers multi-modal models, video foundation models (VFMs), and image generation models:
TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models
VITA: Towards Open-Source Interactive Omni Multimodal LLM
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
JPEG-LM: LLMs as Image Generators with Canonical Codec Representations
xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
Imagen 3
TWLV-I: Analysis and Insights from Evaluation on Video Foundation Models
Video is everyone’s first language. From the moment humans are born, they learn about the world by seeing videos even before using language. Therefore, similar to human languages, developing a video understanding system is essential to achieve the ability to perceive the world accurately. - TWLV-I paper
Video Foundation Models (VFMs) are designed to comprehend video and respond to general queries over video, analogous to how LLMs can do the same regarding text. In the paper “TWLV-I: Analysis and Insights from Holistic Evaluation on Video Foundation Models”, researchers from the video AI startup Twelve Labs presents a framework for evaluating VFMs fairly, and then follows it up with introducing a new Video Foundation Model, TWLV-I.
Video can be viewed as a sequence of images, so the two main categories of video understanding are understanding the appearance of objects in data and understanding motion of objects in time. Some VFMs encode video frame-by-frame then distill that information, e.g., using CLIP; another approach, such as used in Meta’s V-JEPA, is to mask video and predict masked information and frames. They observe:
distillation-based methods such as UMT and InternVideo2 struggle with motion-sensitive benchmarks … masked modeling-based methods (e.g., V-JEPA) underperform on appearance-centric benchmarks …
TWLV-I provides an embedding vector for a video “capturing both appearance and motion,” enabling it to perform well on both appearance and motion video comprehension metrics:
TWLV-I achieves state-of-the-art performance on various video-centric tasks such as temporal action localization, spatiotemporal action localization, and temporal action segmentation, showing its strong spatial and temporal understanding capabilities.
Their evaluations across a range of benchmarks show the TWLV-I model is more broadly capable than other VFMs, including V-JEPA, UMT, and Internvideo2.

Twelve Labs open-sourced their evaluation framework source code on Github. The Twelve Labs video embedding API that generates embeddings from video content, is not open source but commercially available. This can be used in RAG applications and video understanding applications such as video semantic search.
Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model
We show it is possible to fully integrate both modalities, with no information loss, by training a single model to both predict discrete text tokens and diffuse continuous images. - Transfusion paper
Out of Meta research comes Transfusion: Predict the Next Token and Diffuse Images with One Multi-Modal Model. Transfusion mixes transformer’s next-token prediction and diffusion structures in a singular combined architecture to train a single multi-modal model over both discrete and continuous data.
They implemented a 7B Transfusion model, pretraining it by using a mixture of text and image data, a total of 2T multi-modal tokens. Discrete (text) tokens were trained on the next token prediction; image vectors are trained on the diffusion objective; BOI and EOI tokens separate the modalities.
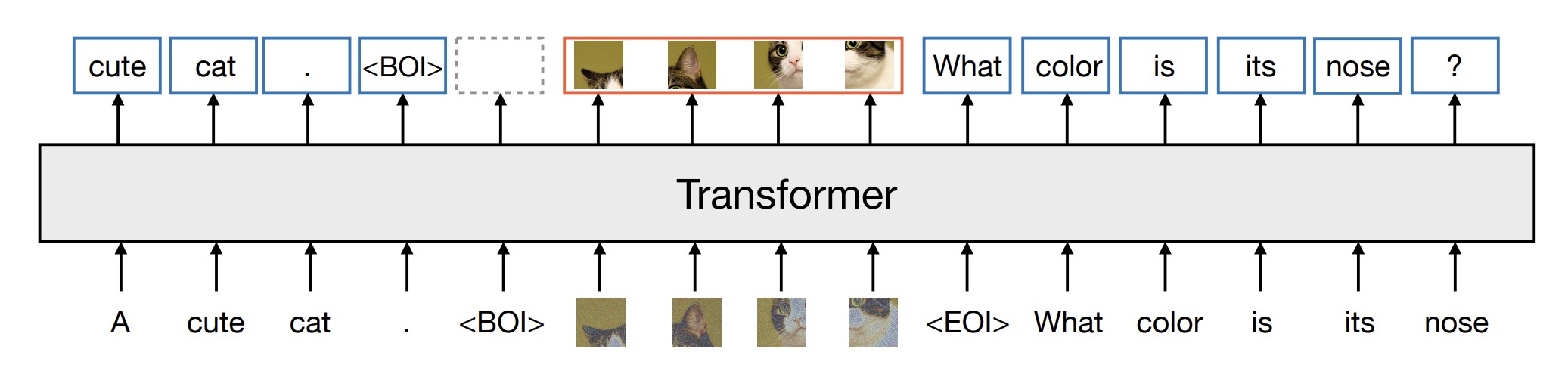
Remarkably, the dual objective training works for each modality without degrading the other.
They compared Transfusion with the Chameleon multi-modal model, demonstrating Transfusion architecture “scales significantly better than quantizing images and training a language model over discrete image tokens.” Further, they found that:
[Transfusion] produces a model that can generate images and text on a par with similar scale diffusion models and language models, reaping the benefits of both worlds.

JPEG-LM: LLMs as Image Generators with Canonical Codec Representations
Generating images out of the autoregressive LLM architecture is appealing due to its generality integration but faces the challenges of how to discretize images and video data. Raw pixels are lengthy, but other methods require “convoluted pre-hoc training.”
The paper “JPEG-LM: LLMs as Image Generators with Canonical Codec Representations” proposes to address this by directly model images and videos as compressed files saved on computers via canonical codecs (e.g., JPEG, AVC/H.264):
Using the default Llama architecture (7B Llama-2 model), we pretrain JPEG-LM from scratch to generate images (and AVC-LM to generate videos as a proof of concept), by directly outputting compressed file bytes in JPEG and AVC formats.
The dataset used was 23M 256x256 images, with each image approximately 5K JPEG tokens, there was a total of 114B JPEG tokens to train JPEG-LM.
Results show JPEG-LM is more effective than pixel-based modeling and sophisticated vector quantization methods, with 31% reduced FID. (FID, or Fréchet Inception Distance, is a metric of image quality, where lower is better.) JPEG-LM also has better rendering of meaningful and ‘long-tail’ visual elements:
JPEG-LM and VQ transformers can both be interpreted as first performing compression and then autoregressive modeling. ... VQ suffers in small but highly perceptible elements in the images, like human faces or eyes. … the image degradation due to the non-neural, training-free JPEG compression happens in a predictable manner, arguably more preferrable, especially when images contain long-tail elements with important meanings.
Thus, JPEG representations can be a superior compression method for images and video in multi-modal LLMs.

VITA: Open-Source Interactive Omni Multimodal LLM
Motivated by the multi-modal capabilities of GPT-4o, Chinese researchers present the Multimodal Large Language Model (MLLM) VITA in the paper “VITA: Towards Open-Source Interactive Omni Multimodal LLM.”
VITA is the first open-source omni-modal model, capable of processing video, image, text, and audio, and also capable of full audio interactivity, including responding to interruptions.

To build VITA, they started with Mixtral 8x7B sparse mixture of experts (SMoE) model and trained it further for bilingual (Chinese and English) comprehension. Then they aligned visual input using a frozen visual encoder (InternViT-300M-448px) and training an MLP connector. Similarly, audio input was aligned by training an audio encoder and MLP connector. Finally, multi-modal instruction-tuning was performed on VITA.

The resulting VITA multi-modal model has robust unimodal and multi-modal capabilities, with visual understanding benchmarks comparable to Gemini 1.5 Pro. They also introduced non-awakening interaction and audio interrupt features in VITA, a first for any open-source MLLM.
While it is not competitive with GPT-4o as a full frontier omni-modal model, VITA is a good step forward for open-source MLLMs. The VITA Project Page is here.

xGen-MM (BLIP-3): A Family of Open Large Multimodal Models
The paper “xGen-MM (BLIP-3): A Family of Open Large Multimodal Models” from Salesforce AI Research presents xGen-MM (BLIP-3), their latest generation of open-source Large Multimodal Model (LMM) training framework and resulting LMM suite. xGen-MM stands for xGen-MultiModal.
In the framework, datasets of captioned images with text are input, with each modality undergoing a separate tokenization process; then this is fed into the LLM, where standard auto-regressive loss is then applied to the text tokens. The framework’s training datasets include captioned images, images with location information, and images with OCR information, all helpful to connect image and text representations.

Using this framework, they build LMMs around the Phi3-mini (4B) LLM that was further trained using xGen-MM framework. They produced both base LMMs and instruction-tuned LMMs, and evaluated them thoroughly:
Our pre-trained base model exhibits strong in-context learning capabilities and the instruction-tuned model demonstrates competitive performance among open-source LMMs with similar model sizes.
They have shared their xGen-MM-Phi3-mini open models on HuggingFace. The datasets have been “meticulously curated”, and will be shared as open-source along with training recipe and code on their project page.
Imagen 3
Imagen 3 is Google’s third generation of their latent diffusion model for AI image generation. Google just published the Imagen 3 Technical Report in conjunction with making Imagen 3 general availability, sharing evaluation results and benchmarks.
In evaluations, Imagen 3 was compared against MidJourney 6, Dalle-3, and StableDiffusion 3. Their report states, “Imagen 3 is preferred over other state-of-the-art (SOTA) models at the time of evaluation.”
Despite the Imagen 2 “diversity” fiasco earlier this year of generating black Nazis and female Popes, Google continues to “pay particular attention to the distribution of the appearances of people,” by aiming to adjust skin tone and gender in image outputs as a matter of “fairness”.
However, neither fairness nor benchmarks that will be the ultimate judge of AI image generation model quality; users will decide. While Imagen 3 is excellent, so are strong AI models like MidJourney (now with an open website) as well as newly released models like FLUX.1 and Ideogram 2.0.
You can try Imagen 3 in Google’s AI Test kitchen.
